 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Deep Reinforcement Learning for Continuous Motion Planning with Temporal Logic
Feb 24, 2021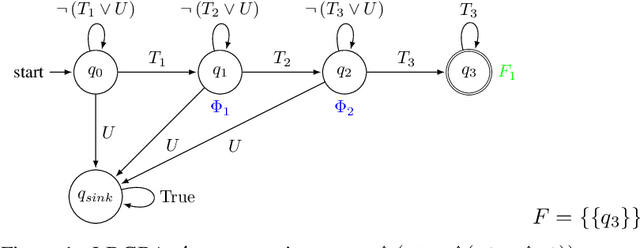
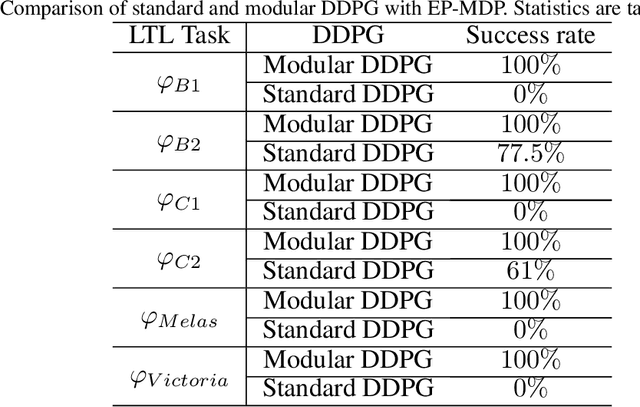
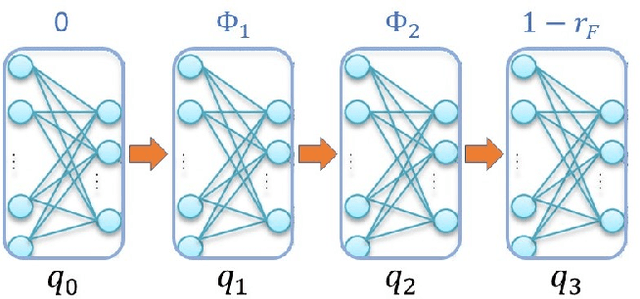
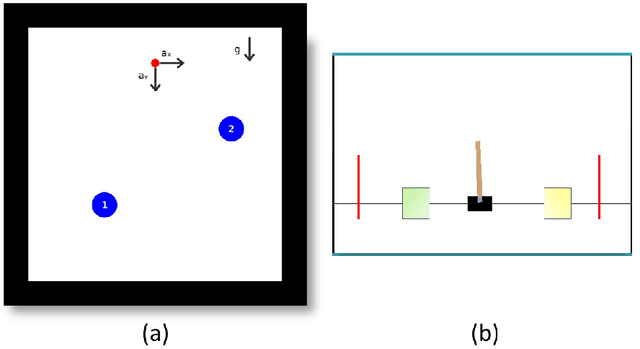
This paper investigates the motion planning of autonomous dynamical systems modeled by Markov decision processes (MDP) with unknown transition probabilities over continuous state and action spaces. Linear temporal logic (LTL) is used to specify high-level tasks over infinite horizon, which can be converted into a limit deterministic generalized B\"uchi automaton (LDGBA) with several accepting sets. The novelty is to design an embedded product MDP (EP-MDP) between the LDGBA and the MDP by incorporating a synchronous tracking-frontier function to record unvisited accepting sets of the automaton, and to facilitate the satisfaction of the accepting conditions. The proposed LDGBA-based reward shaping and discounting schemes for the model-free reinforcement learning (RL) only depend on the EP-MDP states and can overcome the issues of sparse rewards. Rigorous analysis shows that any RL method that optimizes the expected discounted return is guaranteed to find an optimal policy whose traces maximize the satisfaction probability. A modular deep deterministic policy gradient (DDPG) is then developed to generate such policies over continuous state and action spaces. The performance of our framework is evaluated via an array of OpenAI gym environments.
