Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Deep Reinforcement Learning with Temporal Logic Specifications
Sep 23, 2019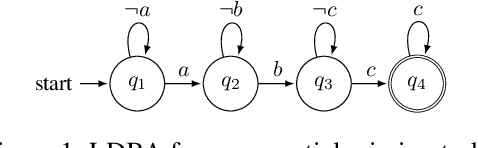
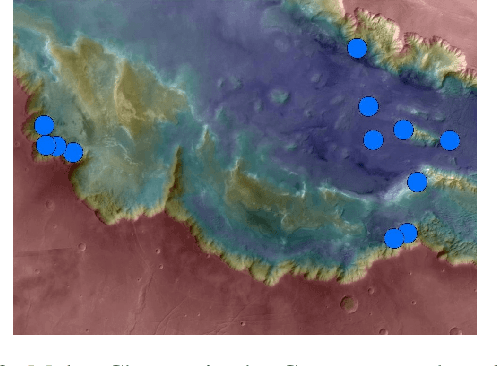

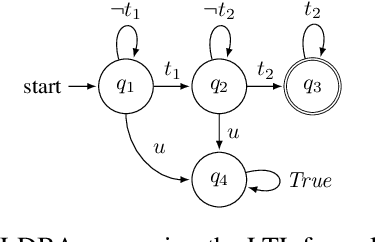
We propose an actor-critic, model-free, and online Reinforcement Learning (RL) framework for continuous-state continuous-action Markov Decision Processes (MDPs) when the reward is highly sparse but encompasses a high-level temporal structure. We represent this temporal structure by a finite-state machine and construct an on-the-fly synchronised product with the MDP and the finite machine. The temporal structure acts as a guide for the RL agent within the product, where a modular Deep Deterministic Policy Gradient (DDPG) architecture is proposed to generate a low-level control policy. We evaluate our framework in a Mars rover experiment and we present the success rate of the synthesised policy.
* arXiv admin note: text overlap with arXiv:1902.00778
Via