 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMHU: A Massive-Scale Multimodal Benchmark for Human Behavior Understanding
Jul 16, 2025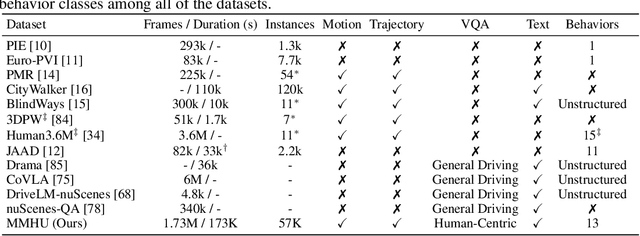



Humans are integral components of the transportation ecosystem, and understanding their behaviors is crucial to facilitating the development of safe driving systems. Although recent progress has explored various aspects of human behavior$\unicode{x2014}$such as motion, trajectories, and intention$\unicode{x2014}$a comprehensive benchmark for evaluating human behavior understanding in autonomous driving remains unavailable. In this work, we propose $\textbf{MMHU}$, a large-scale benchmark for human behavior analysis featuring rich annotations, such as human motion and trajectories, text description for human motions, human intention, and critical behavior labels relevant to driving safety. Our dataset encompasses 57k human motion clips and 1.73M frames gathered from diverse sources, including established driving datasets such as Waymo, in-the-wild videos from YouTube, and self-collected data. A human-in-the-loop annotation pipeline is developed to generate rich behavior captions. We provide a thorough dataset analysis and benchmark multiple tasks$\unicode{x2014}$ranging from motion prediction to motion generation and human behavior question answering$\unicode{x2014}$thereby offering a broad evaluation suite. Project page : https://MMHU-Benchmark.github.io.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
May 26, 2025The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
Cross-Modal Consistency Learning for Sign Language Recognition
Mar 16, 2025Pre-training has been proven to be effective in boosting the performance of Isolated Sign Language Recognition (ISLR). Existing pre-training methods solely focus on the compact pose data, which eliminate background perturbation but inevitably suffer from insufficient semantic cues compared to raw RGB videos. Nevertheless, direct representation learning only from RGB videos remains challenging due to the presence of sign-independent visual features. To address this dilemma, we propose a Cross-modal Consistency Learning framework (CCL-SLR), which leverages the cross-modal consistency from both RGB and pose modalities based on self-supervised pre-training. First, CCL-SLR employs contrastive learning for instance discrimination within and across modalities. Through the single-modal and cross-modal contrastive learning, CCL-SLR gradually aligns the feature spaces of RGB and pose modalities, thereby extracting consistent sign representations. Second, we further introduce Motion-Preserving Masking (MPM) and Semantic Positive Mining (SPM) techniques to improve cross-modal consistency from the perspective of data augmentation and sample similarity, respectively. Extensive experiments on four ISLR benchmarks show that CCL-SLR achieves impressive performance, demonstrating its effectiveness. The code will be released to the public.
Uni-Sign: Toward Unified Sign Language Understanding at Scale
Jan 25, 2025



Sign language pre-training has gained increasing attention for its ability to enhance performance across various sign language understanding (SLU) tasks. However, existing methods often suffer from a gap between pre-training and fine-tuning, leading to suboptimal results. To address this, we propose \modelname, a unified pre-training framework that eliminates the gap between pre-training and downstream SLU tasks through a large-scale generative pre-training strategy and a novel fine-tuning paradigm. First, we introduce CSL-News, a large-scale Chinese Sign Language (CSL) dataset containing 1,985 hours of video paired with textual annotations, which enables effective large-scale pre-training. Second, \modelname unifies SLU tasks by treating downstream tasks as a single sign language translation (SLT) task during fine-tuning, ensuring seamless knowledge transfer between pre-training and fine-tuning. Furthermore, we incorporate a prior-guided fusion (PGF) module and a score-aware sampling strategy to efficiently fuse pose and RGB information, addressing keypoint inaccuracies and improving computational efficiency. Extensive experiments across multiple SLU benchmarks demonstrate that \modelname achieves state-of-the-art performance across multiple downstream SLU tasks. Dataset and code are available at \url{github.com/ZechengLi19/Uni-Sign}.
Scaling up Multimodal Pre-training for Sign Language Understanding
Aug 16, 2024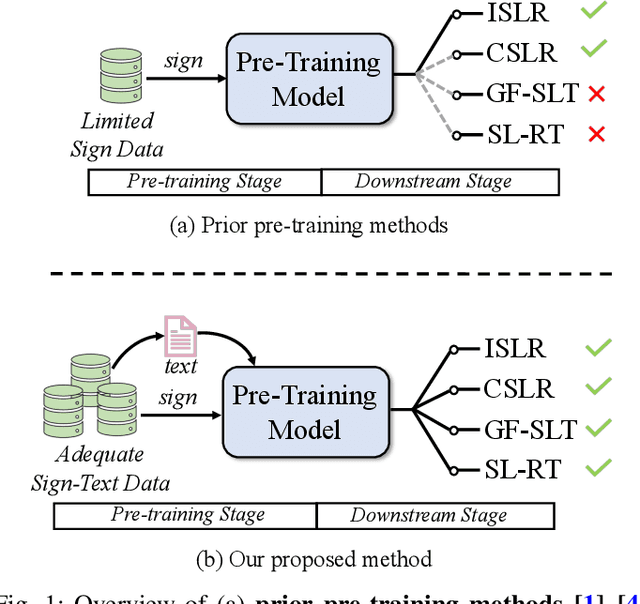