Shielding Atari Games with Bounded Prescience
Jan 22, 2021
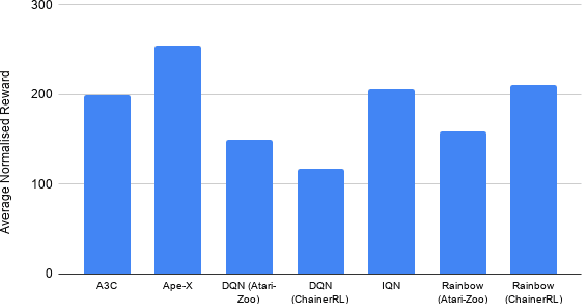
Deep reinforcement learning (DRL) is applied in safety-critical domains such as robotics and autonomous driving. It achieves superhuman abilities in many tasks, however whether DRL agents can be shown to act safely is an open problem. Atari games are a simple yet challenging exemplar for evaluating the safety of DRL agents and feature a diverse portfolio of game mechanics. The safety of neural agents has been studied before using methods that either require a model of the system dynamics or an abstraction; unfortunately, these are unsuitable to Atari games because their low-level dynamics are complex and hidden inside their emulator. We present the first exact method for analysing and ensuring the safety of DRL agents for Atari games. Our method only requires access to the emulator. First, we give a set of 43 properties that characterise "safe behaviour" for 30 games. Second, we develop a method for exploring all traces induced by an agent and a game and consider a variety of sources of game non-determinism. We observe that the best available DRL agents reliably satisfy only very few properties; several critical properties are violated by all agents. Finally, we propose a countermeasure that combines a bounded explicit-state exploration with shielding. We demonstrate that our method improves the safety of all agents over multiple properties.
