 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoorR2X: Indoor Robot-to-Everything Coordination with LLM-Driven Planning
Mar 20, 2026Although robot-to-robot (R2R) communication improves indoor scene understanding beyond what a single robot can achieve, R2R alone cannot overcome partial observability without substantial exploration overhead or scaling team size. In contrast, many indoor environments already include low-cost Internet of Things (IoT) sensors (e.g., cameras) that provide persistent, building-wide context beyond onboard perception. We therefore introduce IndoorR2X, the first benchmark and simulation framework for Large Language Model (LLM)-driven multi-robot task planning with Robot-to-Everything (R2X) perception and communication in indoor environments. IndoorR2X integrates observations from mobile robots and static IoT devices to construct a global semantic state that supports scalable scene understanding, reduces redundant exploration, and enables high-level coordination through LLM-based planning. IndoorR2X provides configurable simulation environments, sensor layouts, robot teams, and task suites to systematically evaluate high-level semantic coordination strategies. Extensive experiments across diverse settings demonstrate that IoT-augmented world modeling improves multi-robot efficiency and reliability, and we highlight key insights and failure modes for advancing LLM-based collaboration between robot teams and indoor IoT sensors.
Affordance RAG: Hierarchical Multimodal Retrieval with Affordance-Aware Embodied Memory for Mobile Manipulation
Dec 22, 2025In this study, we address the problem of open-vocabulary mobile manipulation, where a robot is required to carry a wide range of objects to receptacles based on free-form natural language instructions. This task is challenging, as it involves understanding visual semantics and the affordance of manipulation actions. To tackle these challenges, we propose Affordance RAG, a zero-shot hierarchical multimodal retrieval framework that constructs Affordance-Aware Embodied Memory from pre-explored images. The model retrieves candidate targets based on regional and visual semantics and reranks them with affordance scores, allowing the robot to identify manipulation options that are likely to be executable in real-world environments. Our method outperformed existing approaches in retrieval performance for mobile manipulation instruction in large-scale indoor environments. Furthermore, in real-world experiments where the robot performed mobile manipulation in indoor environments based on free-form instructions, the proposed method achieved a task success rate of 85%, outperforming existing methods in both retrieval performance and overall task success.
Unsupervised Discovery of Long-Term Spatiotemporal Periodic Workflows in Human Activities
Nov 18, 2025Periodic human activities with implicit workflows are common in manufacturing, sports, and daily life. While short-term periodic activities -- characterized by simple structures and high-contrast patterns -- have been widely studied, long-term periodic workflows with low-contrast patterns remain largely underexplored. To bridge this gap, we introduce the first benchmark comprising 580 multimodal human activity sequences featuring long-term periodic workflows. The benchmark supports three evaluation tasks aligned with real-world applications: unsupervised periodic workflow detection, task completion tracking, and procedural anomaly detection. We also propose a lightweight, training-free baseline for modeling diverse periodic workflow patterns. Experiments show that: (i) our benchmark presents significant challenges to both unsupervised periodic detection methods and zero-shot approaches based on powerful large language models (LLMs); (ii) our baseline outperforms competing methods by a substantial margin in all evaluation tasks; and (iii) in real-world applications, our baseline demonstrates deployment advantages on par with traditional supervised workflow detection approaches, eliminating the need for annotation and retraining. Our project page is https://sites.google.com/view/periodicworkflow.
Casper: Inferring Diverse Intents for Assistive Teleoperation with Vision Language Models
Jun 17, 2025



Assistive teleoperation, where control is shared between a human and a robot, enables efficient and intuitive human-robot collaboration in diverse and unstructured environments. A central challenge in real-world assistive teleoperation is for the robot to infer a wide range of human intentions from user control inputs and to assist users with correct actions. Existing methods are either confined to simple, predefined scenarios or restricted to task-specific data distributions at training, limiting their support for real-world assistance. We introduce Casper, an assistive teleoperation system that leverages commonsense knowledge embedded in pre-trained visual language models (VLMs) for real-time intent inference and flexible skill execution. Casper incorporates an open-world perception module for a generalized understanding of novel objects and scenes, a VLM-powered intent inference mechanism that leverages commonsense reasoning to interpret snippets of teleoperated user input, and a skill library that expands the scope of prior assistive teleoperation systems to support diverse, long-horizon mobile manipulation tasks. Extensive empirical evaluation, including human studies and system ablations, demonstrates that Casper improves task performance, reduces human cognitive load, and achieves higher user satisfaction than direct teleoperation and assistive teleoperation baselines.
