 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Semantic Alignment and Affinity-Guided Fusion for Structured Radar Point Cloud Generation
Jun 25, 2026Point clouds are an important carrier of three-dimensional spatial information, and their quality directly affects the performance of downstream perception tasks such as object detection and tracking. However, millimeter-wave radar point clouds are typically sparse, noisy, and structurally incomplete. To address these limitations, this paper proposes a multimodal point cloud generation method based on vision-radar fusion. The proposed method leverages image semantic information to impose structural constraints and achieve spatial alignment for radar point clouds, while incorporating a sparse completion strategy to enhance point density and recover missing structures. The generated point clouds are further evaluated in object detection and tracking tasks. Experimental results demonstrate that the proposed method effectively improves point cloud quality and enhances the detection accuracy and robustness of perception models in complex environments, providing a practical solution for multisensor point cloud generation and intelligent perception systems.
Internalizing Meta-Experience into Memory for Guided Reinforcement Learning in Large Language Models
Feb 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an effective approach for enhancing the reasoning capabilities of Large Language Models (LLMs). Despite its efficacy, RLVR faces a meta-learning bottleneck: it lacks mechanisms for error attribution and experience internalization intrinsic to the human learning cycle beyond practice and verification, thereby limiting fine-grained credit assignment and reusable knowledge formation. We term such reusable knowledge representations derived from past errors as meta-experience. Based on this insight, we propose Meta-Experience Learning (MEL), a novel framework that incorporates self-distilled meta-experience into the model's parametric memory. Building upon standard RLVR, we introduce an additional design that leverages the LLM's self-verification capability to conduct contrastive analysis on paired correct and incorrect trajectories, identify the precise bifurcation points where reasoning errors arise, and summarize them into generalizable meta-experience. The meta-experience is further internalized into the LLM's parametric memory by minimizing the negative log-likelihood, which induces a language-modeled reward signal that bridges correct and incorrect reasoning trajectories and facilitates effective knowledge reuse. Experimental results demonstrate that MEL achieves consistent improvements on benchmarks, yielding 3.92%--4.73% Pass@1 gains across varying model sizes.
MagicGUI-RMS: A Multi-Agent Reward Model System for Self-Evolving GUI Agents via Automated Feedback Reflux
Jan 19, 2026Graphical user interface (GUI) agents are rapidly progressing toward autonomous interaction and reliable task execution across diverse applications. However, two central challenges remain unresolved: automating the evaluation of agent trajectories and generating high-quality training data at scale to enable continual improvement. Existing approaches often depend on manual annotation or static rule-based verification, which restricts scalability and limits adaptability in dynamic environments. We present MagicGUI-RMS, a multi-agent reward model system that delivers adaptive trajectory evaluation, corrective feedback, and self-evolving learning capabilities. MagicGUI-RMS integrates a Domain-Specific Reward Model (DS-RM) with a General-Purpose Reward Model (GP-RM), enabling fine-grained action assessment and robust generalization across heterogeneous GUI tasks. To support reward learning at scale, we design a structured data construction pipeline that automatically produces balanced and diverse reward datasets, effectively reducing annotation costs while maintaining sample fidelity. During execution, the reward model system identifies erroneous actions, proposes refined alternatives, and continuously enhances agent behavior through an automated data-reflux mechanism. Extensive experiments demonstrate that MagicGUI-RMS yields substantial gains in task accuracy, behavioral robustness. These results establish MagicGUI-RMS as a principled and effective foundation for building self-improving GUI agents driven by reward-based adaptation.