Jump Operator Planning: Goal-Conditioned Policy Ensembles and Zero-Shot Transfer
Jul 06, 2020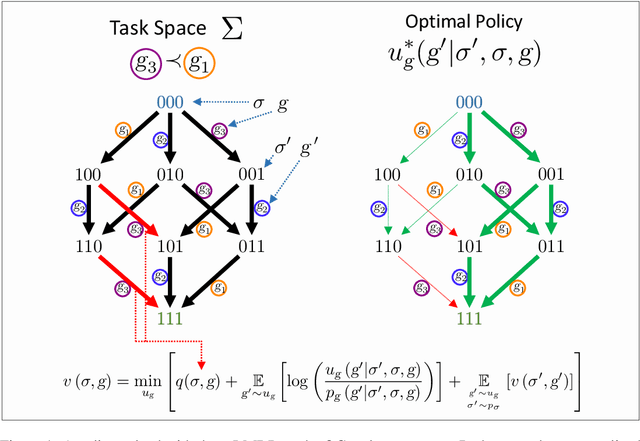
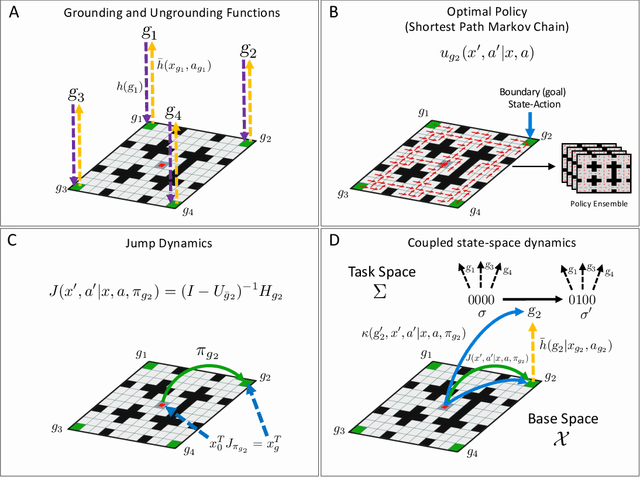
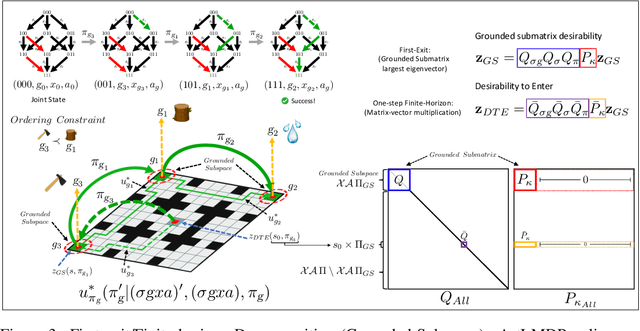
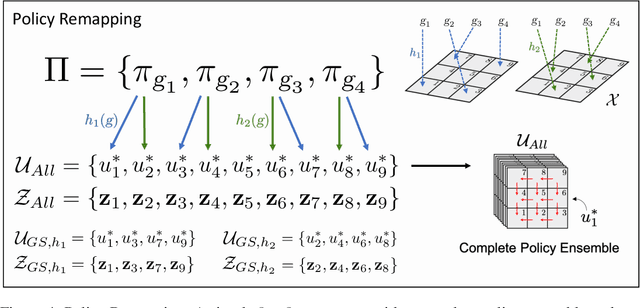
In Hierarchical Control, compositionality, abstraction, and task-transfer are crucial for designing versatile algorithms which can solve a variety of problems with maximal representational reuse. We propose a novel hierarchical and compositional framework called Jump-Operator Dynamic Programming for quickly computing solutions within a super-exponential space of sequential sub-goal tasks with ordering constraints, while also providing a fast linearly-solvable algorithm as an implementation. This approach involves controlling over an ensemble of reusable goal-conditioned polices functioning as temporally extended actions, and utilizes transition operators called feasibility functions, which are used to summarize initial-to-final state dynamics of the polices. Consequently, the added complexity of grounding a high-level task space onto a larger ambient state-space can be mitigated by optimizing in a