FieldWorkArena: Agentic AI Benchmark for Real Field Work Tasks
May 26, 2025This paper proposes FieldWorkArena, a benchmark for agentic AI targeting real-world field work. With the recent increase in demand for agentic AI, they are required to monitor and report safety and health incidents, as well as manufacturing-related incidents, that may occur in real-world work environments. Existing agentic AI benchmarks have been limited to evaluating web tasks and are insufficient for evaluating agents in real-world work environments, where complexity increases significantly. In this paper, we define a new action space that agentic AI should possess for real world work environment benchmarks and improve the evaluation function from previous methods to assess the performance of agentic AI in diverse real-world tasks. The dataset consists of videos captured on-site and documents actually used in factories and warehouses, and tasks were created based on interviews with on-site workers and managers. Evaluation results confirmed that performance evaluation considering the characteristics of Multimodal LLM (MLLM) such as GPT-4o is feasible. Additionally, the effectiveness and limitations of the proposed new evaluation method were identified. The complete dataset (HuggingFace) and evaluation program (GitHub) can be downloaded from the following website: https://en-documents.research.global.fujitsu.com/fieldworkarena/.
Energy Considerations of Large Language Model Inference and Efficiency Optimizations
Apr 24, 2025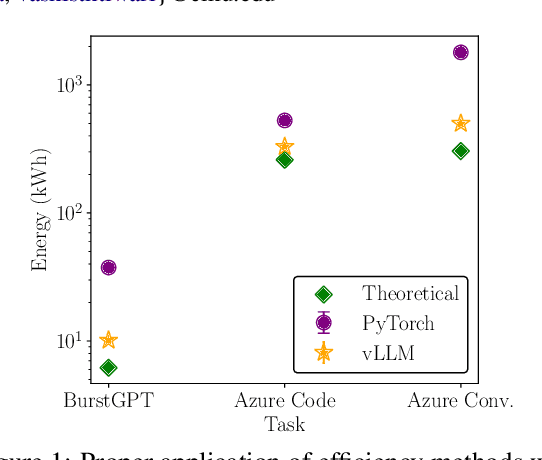
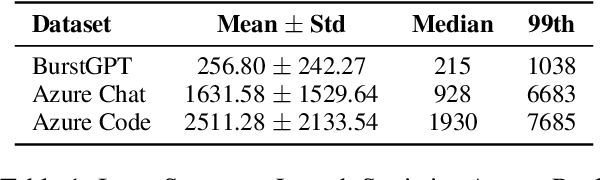
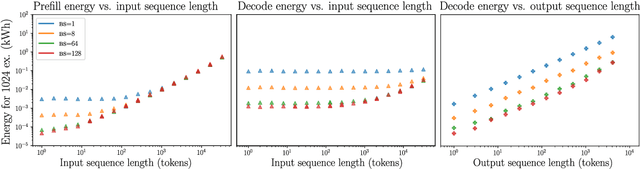

As large language models (LLMs) scale in size and adoption, their computational and environmental costs continue to rise. Prior benchmarking efforts have primarily focused on latency reduction in idealized settings, often overlooking the diverse real-world inference workloads that shape energy use. In this work, we systematically analyze the energy implications of common inference efficiency optimizations across diverse Natural Language Processing (NLP) and generative Artificial Intelligence (AI) workloads, including conversational AI and code generation. We introduce a modeling approach that approximates real-world LLM workflows through a binning strategy for input-output token distributions and batch size variations. Our empirical analysis spans software frameworks, decoding strategies, GPU architectures, online and offline serving settings, and model parallelism configurations. We show that the effectiveness of inference optimizations is highly sensitive to workload geometry, software stack, and hardware accelerators, demonstrating that naive energy estimates based on FLOPs or theoretical GPU utilization significantly underestimate real-world energy consumption. Our findings reveal that the proper application of relevant inference efficiency optimizations can reduce total energy use by up to 73% from unoptimized baselines. These insights provide a foundation for sustainable LLM deployment and inform energy-efficient design strategies for future AI infrastructure.
Looking beyond the next token
Apr 15, 2025The structure of causal language model training assumes that each token can be accurately predicted from the previous context. This contrasts with humans' natural writing and reasoning process, where goals are typically known before the exact argument or phrasings. While this mismatch has been well studied in the literature, the working assumption has been that architectural changes are needed to address this mismatch. We argue that rearranging and processing the training data sequences can allow models to more accurately imitate the true data-generating process, and does not require any other changes to the architecture or training infrastructure. We demonstrate that this technique, Trelawney, and the inference algorithms derived from it allow us to improve performance on several key benchmarks that span planning, algorithmic reasoning, and story generation tasks. Finally, our method naturally enables the generation of long-term goals at no additional cost. We investigate how using the model's goal-generation capability can further improve planning and reasoning. Additionally, we believe Trelawney could potentially open doors to new capabilities beyond the current language modeling paradigm.