From Evidence-Based Medicine to Knowledge Graph: Retrieval-Augmented Generation for Sports Rehabilitation and a Domain Benchmark
Jan 01, 2026In medicine, large language models (LLMs) increasingly rely on retrieval-augmented generation (RAG) to ground outputs in up-to-date external evidence. However, current RAG approaches focus primarily on performance improvements while overlooking evidence-based medicine (EBM) principles. This study addresses two key gaps: (1) the lack of PICO alignment between queries and retrieved evidence, and (2) the absence of evidence hierarchy considerations during reranking. We present a generalizable strategy for adapting EBM to graph-based RAG, integrating the PICO framework into knowledge graph construction and retrieval, and proposing a Bayesian-inspired reranking algorithm to calibrate ranking scores by evidence grade without introducing predefined weights. We validated this framework in sports rehabilitation, a literature-rich domain currently lacking RAG systems and benchmarks. We released a knowledge graph (357,844 nodes and 371,226 edges) and a reusable benchmark of 1,637 QA pairs. The system achieved 0.830 nugget coverage, 0.819 answer faithfulness, 0.882 semantic similarity, and 0.788 PICOT match accuracy. In a 5-point Likert evaluation, five expert clinicians rated the system 4.66-4.84 across factual accuracy, faithfulness, relevance, safety, and PICO alignment. These findings demonstrate that the proposed EBM adaptation strategy improves retrieval and answer quality and is transferable to other clinical domains. The released resources also help address the scarcity of RAG datasets in sports rehabilitation.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
Apr 15, 2025Current multimodal benchmarks often conflate reasoning with domain-specific knowledge, making it difficult to isolate and evaluate general reasoning abilities in non-expert settings. To address this, we introduce VisualPuzzles, a benchmark that targets visual reasoning while deliberately minimizing reliance on specialized knowledge. VisualPuzzles consists of diverse questions spanning five categories: algorithmic, analogical, deductive, inductive, and spatial reasoning. One major source of our questions is manually translated logical reasoning questions from the Chinese Civil Service Examination. Experiments show that VisualPuzzles requires significantly less intensive domain-specific knowledge and more complex reasoning compared to benchmarks like MMMU, enabling us to better evaluate genuine multimodal reasoning. Evaluations show that state-of-the-art multimodal large language models consistently lag behind human performance on VisualPuzzles, and that strong performance on knowledge-intensive benchmarks does not necessarily translate to success on reasoning-focused, knowledge-light tasks. Additionally, reasoning enhancements such as scaling up inference compute (with "thinking" modes) yield inconsistent gains across models and task types, and we observe no clear correlation between model size and performance. We also found that models exhibit different reasoning and answering patterns on VisualPuzzles compared to benchmarks with heavier emphasis on knowledge. VisualPuzzles offers a clearer lens through which to evaluate reasoning capabilities beyond factual recall and domain knowledge.
Cross-Modal Consistency Learning for Sign Language Recognition
Mar 16, 2025Pre-training has been proven to be effective in boosting the performance of Isolated Sign Language Recognition (ISLR). Existing pre-training methods solely focus on the compact pose data, which eliminate background perturbation but inevitably suffer from insufficient semantic cues compared to raw RGB videos. Nevertheless, direct representation learning only from RGB videos remains challenging due to the presence of sign-independent visual features. To address this dilemma, we propose a Cross-modal Consistency Learning framework (CCL-SLR), which leverages the cross-modal consistency from both RGB and pose modalities based on self-supervised pre-training. First, CCL-SLR employs contrastive learning for instance discrimination within and across modalities. Through the single-modal and cross-modal contrastive learning, CCL-SLR gradually aligns the feature spaces of RGB and pose modalities, thereby extracting consistent sign representations. Second, we further introduce Motion-Preserving Masking (MPM) and Semantic Positive Mining (SPM) techniques to improve cross-modal consistency from the perspective of data augmentation and sample similarity, respectively. Extensive experiments on four ISLR benchmarks show that CCL-SLR achieves impressive performance, demonstrating its effectiveness. The code will be released to the public.
Uni-Sign: Toward Unified Sign Language Understanding at Scale
Jan 25, 2025



Sign language pre-training has gained increasing attention for its ability to enhance performance across various sign language understanding (SLU) tasks. However, existing methods often suffer from a gap between pre-training and fine-tuning, leading to suboptimal results. To address this, we propose \modelname, a unified pre-training framework that eliminates the gap between pre-training and downstream SLU tasks through a large-scale generative pre-training strategy and a novel fine-tuning paradigm. First, we introduce CSL-News, a large-scale Chinese Sign Language (CSL) dataset containing 1,985 hours of video paired with textual annotations, which enables effective large-scale pre-training. Second, \modelname unifies SLU tasks by treating downstream tasks as a single sign language translation (SLT) task during fine-tuning, ensuring seamless knowledge transfer between pre-training and fine-tuning. Furthermore, we incorporate a prior-guided fusion (PGF) module and a score-aware sampling strategy to efficiently fuse pose and RGB information, addressing keypoint inaccuracies and improving computational efficiency. Extensive experiments across multiple SLU benchmarks demonstrate that \modelname achieves state-of-the-art performance across multiple downstream SLU tasks. Dataset and code are available at \url{github.com/ZechengLi19/Uni-Sign}.