lower-dimensional subspace defined by the grounding, substantially improving the scalability of the algorithm while effecting transferable solutions. We then identify classes of objective functions on this subspace whose solutions are invariant to the grounding, resulting in optimal zero-shot transfer.
Cautious Reinforcement Learning with Logical Constraints
Mar 21, 2020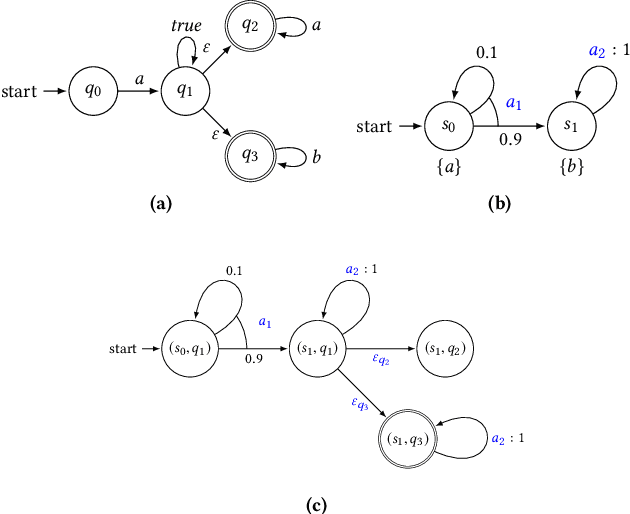
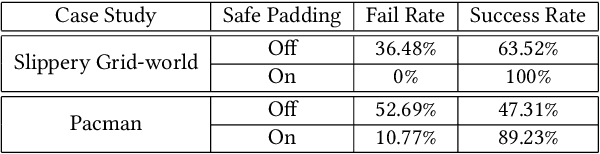
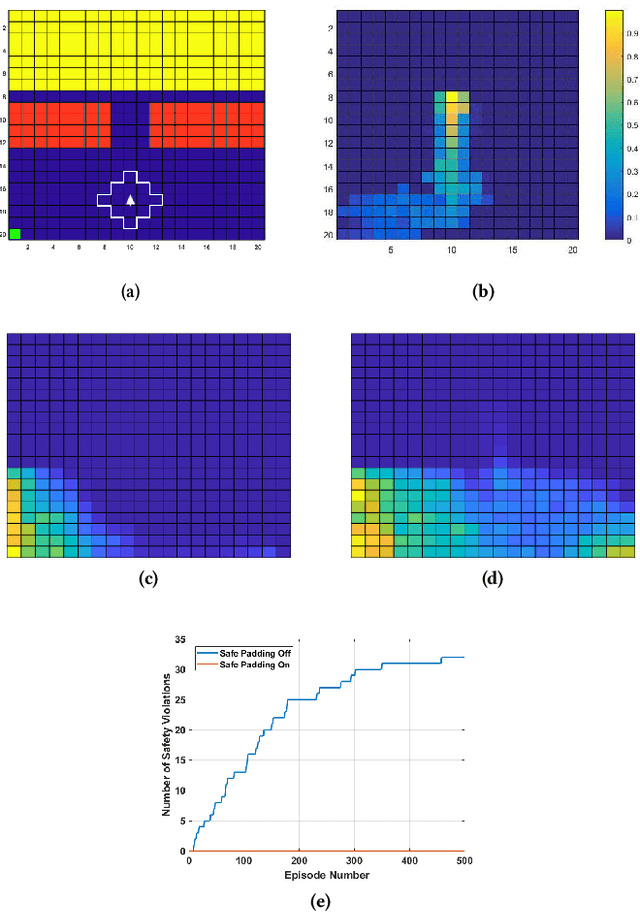
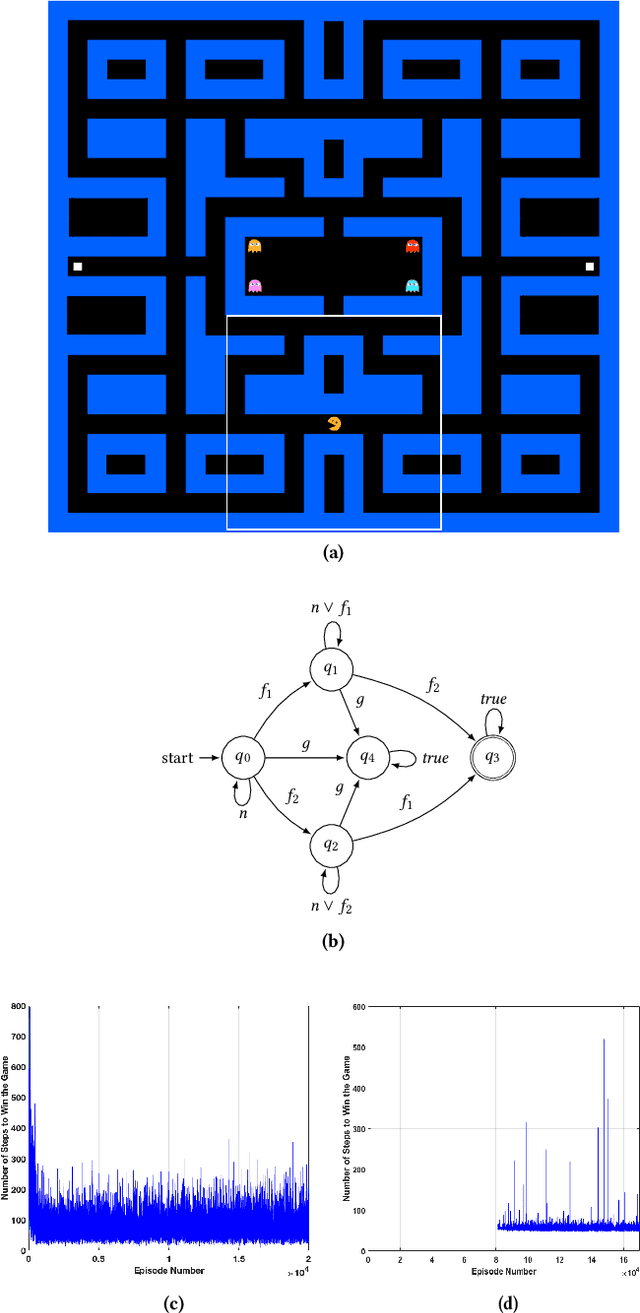
This paper presents the concept of an adaptive safe padding that forces Reinforcement Learning (RL) to synthesise optimal control policies while ensuring safety during the learning process. Policies are synthesised to satisfy a goal, expressed as a temporal logic formula, with maximal probability. Enforcing the RL agent to stay safe during learning might limit the exploration, however we show that the proposed architecture is able to automatically handle the trade-off between efficient progress in exploration (towards goal satisfaction) and ensuring safety. Theoretical guarantees are available on the optimality of the synthesised policies and on the convergence of the learning algorithm. Experimental results are provided to showcase the performance of the proposed method.
