 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Representation Learning Methods in Particle Physics Foundation Models
Nov 16, 2025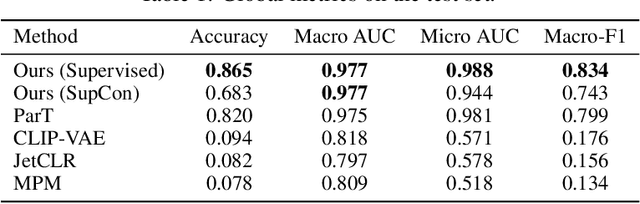
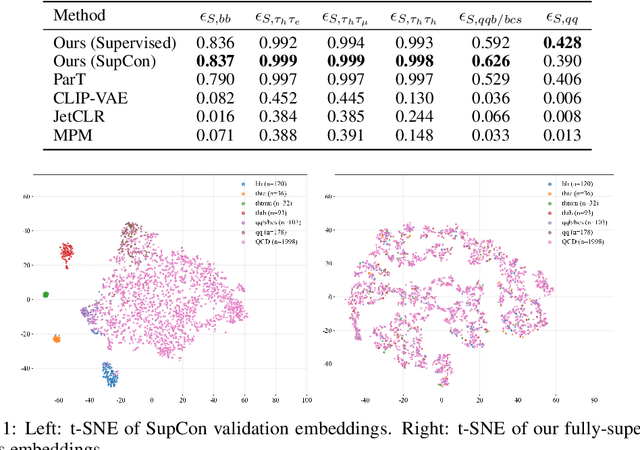
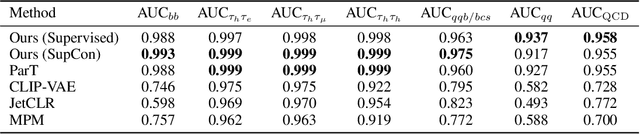
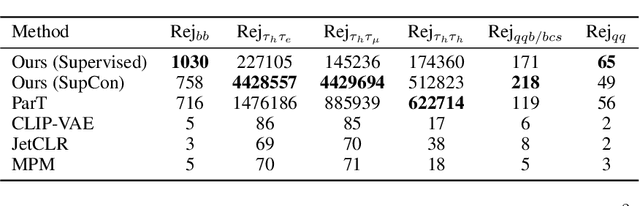
We present a systematic evaluation of representation learning objectives for particle physics within a unified framework. Our study employs a shared transformer-based particle-cloud encoder with standardized preprocessing, matched sampling, and a consistent evaluation protocol on a jet classification dataset. We compare contrastive (supervised and self-supervised), masked particle modeling, and generative reconstruction objectives under a common training regimen. In addition, we introduce targeted supervised architectural modifications that achieve state-of-the-art performance on benchmark evaluations. This controlled comparison isolates the contributions of the learning objective, highlights their respective strengths and limitations, and provides reproducible baselines. We position this work as a reference point for the future development of foundation models in particle physics, enabling more transparent and robust progress across the community.
Existing Industry Practice for the EU AI Act's General-Purpose AI Code of Practice Safety and Security Measures
Apr 21, 2025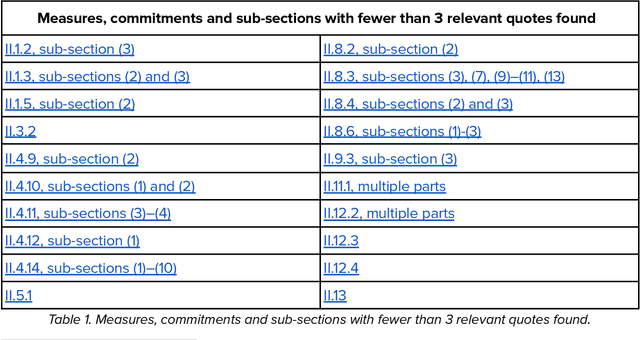
This report provides a detailed comparison between the measures proposed in the EU AI Act's General-Purpose AI (GPAI) Code of Practice (Third Draft) and current practices adopted by leading AI companies. As the EU moves toward enforcing binding obligations for GPAI model providers, the Code of Practice will be key to bridging legal requirements with concrete technical commitments. Our analysis focuses on the draft's Safety and Security section which is only relevant for the providers of the most advanced models (Commitments II.1-II.16) and excerpts from current public-facing documents quotes that are relevant to each individual measure. We systematically reviewed different document types - including companies' frontier safety frameworks and model cards - from over a dozen companies, including OpenAI, Anthropic, Google DeepMind, Microsoft, Meta, Amazon, and others. This report is not meant to be an indication of legal compliance nor does it take any prescriptive viewpoint about the Code of Practice or companies' policies. Instead, it aims to inform the ongoing dialogue between regulators and GPAI model providers by surfacing evidence of precedent.