Re-thinking Temporal Search for Long-Form Video Understanding
Apr 03, 2025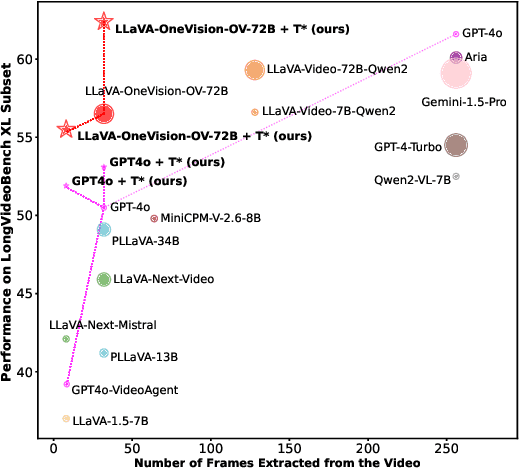
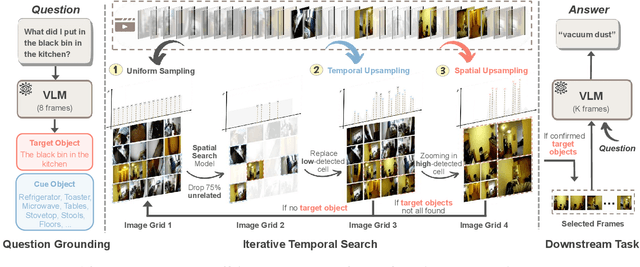
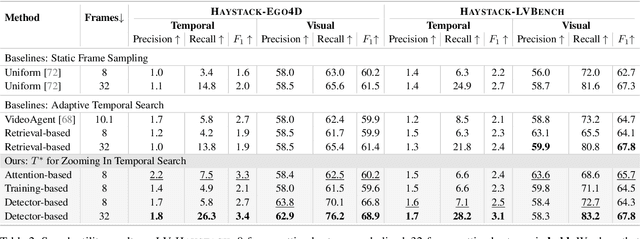
Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o's performance from 50.5% to 53.1% and LLaVA-OneVision-72B's performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
Self-Regulation and Requesting Interventions
Feb 07, 2025



Human intelligence involves metacognitive abilities like self-regulation, recognizing limitations, and seeking assistance only when needed. While LLM Agents excel in many domains, they often lack this awareness. Overconfident agents risk catastrophic failures, while those that seek help excessively hinder efficiency. A key challenge is enabling agents with a limited intervention budget $C$ is to decide when to request assistance. In this paper, we propose an offline framework that trains a "helper" policy to request interventions, such as more powerful models or test-time compute, by combining LLM-based process reward models (PRMs) with tabular reinforcement learning. Using state transitions collected offline, we score optimal intervention timing with PRMs and train the helper model on these labeled trajectories. This offline approach significantly reduces costly intervention calls during training. Furthermore, the integration of PRMs with tabular RL enhances robustness to off-policy data while avoiding the inefficiencies of deep RL. We empirically find that our method delivers optimal helper behavior.
Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning
Dec 12, 2024



Do large language models (LLMs) have theory of mind? A plethora of papers and benchmarks have been introduced to evaluate if current models have been able to develop this key ability of social intelligence. However, all rely on limited datasets with simple patterns that can potentially lead to problematic blind spots in evaluation and an overestimation of model capabilities. We introduce ExploreToM, the first framework to allow large-scale generation of diverse and challenging theory of mind data for robust training and evaluation. Our approach leverages an A* search over a custom domain-specific language to produce complex story structures and novel, diverse, yet plausible scenarios to stress test the limits of LLMs. Our evaluation reveals that state-of-the-art LLMs, such as Llama-3.1-70B and GPT-4o, show accuracies as low as 0% and 9% on ExploreToM-generated data, highlighting the need for more robust theory of mind evaluation. As our generations are a conceptual superset of prior work, fine-tuning on our data yields a 27-point accuracy improvement on the classic ToMi benchmark (Le et al., 2019). ExploreToM also enables uncovering underlying skills and factors missing for models to show theory of mind, such as unreliable state tracking or data imbalances, which may contribute to models' poor performance on benchmarks.