DeepSynth: Program Synthesis for Automatic Task Segmentation in Deep Reinforcement Learning
Nov 22, 2019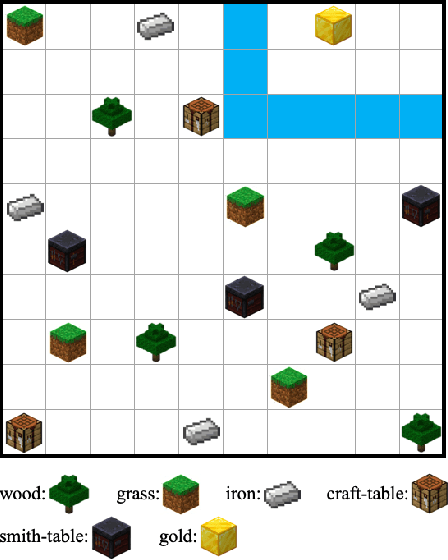
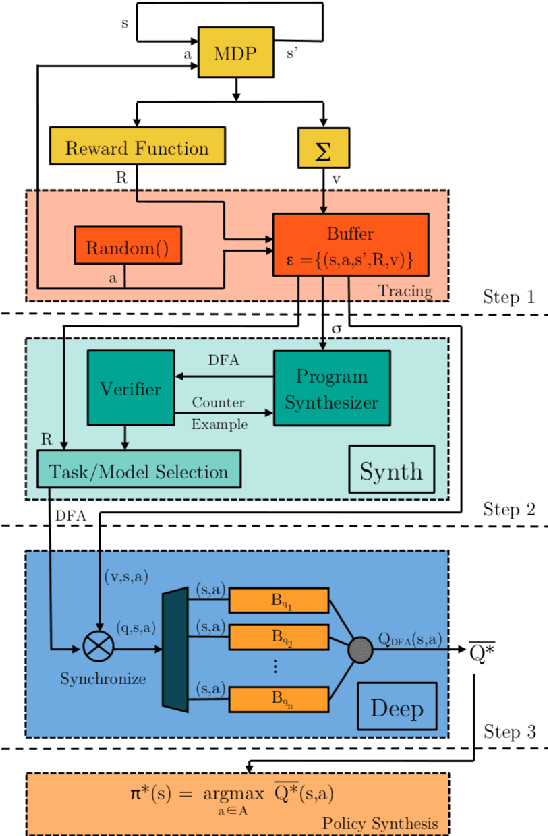
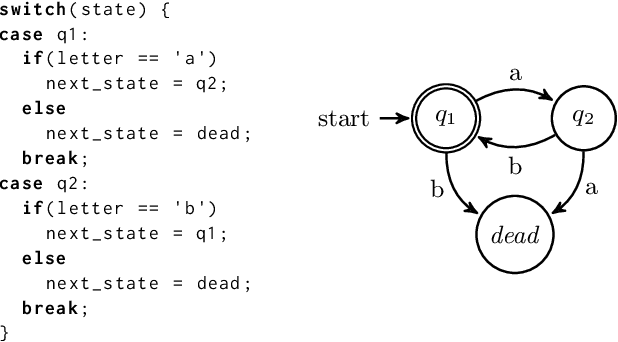
We propose a method for efficient training of deep Reinforcement Learning (RL) agents when the reward is highly sparse and non-Markovian, but at the same time admits a high-level yet unknown sequential structure, as seen in a number of video games. This high-level sequential structure can be expressed as a computer program, which our method infers automatically as the RL agent explores the environment. Through this process, a high-level sequential task that occurs only rarely may nonetheless be encoded within the inferred program. A hybrid architecture for deep neural fitted Q-iteration is then employed to fill in low-level details and generate an optimal control policy that follows the structure of the program. Our experiments show that the agent is able to synthesise a complex program to guide the RL exploitation phase, which is otherwise difficult to achieve with state-of-the-art RL techniques.