Scaling up Multimodal Pre-training for Sign Language Understanding
Aug 16, 2024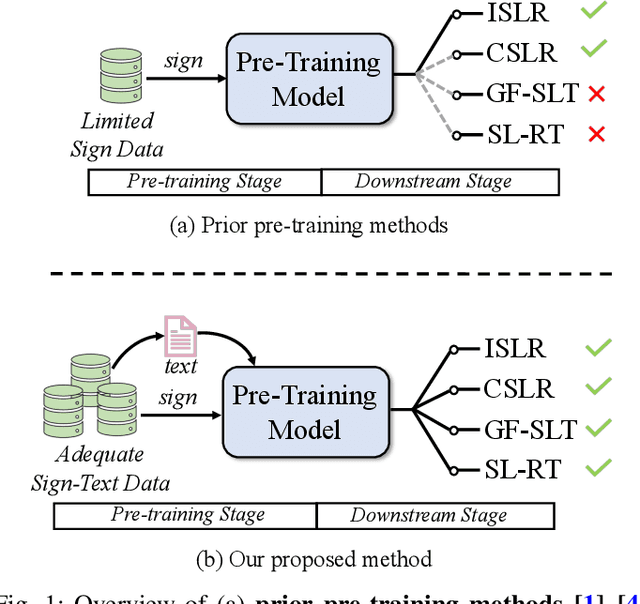



Sign language serves as the primary meaning of communication for the deaf-mute community. Different from spoken language, it commonly conveys information by the collaboration of manual features, i.e., hand gestures and body movements, and non-manual features, i.e., facial expressions and mouth cues. To facilitate communication between the deaf-mute and hearing people, a series of sign language understanding (SLU) tasks have been studied in recent years, including isolated/continuous sign language recognition (ISLR/CSLR), gloss-free sign language translation (GF-SLT) and sign language retrieval (SL-RT). Sign language recognition and translation aims to understand the semantic meaning conveyed by sign languages from gloss-level and sentence-level, respectively. In contrast, SL-RT focuses on retrieving sign videos or corresponding texts from a closed-set under the query-by-example search paradigm. These tasks investigate sign language topics from diverse perspectives and raise challenges in learning effective representation of sign language videos. To advance the development of sign language understanding, exploring a generalized model that is applicable across various SLU tasks is a profound research direction.
SEDS: Semantically Enhanced Dual-Stream Encoder for Sign Language Retrieval
Jul 23, 2024



Different from traditional video retrieval, sign language retrieval is more biased towards understanding the semantic information of human actions contained in video clips. Previous works typically only encode RGB videos to obtain high-level semantic features, resulting in local action details drowned in a large amount of visual information redundancy. Furthermore, existing RGB-based sign retrieval works suffer from the huge memory cost of dense visual data embedding in end-to-end training, and adopt offline RGB encoder instead, leading to suboptimal feature representation. To address these issues, we propose a novel sign language representation framework called Semantically Enhanced Dual-Stream Encoder (SEDS), which integrates Pose and RGB modalities to represent the local and global information of sign language videos. Specifically, the Pose encoder embeds the coordinates of keypoints corresponding to human joints, effectively capturing detailed action features. For better context-aware fusion of two video modalities, we propose a Cross Gloss Attention Fusion (CGAF) module to aggregate the adjacent clip features with similar semantic information from intra-modality and inter-modality. Moreover, a Pose-RGB Fine-grained Matching Objective is developed to enhance the aggregated fusion feature by contextual matching of fine-grained dual-stream features. Besides the offline RGB encoder, the whole framework only contains learnable lightweight networks, which can be trained end-to-end. Extensive experiments demonstrate that our framework significantly outperforms state-of-the-art methods on various datasets.