Not-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025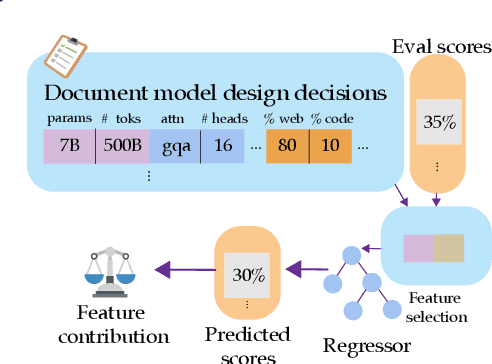
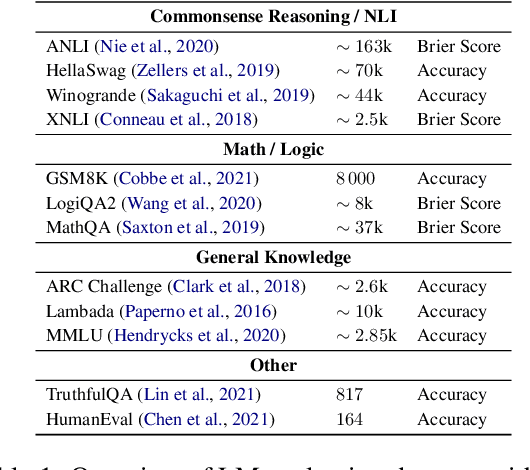
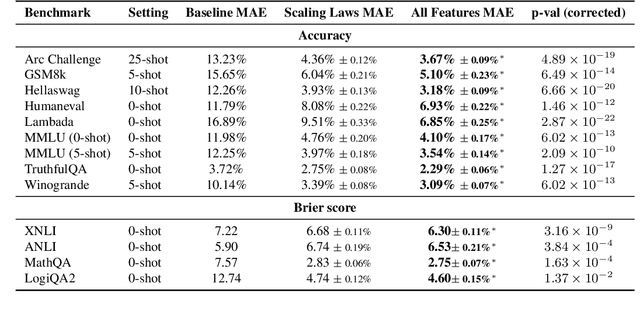
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts
Nov 22, 2024Frontier AI safety policies highlight automation of AI research and development (R&D) by AI agents as an important capability to anticipate. However, there exist few evaluations for AI R&D capabilities, and none that are highly realistic and have a direct comparison to human performance. We introduce RE-Bench (Research Engineering Benchmark, v1), which consists of 7 challenging, open-ended ML research engineering environments and data from 71 8-hour attempts by 61 distinct human experts. We confirm that our experts make progress in the environments given 8 hours, with 82% of expert attempts achieving a non-zero score and 24% matching or exceeding our strong reference solutions. We compare humans to several public frontier models through best-of-k with varying time budgets and agent designs, and find that the best AI agents achieve a score 4x higher than human experts when both are given a total time budget of 2 hours per environment. However, humans currently display better returns to increasing time budgets, narrowly exceeding the top AI agent scores given an 8-hour budget, and achieving 2x the score of the top AI agent when both are given 32 total hours (across different attempts). Qualitatively, we find that modern AI agents possess significant expertise in many ML topics -- e.g. an agent wrote a faster custom Triton kernel than any of our human experts' -- and can generate and test solutions over ten times faster than humans, at much lower cost. We open-source the evaluation environments, human expert data, analysis code and agent trajectories to facilitate future research.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
AI Deception: A Survey of Examples, Risks, and Potential Solutions
Aug 28, 2023



This paper argues that a range of current AI systems have learned how to deceive humans. We define deception as the systematic inducement of false beliefs in the pursuit of some outcome other than the truth. We first survey empirical examples of AI deception, discussing both special-use AI systems (including Meta's CICERO) built for specific competitive situations, and general-purpose AI systems (such as large language models). Next, we detail several risks from AI deception, such as fraud, election tampering, and losing control of AI systems. Finally, we outline several potential solutions to the problems posed by AI deception: first, regulatory frameworks should subject AI systems that are capable of deception to robust risk-assessment requirements; second, policymakers should implement bot-or-not laws; and finally, policymakers should prioritize the funding of relevant research, including tools to detect AI deception and to make AI systems less deceptive. Policymakers, researchers, and the broader public should work proactively to prevent AI deception from destabilizing the shared foundations of our society.