Modular Deep Reinforcement Learning with Temporal Logic Specifications
Sep 23, 2019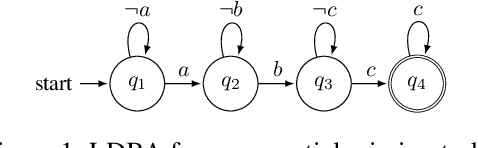
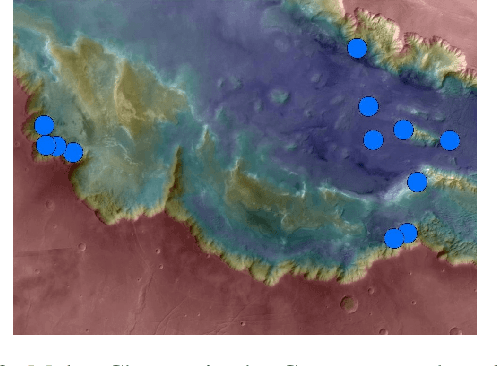

We propose an actor-critic, model-free, and online Reinforcement Learning (RL) framework for continuous-state continuous-action Markov Decision Processes (MDPs) when the reward is highly sparse but encompasses a high-level temporal structure. We represent this temporal structure by a finite-state machine and construct an on-the-fly synchronised product with the MDP and the finite machine. The temporal structure acts as a guide for the RL agent within the product, where a modular Deep Deterministic Policy Gradient (DDPG) architecture is proposed to generate a low-level control policy. We evaluate our framework in a Mars rover experiment and we present the success rate of the synthesised policy.
Reinforcement Learning for Temporal Logic Control Synthesis with Probabilistic Satisfaction Guarantees
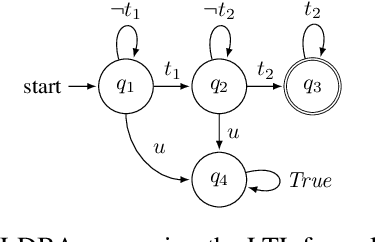
Sep 11, 2019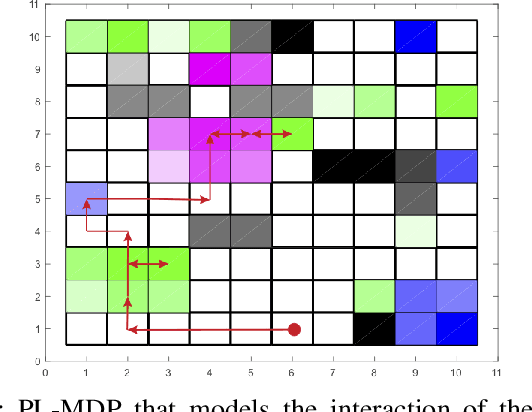

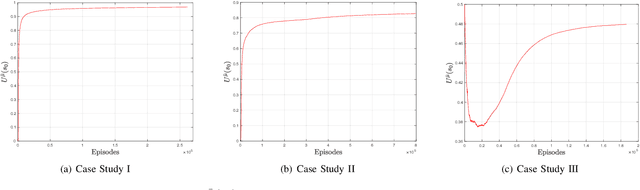
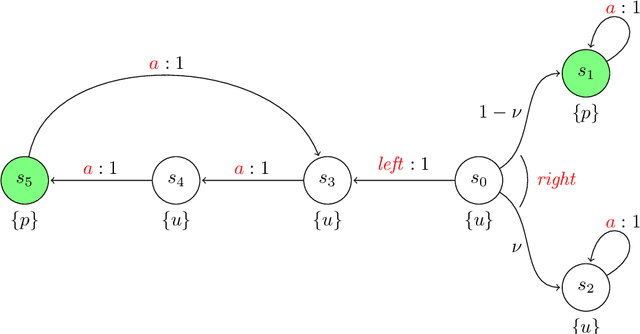
Reinforcement Learning (RL) has emerged as an efficient method of choice for solving complex sequential decision making problems in automatic control, computer science, economics, and biology. In this paper we present a model-free RL algorithm to synthesize control policies that maximize the probability of satisfying high-level control objectives given as Linear Temporal Logic (LTL) formulas. Uncertainty is considered in the workspace properties, the structure of the workspace, and the agent actions, giving rise to a Probabilistically-Labeled Markov Decision Process (PL-MDP) with unknown graph structure and stochastic behaviour, which is even more general case than a fully unknown MDP. We first translate the LTL specification into a Limit Deterministic Buchi Automaton (LDBA), which is then used in an on-the-fly product with the PL-MDP. Thereafter, we define a synchronous reward function based on the acceptance condition of the LDBA. Finally, we show that the RL algorithm delivers a policy that maximizes the satisfaction probability asymptotically. We provide experimental results that showcase the efficiency of the proposed method.