Sign language serves as the primary meaning of communication for the deaf-mute community. Different from spoken language, it commonly conveys information by the collaboration of manual features, i.e., hand gestures and body movements, and non-manual features, i.e., facial expressions and mouth cues. To facilitate communication between the deaf-mute and hearing people, a series of sign language understanding (SLU) tasks have been studied in recent years, including isolated/continuous sign language recognition (ISLR/CSLR), gloss-free sign language translation (GF-SLT) and sign language retrieval (SL-RT). Sign language recognition and translation aims to understand the semantic meaning conveyed by sign languages from gloss-level and sentence-level, respectively. In contrast, SL-RT focuses on retrieving sign videos or corresponding texts from a closed-set under the query-by-example search paradigm. These tasks investigate sign language topics from diverse perspectives and raise challenges in learning effective representation of sign language videos. To advance the development of sign language understanding, exploring a generalized model that is applicable across various SLU tasks is a profound research direction.
Expressive Gaussian Human Avatars from Monocular RGB Video
Jul 03, 2024



Nuanced expressiveness, particularly through fine-grained hand and facial expressions, is pivotal for enhancing the realism and vitality of digital human representations. In this work, we focus on investigating the expressiveness of human avatars when learned from monocular RGB video; a setting that introduces new challenges in capturing and animating fine-grained details. To this end, we introduce EVA, a drivable human model that meticulously sculpts fine details based on 3D Gaussians and SMPL-X, an expressive parametric human model. Focused on enhancing expressiveness, our work makes three key contributions. First, we highlight the critical importance of aligning the SMPL-X model with RGB frames for effective avatar learning. Recognizing the limitations of current SMPL-X prediction methods for in-the-wild videos, we introduce a plug-and-play module that significantly ameliorates misalignment issues. Second, we propose a context-aware adaptive density control strategy, which is adaptively adjusting the gradient thresholds to accommodate the varied granularity across body parts. Last but not least, we develop a feedback mechanism that predicts per-pixel confidence to better guide the learning of 3D Gaussians. Extensive experiments on two benchmarks demonstrate the superiority of our framework both quantitatively and qualitatively, especially on the fine-grained hand and facial details. See the project website at \url{https://evahuman.github.io}
MASA: Motion-aware Masked Autoencoder with Semantic Alignment for Sign Language Recognition
May 31, 2024



Sign language recognition (SLR) has long been plagued by insufficient model representation capabilities. Although current pre-training approaches have alleviated this dilemma to some extent and yielded promising performance by employing various pretext tasks on sign pose data, these methods still suffer from two primary limitations: 1) Explicit motion information is usually disregarded in previous pretext tasks, leading to partial information loss and limited representation capability. 2) Previous methods focus on the local context of a sign pose sequence, without incorporating the guidance of the global meaning of lexical signs. To this end, we propose a Motion-Aware masked autoencoder with Semantic Alignment (MASA) that integrates rich motion cues and global semantic information in a self-supervised learning paradigm for SLR. Our framework contains two crucial components, i.e., a motion-aware masked autoencoder (MA) and a momentum semantic alignment module (SA). Specifically, in MA, we introduce an autoencoder architecture with a motion-aware masked strategy to reconstruct motion residuals of masked frames, thereby explicitly exploring dynamic motion cues among sign pose sequences. Moreover, in SA, we embed our framework with global semantic awareness by aligning the embeddings of different augmented samples from the input sequence in the shared latent space. In this way, our framework can simultaneously learn local motion cues and global semantic features for comprehensive sign language representation. Furthermore, we conduct extensive experiments to validate the effectiveness of our method, achieving new state-of-the-art performance on four public benchmarks.
Comp4D: LLM-Guided Compositional 4D Scene Generation
Mar 25, 2024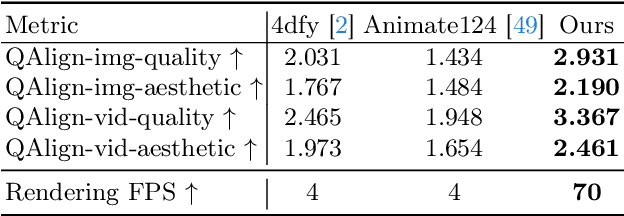
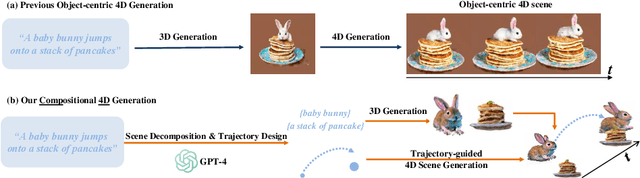

