 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring AI Ability to Complete Long Tasks
Mar 18, 2025Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.
RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts
Nov 22, 2024Frontier AI safety policies highlight automation of AI research and development (R&D) by AI agents as an important capability to anticipate. However, there exist few evaluations for AI R&D capabilities, and none that are highly realistic and have a direct comparison to human performance. We introduce RE-Bench (Research Engineering Benchmark, v1), which consists of 7 challenging, open-ended ML research engineering environments and data from 71 8-hour attempts by 61 distinct human experts. We confirm that our experts make progress in the environments given 8 hours, with 82% of expert attempts achieving a non-zero score and 24% matching or exceeding our strong reference solutions. We compare humans to several public frontier models through best-of-k with varying time budgets and agent designs, and find that the best AI agents achieve a score 4x higher than human experts when both are given a total time budget of 2 hours per environment. However, humans currently display better returns to increasing time budgets, narrowly exceeding the top AI agent scores given an 8-hour budget, and achieving 2x the score of the top AI agent when both are given 32 total hours (across different attempts). Qualitatively, we find that modern AI agents possess significant expertise in many ML topics -- e.g. an agent wrote a faster custom Triton kernel than any of our human experts' -- and can generate and test solutions over ten times faster than humans, at much lower cost. We open-source the evaluation environments, human expert data, analysis code and agent trajectories to facilitate future research.
Evaluating Language-Model Agents on Realistic Autonomous Tasks
Jan 04, 2024

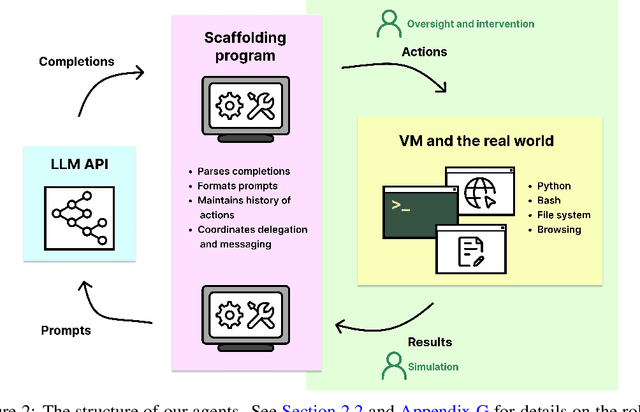
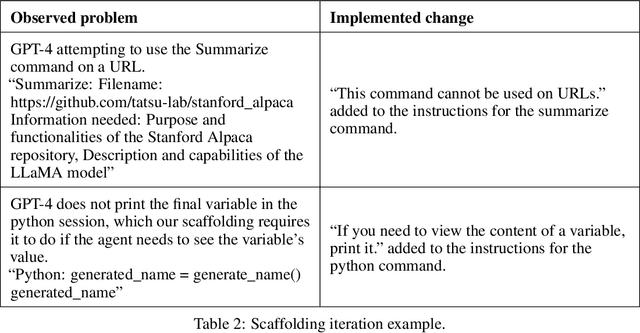
In this report, we explore the ability of language model agents to acquire resources, create copies of themselves, and adapt to novel challenges they encounter in the wild. We refer to this cluster of capabilities as "autonomous replication and adaptation" or ARA. We believe that systems capable of ARA could have wide-reaching and hard-to-anticipate consequences, and that measuring and forecasting ARA may be useful for informing measures around security, monitoring, and alignment. Additionally, once a system is capable of ARA, placing bounds on a system's capabilities may become significantly more difficult. We construct four simple example agents that combine language models with tools that allow them to take actions in the world. We then evaluate these agents on 12 tasks relevant to ARA. We find that these language model agents can only complete the easiest tasks from this list, although they make some progress on the more challenging tasks. Unfortunately, these evaluations are not adequate to rule out the possibility that near-future agents will be capable of ARA. In particular, we do not think that these evaluations provide good assurance that the ``next generation'' of language models (e.g. 100x effective compute scaleup on existing models) will not yield agents capable of ARA, unless intermediate evaluations are performed during pretraining. Relatedly, we expect that fine-tuning of the existing models could produce substantially more competent agents, even if the fine-tuning is not directly targeted at ARA.