Certified Reinforcement Learning with Logic Guidance
Feb 02, 2019
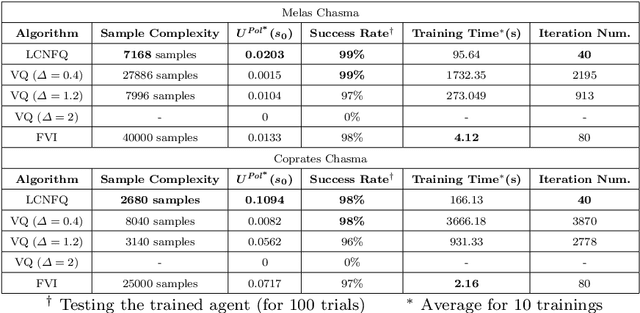
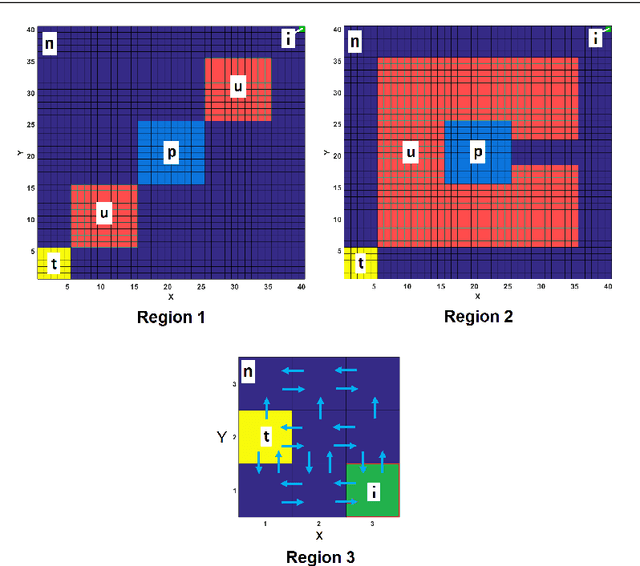

This paper proposes the first model-free Reinforcement Learning (RL) framework to synthesise policies for an unknown, and possibly continuous-state, Markov Decision Process (MDP), such that a given linear temporal property is satisfied. We convert the given property into a Limit Deterministic Buchi Automaton (LDBA), namely a finite-state machine expressing the property. Exploiting the structure of the LDBA, we shape an adaptive reward function on-the-fly, so that an RL algorithm can synthesise a policy resulting in traces that probabilistically satisfy the linear temporal property. This probability (certificate) is also calculated in parallel with learning, i.e. the RL algorithm produces a policy that is certifiably safe with respect to the property. Under the assumption that the MDP has a finite number of states, theoretical guarantees are provided on the convergence of the RL algorithm. We also show that our method produces "best available" control policies when the logical property cannot be satisfied. Whenever the MDP has a continuous state space, we empirically show that our framework finds satisfying policies, if there exist such policies. Additionally, the proposed algorithm can handle time-varying periodic environments. The performance of the proposed architecture is evaluated via a set of numerical examples and benchmarks, where we observe an improvement of one order of magnitude in the number of iterations required for the policy synthesis, compared to existing approaches whenever available.