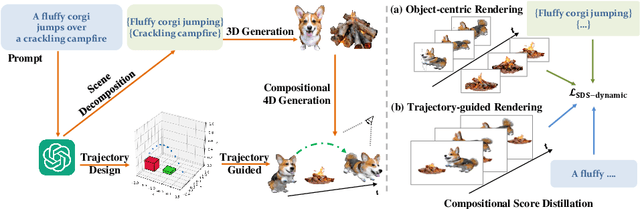
Recent advancements in diffusion models for 2D and 3D content creation have sparked a surge of interest in generating 4D content. However, the scarcity of 3D scene datasets constrains current methodologies to primarily object-centric generation. To overcome this limitation, we present Comp4D, a novel framework for Compositional 4D Generation. Unlike conventional methods that generate a singular 4D representation of the entire scene, Comp4D innovatively constructs each 4D object within the scene separately. Utilizing Large Language Models (LLMs), the framework begins by decomposing an input text prompt into distinct entities and maps out their trajectories. It then constructs the compositional 4D scene by accurately positioning these objects along their designated paths. To refine the scene, our method employs a compositional score distillation technique guided by the pre-defined trajectories, utilizing pre-trained diffusion models across text-to-image, text-to-video, and text-to-3D domains. Extensive experiments demonstrate our outstanding 4D content creation capability compared to prior arts, showcasing superior visual quality, motion fidelity, and enhanced object interactions.
PersonMAE: Person Re-Identification Pre-Training with Masked AutoEncoders
Nov 08, 2023Pre-training is playing an increasingly important role in learning generic feature representation for Person Re-identification (ReID). We argue that a high-quality ReID representation should have three properties, namely, multi-level awareness, occlusion robustness, and cross-region invariance. To this end, we propose a simple yet effective pre-training framework, namely PersonMAE, which involves two core designs into masked autoencoders to better serve the task of Person Re-ID. 1) PersonMAE generates two regions from the given image with RegionA as the input and \textit{RegionB} as the prediction target. RegionA is corrupted with block-wise masking to mimic common occlusion in ReID and its remaining visible parts are fed into the encoder. 2) Then PersonMAE aims to predict the whole RegionB at both pixel level and semantic feature level. It encourages its pre-trained feature representations with the three properties mentioned above. These properties make PersonMAE compatible with downstream Person ReID tasks, leading to state-of-the-art performance on four downstream ReID tasks, i.e., supervised (holistic and occluded setting), and unsupervised (UDA and USL setting). Notably, on the commonly adopted supervised setting, PersonMAE with ViT-B backbone achieves 79.8% and 69.5% mAP on the MSMT17 and OccDuke datasets, surpassing the previous state-of-the-art by a large margin of +8.0 mAP, and +5.3 mAP, respectively.
Sign Language Translation with Iterative Prototype
Aug 23, 2023This paper presents IP-SLT, a simple yet effective framework for sign language translation (SLT). Our IP-SLT adopts a recurrent structure and enhances the semantic representation (prototype) of the input sign language video via an iterative refinement manner. Our idea mimics the behavior of human reading, where a sentence can be digested repeatedly, till reaching accurate understanding. Technically, IP-SLT consists of feature extraction, prototype initialization, and iterative prototype refinement. The initialization module generates the initial prototype based on the visual feature extracted by the feature extraction module. Then, the iterative refinement module leverages the cross-attention mechanism to polish the previous prototype by aggregating it with the original video feature. Through repeated refinement, the prototype finally converges to a more stable and accurate state, leading to a fluent and appropriate translation. In addition, to leverage the sequential dependence of prototypes, we further propose an iterative distillation loss to compress the knowledge of the final iteration into previous ones. As the autoregressive decoding process is executed only once in inference, our IP-SLT is ready to improve various SLT systems with acceptable overhead. Extensive experiments are conducted on public benchmarks to demonstrate the effectiveness of the IP-SLT.