 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSay Something Else: Rethinking Contextual Privacy as Information Sufficiency
Apr 07, 2026LLM agents increasingly draft messages on behalf of users, yet users routinely overshare sensitive information and disagree on what counts as private. Existing systems support only suppression (omitting sensitive information) and generalization (replacing information with an abstraction), and are typically evaluated on single isolated messages, leaving both the strategy space and evaluation setting incomplete. We formalize privacy-preserving LLM communication as an \textbf{Information Sufficiency (IS)} task, introduce \textbf{free-text pseudonymization} as a third strategy that replaces sensitive attributes with functionally equivalent alternatives, and propose a \textbf{conversational evaluation protocol} that assesses strategies under realistic multi-turn follow-up pressure. Across 792 scenarios spanning three power-relation types (institutional, peer, intimate) and three sensitivity categories (discrimination risk, social cost, boundary), we evaluate seven frontier LLMs on privacy at two granularities, covertness, and utility. Pseudonymization yields the strongest privacy\textendash utility tradeoff overall, and single-message evaluation systematically underestimates leakage, with generalization losing up to 16.3 percentage points of privacy under follow-up.
IndoorR2X: Indoor Robot-to-Everything Coordination with LLM-Driven Planning
Mar 20, 2026Although robot-to-robot (R2R) communication improves indoor scene understanding beyond what a single robot can achieve, R2R alone cannot overcome partial observability without substantial exploration overhead or scaling team size. In contrast, many indoor environments already include low-cost Internet of Things (IoT) sensors (e.g., cameras) that provide persistent, building-wide context beyond onboard perception. We therefore introduce IndoorR2X, the first benchmark and simulation framework for Large Language Model (LLM)-driven multi-robot task planning with Robot-to-Everything (R2X) perception and communication in indoor environments. IndoorR2X integrates observations from mobile robots and static IoT devices to construct a global semantic state that supports scalable scene understanding, reduces redundant exploration, and enables high-level coordination through LLM-based planning. IndoorR2X provides configurable simulation environments, sensor layouts, robot teams, and task suites to systematically evaluate high-level semantic coordination strategies. Extensive experiments across diverse settings demonstrate that IoT-augmented world modeling improves multi-robot efficiency and reliability, and we highlight key insights and failure modes for advancing LLM-based collaboration between robot teams and indoor IoT sensors.
Grounding Multilingual Multimodal LLMs With Cultural Knowledge
Aug 12, 2025Multimodal Large Language Models excel in high-resource settings, but often misinterpret long-tail cultural entities and underperform in low-resource languages. To address this gap, we propose a data-centric approach that directly grounds MLLMs in cultural knowledge. Leveraging a large scale knowledge graph from Wikidata, we collect images that represent culturally significant entities, and generate synthetic multilingual visual question answering data. The resulting dataset, CulturalGround, comprises 22 million high-quality, culturally-rich VQA pairs spanning 42 countries and 39 languages. We train an open-source MLLM CulturalPangea on CulturalGround, interleaving standard multilingual instruction-tuning data to preserve general abilities. CulturalPangea achieves state-of-the-art performance among open models on various culture-focused multilingual multimodal benchmarks, outperforming prior models by an average of 5.0 without degrading results on mainstream vision-language tasks. Our findings show that our targeted, culturally grounded approach could substantially narrow the cultural gap in MLLMs and offer a practical path towards globally inclusive multimodal systems.
Synthetic Socratic Debates: Examining Persona Effects on Moral Decision and Persuasion Dynamics
Jun 14, 2025As large language models (LLMs) are increasingly used in morally sensitive domains, it is crucial to understand how persona traits affect their moral reasoning and persuasive behavior. We present the first large-scale study of multi-dimensional persona effects in AI-AI debates over real-world moral dilemmas. Using a 6-dimensional persona space (age, gender, country, class, ideology, and personality), we simulate structured debates between AI agents over 131 relationship-based cases. Our results show that personas affect initial moral stances and debate outcomes, with political ideology and personality traits exerting the strongest influence. Persuasive success varies across traits, with liberal and open personalities reaching higher consensus and win rates. While logit-based confidence grows during debates, emotional and credibility-based appeals diminish, indicating more tempered argumentation over time. These trends mirror findings from psychology and cultural studies, reinforcing the need for persona-aware evaluation frameworks for AI moral reasoning.
FieldWorkArena: Agentic AI Benchmark for Real Field Work Tasks
May 26, 2025This paper proposes FieldWorkArena, a benchmark for agentic AI targeting real-world field work. With the recent increase in demand for agentic AI, they are required to monitor and report safety and health incidents, as well as manufacturing-related incidents, that may occur in real-world work environments. Existing agentic AI benchmarks have been limited to evaluating web tasks and are insufficient for evaluating agents in real-world work environments, where complexity increases significantly. In this paper, we define a new action space that agentic AI should possess for real world work environment benchmarks and improve the evaluation function from previous methods to assess the performance of agentic AI in diverse real-world tasks. The dataset consists of videos captured on-site and documents actually used in factories and warehouses, and tasks were created based on interviews with on-site workers and managers. Evaluation results confirmed that performance evaluation considering the characteristics of Multimodal LLM (MLLM) such as GPT-4o is feasible. Additionally, the effectiveness and limitations of the proposed new evaluation method were identified. The complete dataset (HuggingFace) and evaluation program (GitHub) can be downloaded from the following website: https://en-documents.research.global.fujitsu.com/fieldworkarena/.
VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
Apr 15, 2025Current multimodal benchmarks often conflate reasoning with domain-specific knowledge, making it difficult to isolate and evaluate general reasoning abilities in non-expert settings. To address this, we introduce VisualPuzzles, a benchmark that targets visual reasoning while deliberately minimizing reliance on specialized knowledge. VisualPuzzles consists of diverse questions spanning five categories: algorithmic, analogical, deductive, inductive, and spatial reasoning. One major source of our questions is manually translated logical reasoning questions from the Chinese Civil Service Examination. Experiments show that VisualPuzzles requires significantly less intensive domain-specific knowledge and more complex reasoning compared to benchmarks like MMMU, enabling us to better evaluate genuine multimodal reasoning. Evaluations show that state-of-the-art multimodal large language models consistently lag behind human performance on VisualPuzzles, and that strong performance on knowledge-intensive benchmarks does not necessarily translate to success on reasoning-focused, knowledge-light tasks. Additionally, reasoning enhancements such as scaling up inference compute (with "thinking" modes) yield inconsistent gains across models and task types, and we observe no clear correlation between model size and performance. We also found that models exhibit different reasoning and answering patterns on VisualPuzzles compared to benchmarks with heavier emphasis on knowledge. VisualPuzzles offers a clearer lens through which to evaluate reasoning capabilities beyond factual recall and domain knowledge.
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Apr 09, 2025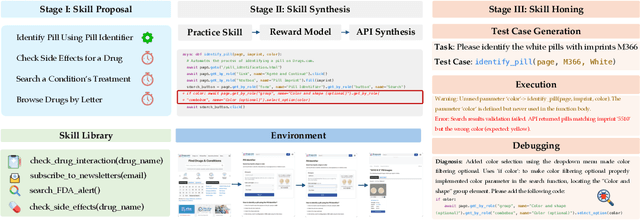
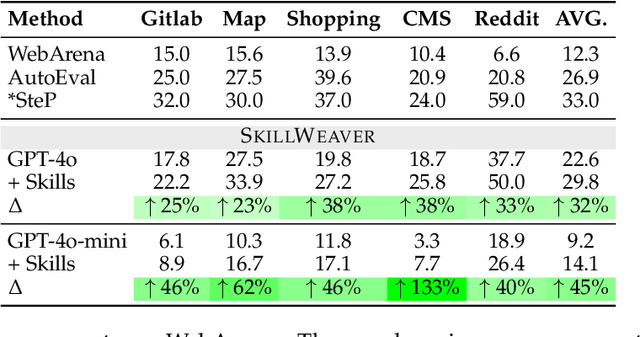

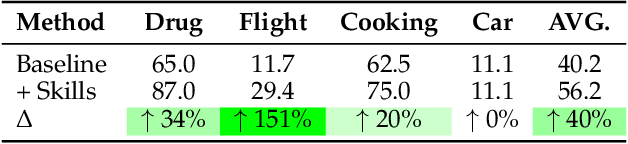
To survive and thrive in complex environments, humans have evolved sophisticated self-improvement mechanisms through environment exploration, hierarchical abstraction of experiences into reuseable skills, and collaborative construction of an ever-growing skill repertoire. Despite recent advancements, autonomous web agents still lack crucial self-improvement capabilities, struggling with procedural knowledge abstraction, refining skills, and skill composition. In this work, we introduce SkillWeaver, a skill-centric framework enabling agents to self-improve by autonomously synthesizing reusable skills as APIs. Given a new website, the agent autonomously discovers skills, executes them for practice, and distills practice experiences into robust APIs. Iterative exploration continually expands a library of lightweight, plug-and-play APIs, significantly enhancing the agent's capabilities. Experiments on WebArena and real-world websites demonstrate the efficacy of SkillWeaver, achieving relative success rate improvements of 31.8% and 39.8%, respectively. Additionally, APIs synthesized by strong agents substantially enhance weaker agents through transferable skills, yielding improvements of up to 54.3% on WebArena. These results demonstrate the effectiveness of honing diverse website interactions into APIs, which can be seamlessly shared among various web agents.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Beyond Browsing: API-Based Web Agents
Oct 21, 2024



Web browsers are a portal to the internet, where much of human activity is undertaken. Thus, there has been significant research work in AI agents that interact with the internet through web browsing. However, there is also another interface designed specifically for machine interaction with online content: application programming interfaces (APIs). In this paper we ask -- what if we were to take tasks traditionally tackled by browsing agents, and give AI agents access to APIs? To do so, we propose two varieties of agents: (1) an API-calling agent that attempts to perform online tasks through APIs only, similar to traditional coding agents, and (2) a Hybrid Agent that can interact with online data through both web browsing and APIs. In experiments on WebArena, a widely-used and realistic benchmark for web navigation tasks, we find that API-based agents outperform web browsing agents. Hybrid Agents out-perform both others nearly uniformly across tasks, resulting in a more than 20.0% absolute improvement over web browsing alone, achieving a success rate of 35.8%, achiving the SOTA performance among task-agnostic agents. These results strongly suggest that when APIs are available, they present an attractive alternative to relying on web browsing alone.
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Oct 21, 2024Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world's languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models' capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.