CODAH: An Adversarially Authored Question-Answer Dataset for Common Sense
Apr 12, 2019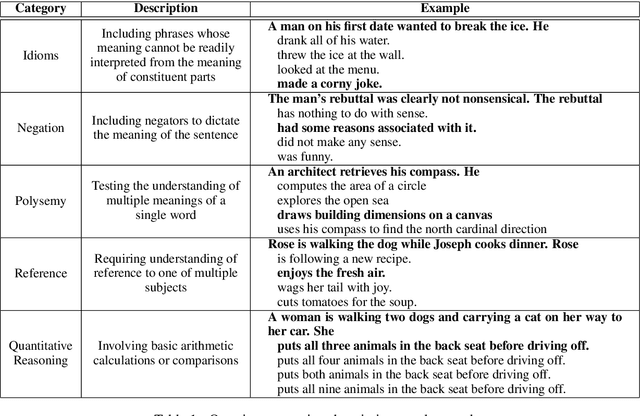
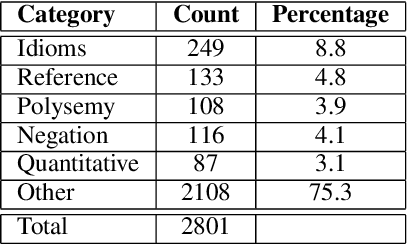
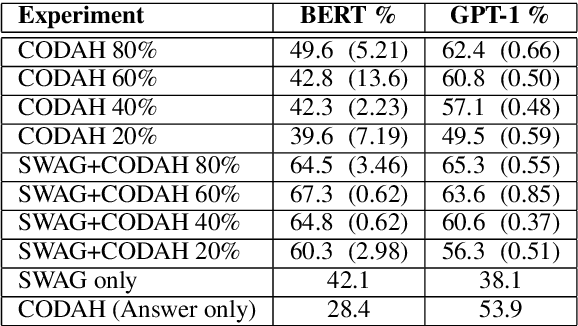
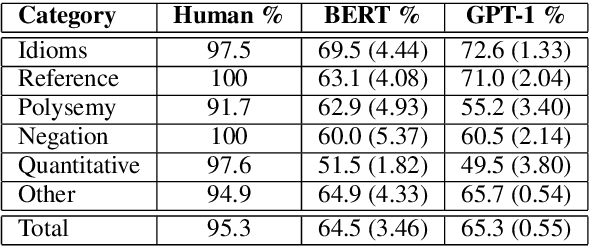
Commonsense reasoning is a critical AI capability, but it is difficult to construct challenging datasets that test common sense. Recent neural question-answering systems, based on large pre-trained models of language, have already achieved near-human-level performance on commonsense knowledge benchmarks. These systems do not possess human-level common sense, but are able to exploit limitations of the datasets to achieve human-level scores. We introduce the CODAH dataset, an adversarially-constructed evaluation dataset for testing common sense. CODAH forms a challenging extension to the recently-proposed SWAG dataset, which tests commonsense knowledge using sentence-completion questions that describe situations observed in video. To produce a more difficult dataset, we introduce a novel procedure for question acquisition in which workers author questions designed to target weaknesses of state-of-the-art neural question answering systems. Workers are rewarded for submissions that models fail to answer correctly both before and after fine-tuning (in cross-validation). We create 2.8k questions via this procedure and evaluate the performance of multiple state-of-the-art question answering systems on our dataset. We observe a significant gap between human performance, which is 95.3%, and the performance of the best baseline accuracy of 65.3% by the OpenAI GPT model.
Data-Driven Design for Fourier Ptychographic Microscopy
Apr 08, 2019
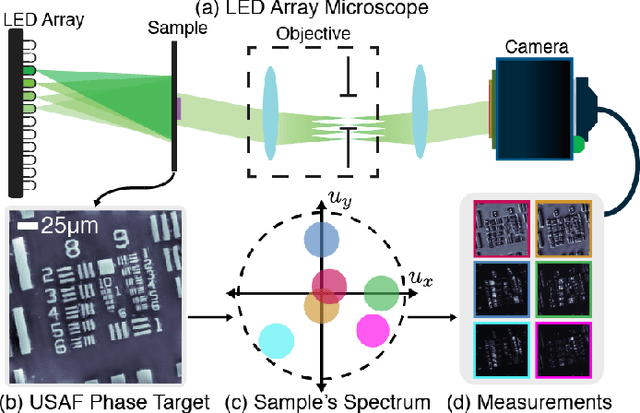
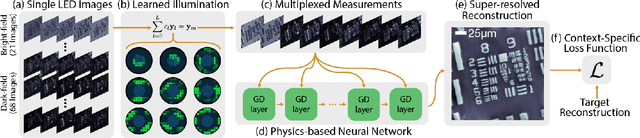
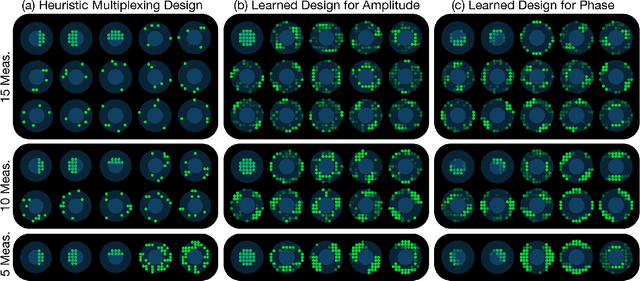
Fourier Ptychographic Microscopy (FPM) is a computational imaging method that is able to super-resolve features beyond the diffraction-limit set by the objective lens of a traditional microscope. This is accomplished by using synthetic aperture and phase retrieval algorithms to combine many measurements captured by an LED array microscope with programmable source patterns. FPM provides simultaneous large field-of-view and high resolution imaging, but at the cost of reduced temporal resolution, thereby limiting live cell applications. In this work, we learn LED source pattern designs that compress the many required measurements into only a few, with negligible loss in reconstruction quality or resolution. This is accomplished by recasting the super-resolution reconstruction as a Physics-based Neural Network and learning the experimental design to optimize the network's overall performance. Specifically, we learn LED patterns for different applications (e.g. amplitude contrast and quantitative phase imaging) and show that the designs we learn through simulation generalize well in the experimental setting. Further, we discuss a context-specific loss function, practical memory limitations, and interpretability of our learned designs.
