 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrypto x AI, AI x Crypto: A Survey
Jun 11, 2026The intersection of crypto x AI is spawning papers, products, online posts, and companies. All the surrounding buzz, though, obscures what exactly has been done, what the opportunities and challenges are, and what open questions deserve attention. This survey paper asks what AI can do for blockchain-based technologies (broadly construed as "crypto") (crypto x AI), and vice versa (AI x crypto). We systematize existing work, summarize key takeaways, highlight open research questions, and offer a perspective on pervasive industry misconceptions, concluding that AI and crypto are still in the very early stages of meaningful integration.
Energy Considerations of Large Language Model Inference and Efficiency Optimizations
Apr 24, 2025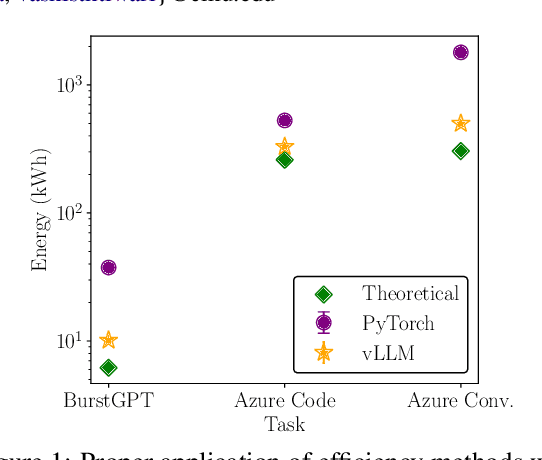
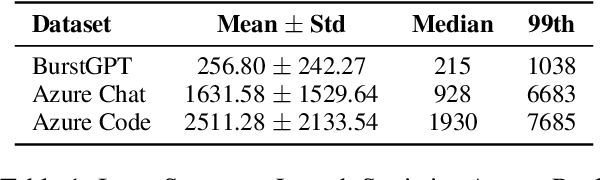
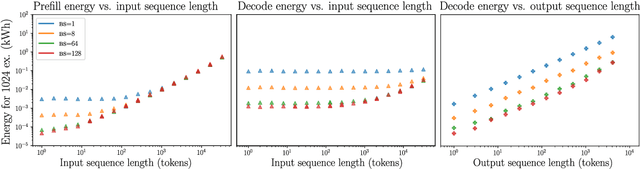

As large language models (LLMs) scale in size and adoption, their computational and environmental costs continue to rise. Prior benchmarking efforts have primarily focused on latency reduction in idealized settings, often overlooking the diverse real-world inference workloads that shape energy use. In this work, we systematically analyze the energy implications of common inference efficiency optimizations across diverse Natural Language Processing (NLP) and generative Artificial Intelligence (AI) workloads, including conversational AI and code generation. We introduce a modeling approach that approximates real-world LLM workflows through a binning strategy for input-output token distributions and batch size variations. Our empirical analysis spans software frameworks, decoding strategies, GPU architectures, online and offline serving settings, and model parallelism configurations. We show that the effectiveness of inference optimizations is highly sensitive to workload geometry, software stack, and hardware accelerators, demonstrating that naive energy estimates based on FLOPs or theoretical GPU utilization significantly underestimate real-world energy consumption. Our findings reveal that the proper application of relevant inference efficiency optimizations can reduce total energy use by up to 73% from unoptimized baselines. These insights provide a foundation for sustainable LLM deployment and inform energy-efficient design strategies for future AI infrastructure.