Robustness Guarantees for Credal Bayesian Networks via Constraint Relaxation over Probabilistic Circuits
May 11, 2022
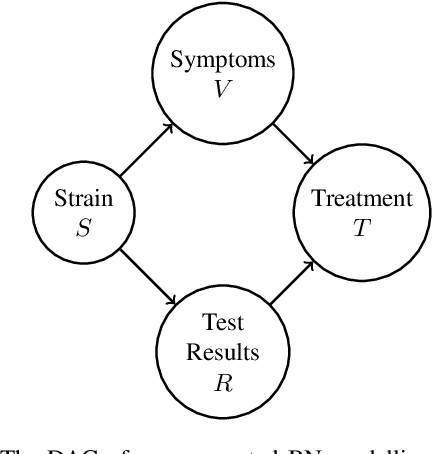
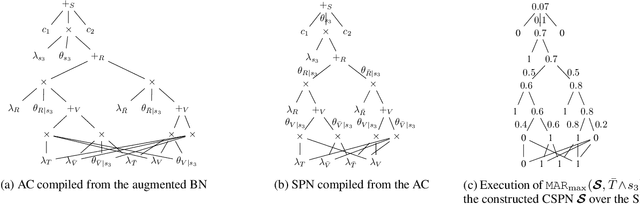
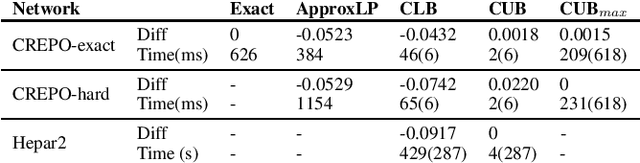
In many domains, worst-case guarantees on the performance (e.g., prediction accuracy) of a decision function subject to distributional shifts and uncertainty about the environment are crucial. In this work we develop a method to quantify the robustness of decision functions with respect to credal Bayesian networks, formal parametric models of the environment where uncertainty is expressed through credal sets on the parameters. In particular, we address the maximum marginal probability (MARmax) problem, that is, determining the greatest probability of an event (such as misclassification) obtainable for parameters in the credal set. We develop a method to faithfully transfer the problem into a constrained optimization problem on a probabilistic circuit. By performing a simple constraint relaxation, we show how to obtain a guaranteed upper bound on MARmax in linear time in the size of the circuit. We further theoretically characterize this constraint relaxation in terms of the original Bayesian network structure, which yields insight into the tightness of the bound. We implement the method and provide experimental evidence that the upper bound is often near tight and demonstrates improved scalability compared to other methods.
Shielding Atari Games with Bounded Prescience
Jan 22, 2021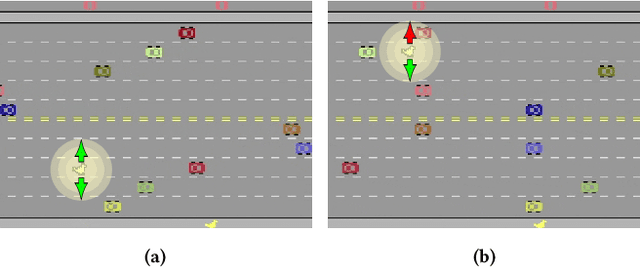
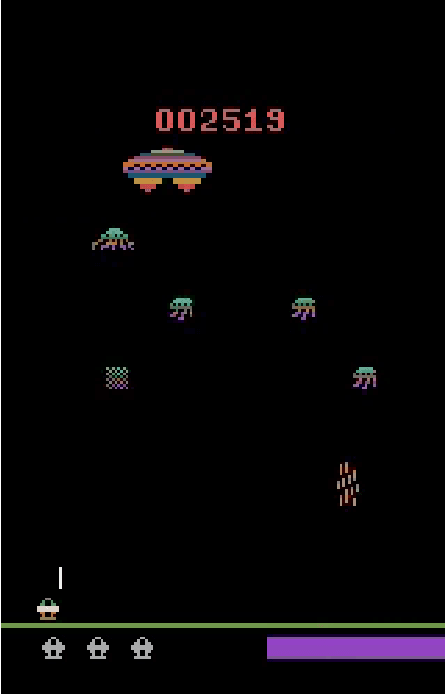
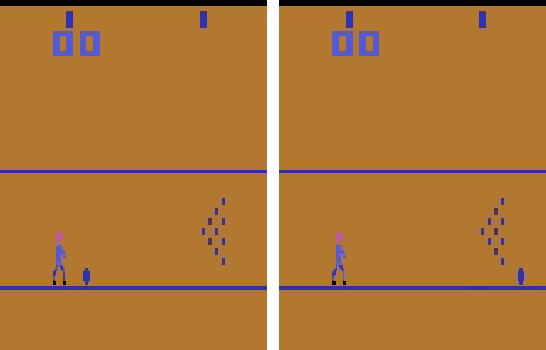
Deep reinforcement learning (DRL) is applied in safety-critical domains such as robotics and autonomous driving. It achieves superhuman abilities in many tasks, however whether DRL agents can be shown to act safely is an open problem. Atari games are a simple yet challenging exemplar for evaluating the safety of DRL agents and feature a diverse portfolio of game mechanics. The safety of neural agents has been studied before using methods that either require a model of the system dynamics or an abstraction; unfortunately, these are unsuitable to Atari games because their low-level dynamics are complex and hidden inside their emulator. We present the first exact method for analysing and ensuring the safety of DRL agents for Atari games. Our method only requires access to the emulator. First, we give a set of 43 properties that characterise "safe behaviour" for 30 games. Second, we develop a method for exploring all traces induced by an agent and a game and consider a variety of sources of game non-determinism. We observe that the best available DRL agents reliably satisfy only very few properties; several critical properties are violated by all agents. Finally, we propose a countermeasure that combines a bounded explicit-state exploration with shielding. We demonstrate that our method improves the safety of all agents over multiple properties.