Logically-Constrained Reinforcement Learning
Oct 22, 2018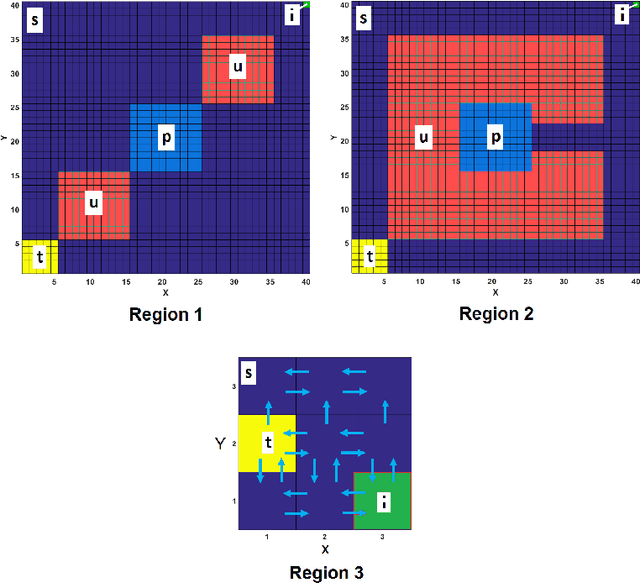


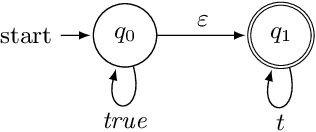
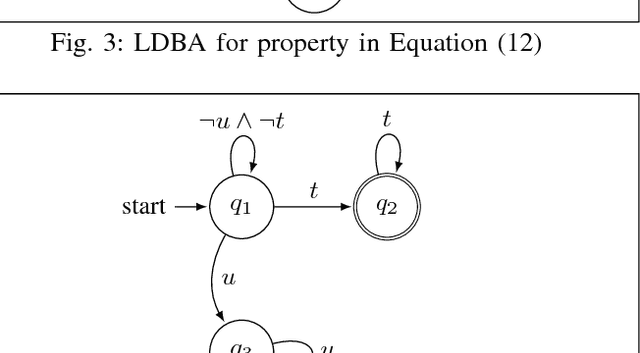
This paper proposes a model-free Reinforcement Learning (RL) algorithm to synthesise policies for an unknown Markov Decision Process (MDP), such that a linear time property is satisfied. We convert the given property into a Limit Deterministic Buchi Automaton (LDBA), then construct a synchronized MDP between the automaton and the original MDP. According to the resulting LDBA, a reward function is then defined over the state-action pairs of the product MDP. With this reward function, our algorithm synthesises a policy whose traces satisfies the linear time property: as such, the policy synthesis procedure is "constrained" by the given specification. Additionally, we show that the RL procedure sets up an online value iteration method to calculate the maximum probability of satisfying the given property, at any given state of the MDP - a convergence proof for the procedure is provided. Finally, the performance of the algorithm is evaluated via a set of numerical examples. We observe an improvement of one order of magnitude in the number of iterations required for the synthesis compared to existing approaches.
Logically-Constrained Neural Fitted Q-Iteration
Sep 20, 2018


This paper proposes a method for efficient training of the Q-function for continuous-state Markov Decision Processes (MDP), such that the traces of the resulting policies satisfy a Linear Temporal Logic (LTL) property. The logical property is converted into a limit deterministic Buchi automaton with which a product MDP is constructed. The control policy is then synthesized by a reinforcement learning algorithm assuming that no prior knowledge is available from the MDP. The proposed method is evaluated in a numerical study to test the quality of the generated control policy and is compared against conventional methods for policy synthesis such as MDP abstraction (Voronoi quantizer) and approximate dynamic programming (fitted value iteration).