Hardware Scaling Trends and Diminishing Returns in Large-Scale Distributed Training
Nov 20, 2024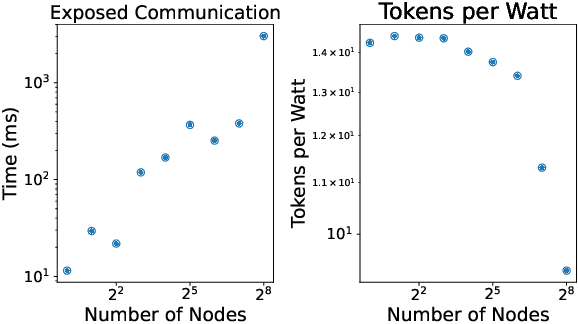

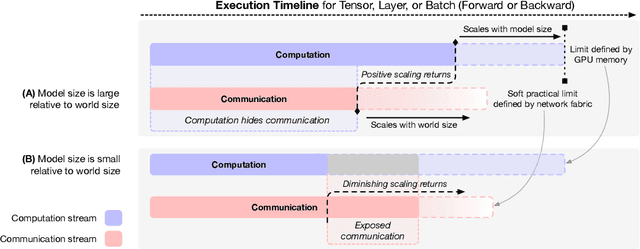
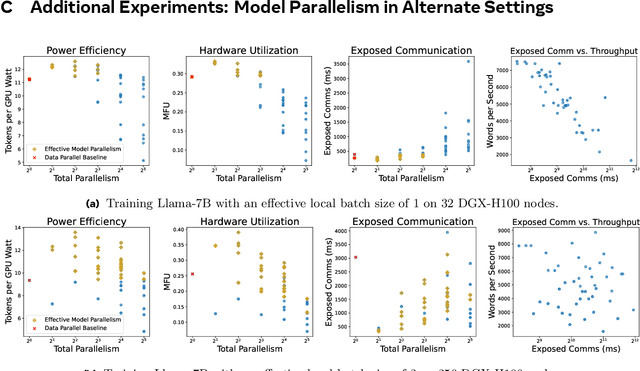
Dramatic increases in the capabilities of neural network models in recent years are driven by scaling model size, training data, and corresponding computational resources. To develop the exceedingly large networks required in modern applications, such as large language models (LLMs), model training is distributed across tens of thousands of hardware accelerators (e.g. GPUs), requiring orchestration of computation and communication across large computing clusters. In this work, we demonstrate that careful consideration of hardware configuration and parallelization strategy is critical for effective (i.e. compute- and cost-efficient) scaling of model size, training data, and total computation. We conduct an extensive empirical study of the performance of large-scale LLM training workloads across model size, hardware configurations, and distributed parallelization strategies. We demonstrate that: (1) beyond certain scales, overhead incurred from certain distributed communication strategies leads parallelization strategies previously thought to be sub-optimal in fact become preferable; and (2) scaling the total number of accelerators for large model training quickly yields diminishing returns even when hardware and parallelization strategies are properly optimized, implying poor marginal performance per additional unit of power or GPU-hour.
Gradient Localization Improves Lifelong Pretraining of Language Models
Nov 07, 2024Large Language Models (LLMs) trained on web-scale text corpora have been shown to capture world knowledge in their parameters. However, the mechanism by which language models store different types of knowledge is poorly understood. In this work, we examine two types of knowledge relating to temporally sensitive entities and demonstrate that each type is localized to different sets of parameters within the LLMs. We hypothesize that the lack of consideration of the locality of knowledge in existing continual learning methods contributes to both: the failed uptake of new information, and catastrophic forgetting of previously learned information. We observe that sequences containing references to updated and newly mentioned entities exhibit larger gradient norms in a subset of layers. We demonstrate that targeting parameter updates to these relevant layers can improve the performance of continually pretraining on language containing temporal drift.
Efficiency Pentathlon: A Standardized Arena for Efficiency Evaluation
Jul 19, 2023Rising computational demands of modern natural language processing (NLP) systems have increased the barrier to entry for cutting-edge research while posing serious environmental concerns. Yet, progress on model efficiency has been impeded by practical challenges in model evaluation and comparison. For example, hardware is challenging to control due to disparate levels of accessibility across different institutions. Moreover, improvements in metrics such as FLOPs often fail to translate to progress in real-world applications. In response, we introduce Pentathlon, a benchmark for holistic and realistic evaluation of model efficiency. Pentathlon focuses on inference, which accounts for a majority of the compute in a model's lifecycle. It offers a strictly-controlled hardware platform, and is designed to mirror real-world applications scenarios. It incorporates a suite of metrics that target different aspects of efficiency, including latency, throughput, memory overhead, and energy consumption. Pentathlon also comes with a software library that can be seamlessly integrated into any codebase and enable evaluation. As a standardized and centralized evaluation platform, Pentathlon can drastically reduce the workload to make fair and reproducible efficiency comparisons. While initially focused on natural language processing (NLP) models, Pentathlon is designed to allow flexible extension to other fields. We envision Pentathlon will stimulate algorithmic innovations in building efficient models, and foster an increased awareness of the social and environmental implications in the development of future-generation NLP models.