Drive2Vec: Multiscale State-Space Embedding of Vehicular Sensor Data
Jun 12, 2018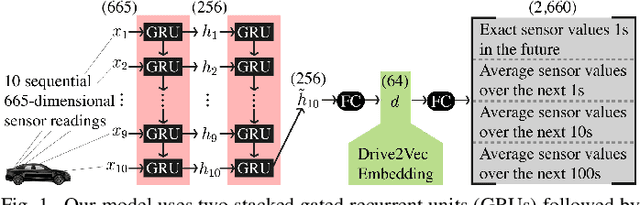
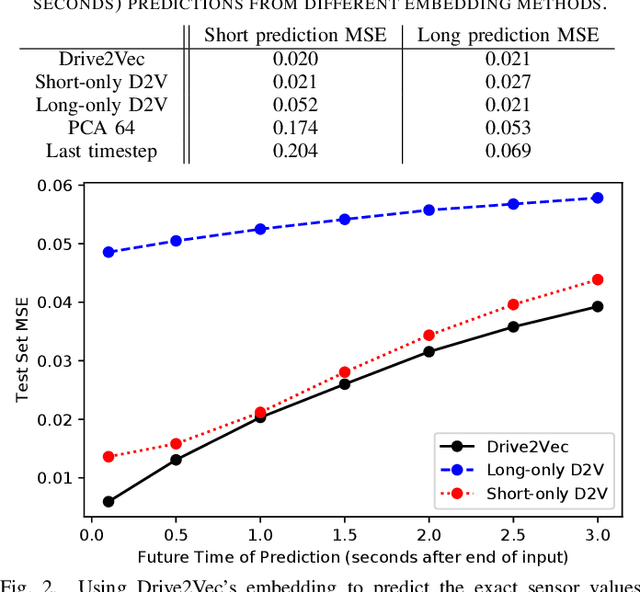
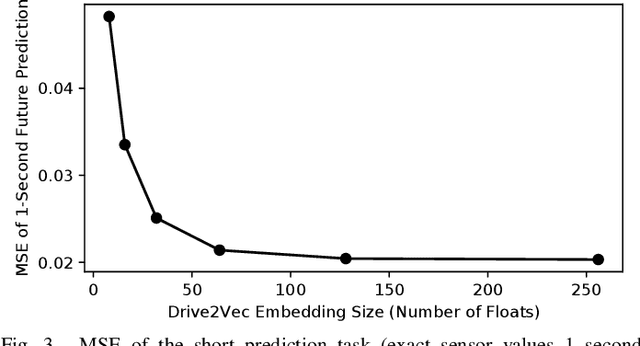

With automobiles becoming increasingly reliant on sensors to perform various driving tasks, it is important to encode the relevant CAN bus sensor data in a way that captures the general state of the vehicle in a compact form. In this paper, we develop a deep learning-based method, called Drive2Vec, for embedding such sensor data in a low-dimensional yet actionable form. Our method is based on stacked gated recurrent units (GRUs). It accepts a short interval of automobile sensor data as input and computes a low-dimensional representation of that data, which can then be used to accurately solve a range of tasks. With this representation, we (1) predict the exact values of the sensors in the short term (up to three seconds in the future), (2) forecast the long-term average values of these same sensors, (3) infer additional contextual information that is not encoded in the data, including the identity of the driver behind the wheel, and (4) build a knowledge base that can be used to auto-label data and identify risky states. We evaluate our approach on a dataset collected by Audi, which equipped a fleet of test vehicles with data loggers to store all sensor readings on 2,098 hours of driving on real roads. We show in several experiments that our method outperforms other baselines by up to 90%, and we further demonstrate how these embeddings of sensor data can be used to solve a variety of real-world automotive applications.