The Framework Tax: Disparities Between Inference Efficiency in Research and Deployment
Feb 13, 2023



Increased focus on the deployment of machine learning systems has led to rapid improvements in hardware accelerator performance and neural network model efficiency. However, the resulting reductions in floating point operations and increases in computational throughput of accelerators have not directly translated to improvements in real-world inference latency. We demonstrate that these discrepancies can be largely attributed to mis-alignments between model architectures and the capabilities of underlying hardware due to bottlenecks introduced by deep learning frameworks. We denote this phenomena as the \textit{framework tax}, and observe that the disparity is growing as hardware speed increases over time. In this work, we examine this phenomena through a series of case studies analyzing the effects of model design decisions, framework paradigms, and hardware platforms on total model latency. Based on our findings, we provide actionable recommendations to ML researchers and practitioners aimed at narrowing the gap between efficient ML model research and practice.
CIGLI: Conditional Image Generation from Language & Image
Aug 20, 2021
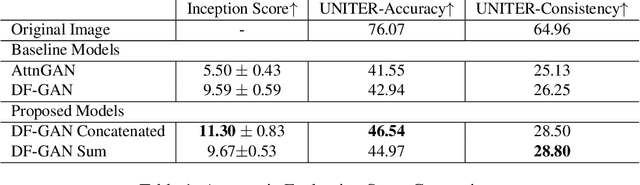


Multi-modal generation has been widely explored in recent years. Current research directions involve generating text based on an image or vice versa. In this paper, we propose a new task called CIGLI: Conditional Image Generation from Language and Image. Instead of generating an image based on text as in text-image generation, this task requires the generation of an image from a textual description and an image prompt. We designed a new dataset to ensure that the text description describes information from both images, and that solely analyzing the description is insufficient to generate an image. We then propose a novel language-image fusion model which improves the performance over two established baseline methods, as evaluated by quantitative (automatic) and qualitative (human) evaluations. The code and dataset is available at https://github.com/vincentlux/CIGLI.
G-DAUG: Generative Data Augmentation for Commonsense Reasoning
Apr 24, 2020
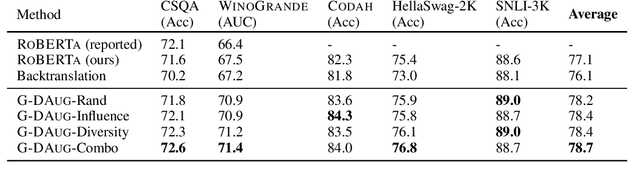
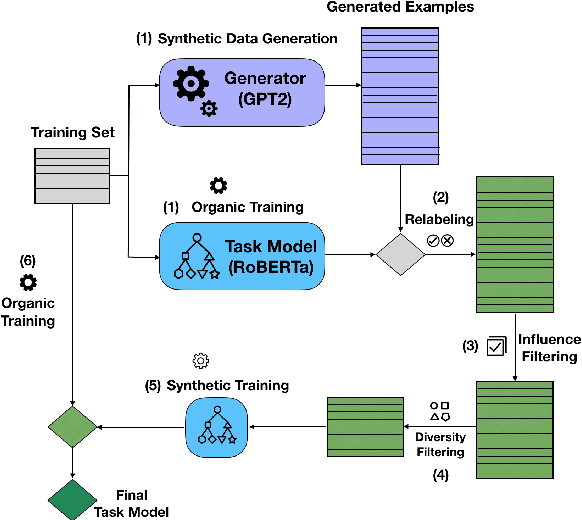
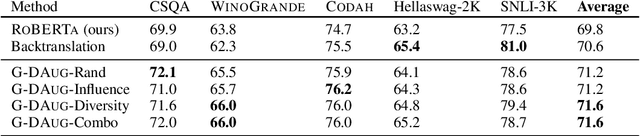
Recent advances in commonsense reasoning depend on large-scale human-annotated training data to achieve peak performance. However, manual curation of training examples is expensive and has been shown to introduce annotation artifacts that neural models can readily exploit and overfit on. We investigate G-DAUG, a novel generative data augmentation method that aims to achieve more accurate and robust learning in the low-resource setting. Our approach generates synthetic examples using pretrained language models, and selects the most informative and diverse set of examples for data augmentation. In experiments with multiple commonsense reasoning benchmarks, G-DAUG consistently outperforms existing data augmentation methods based on back-translation, and establishes a new state-of-the-art on WinoGrande, CODAH, and CommonsenseQA. Further, in addition to improvements in in-distribution accuracy, G-DAUG-augmented training also enhances out-of-distribution generalization, showing greater robustness against adversarial or perturbed examples. Our analysis demonstrates that G-DAUG produces a diverse set of fluent training examples, and that its selection and training approaches are important for performance. Our findings encourage future research toward generative data augmentation to enhance both in-distribution learning and out-of-distribution generalization.
CODAH: An Adversarially Authored Question-Answer Dataset for Common Sense
Apr 12, 2019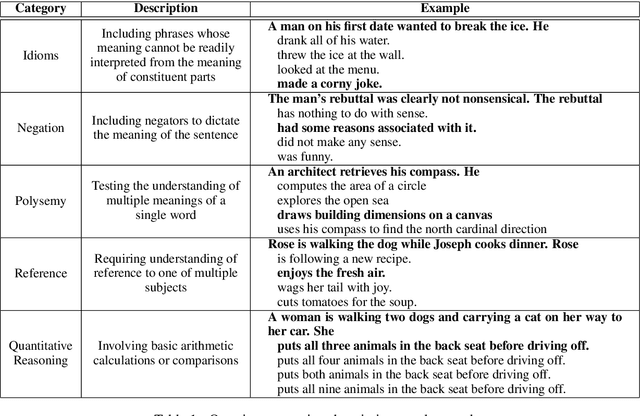
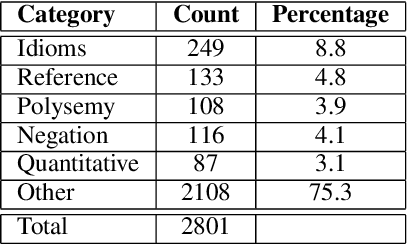
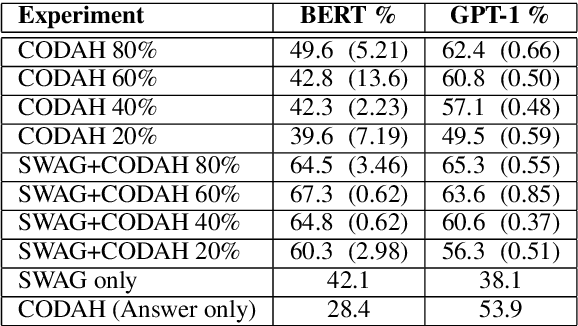
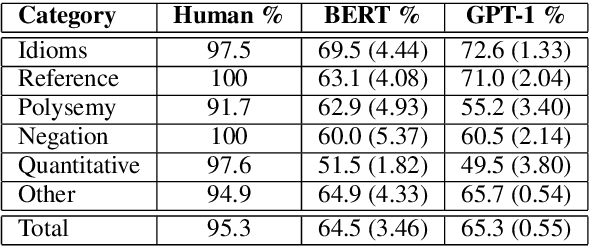
Commonsense reasoning is a critical AI capability, but it is difficult to construct challenging datasets that test common sense. Recent neural question-answering systems, based on large pre-trained models of language, have already achieved near-human-level performance on commonsense knowledge benchmarks. These systems do not possess human-level common sense, but are able to exploit limitations of the datasets to achieve human-level scores. We introduce the CODAH dataset, an adversarially-constructed evaluation dataset for testing common sense. CODAH forms a challenging extension to the recently-proposed SWAG dataset, which tests commonsense knowledge using sentence-completion questions that describe situations observed in video. To produce a more difficult dataset, we introduce a novel procedure for question acquisition in which workers author questions designed to target weaknesses of state-of-the-art neural question answering systems. Workers are rewarded for submissions that models fail to answer correctly both before and after fine-tuning (in cross-validation). We create 2.8k questions via this procedure and evaluate the performance of multiple state-of-the-art question answering systems on our dataset. We observe a significant gap between human performance, which is 95.3%, and the performance of the best baseline accuracy of 65.3% by the OpenAI GPT model.