 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCodeAgent: A Multi-Agent Workflow for Language-agnostic Translation and Validation of Large-scale Repositories
Apr 08, 2026Most repository-level code translation and validation techniques have been evaluated on a single source-target programming language (PL) pair, owing to the complex engineering effort required to adapt new PL pairs. Programming agents can enable PL-agnosticism in repository-level code translation and validation: they can synthesize code across many PLs and autonomously use existing tools specific to each PL's analysis. However, state-of-the-art has yet to offer a fully autonomous agentic approach for repository-level code translation and validation of large-scale programs. This paper proposes ReCodeAgent, an autonomous multi-agent approach for language-agnostic repository-level code translation and validation. Users only need to provide the project in the source PL and specify the target PL for ReCodeAgent to automatically translate and validate the entire repository. ReCodeAgent is the first technique to achieve high translation success rates across many PLs. We compare the effectiveness of ReCodeAgent with four alternative neuro-symbolic and agentic approaches to translate 118 real-world projects, with 1,975 LoC and 43 translation units for each project, on average. The projects cover 6 PLs (C, Go, Java, JavaScript, Python, and Rust) and 4 PL pairs (C-Rust, Go-Rust, Java-Python, Python-JavaScript). Our results demonstrate that ReCodeAgent consistently outperforms prior techniques on translation correctness, improving test pass rate by 60.8% on ground-truth tests, with an average cost of $15.3. We also perform process-centric analysis of ReCodeAgent trajectories to confirm its procedural efficiency. Finally, we investigate how the design choices (a multi-agent vs. single-agent architecture) influence ReCodeAgent performance: on average, the test pass rate drops by 40.4%, and trajectories become 28% longer and persistently inefficient.
MatchFixAgent: Language-Agnostic Autonomous Repository-Level Code Translation Validation and Repair
Sep 19, 2025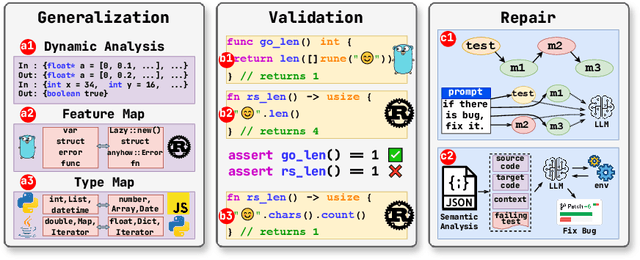



Code translation transforms source code from one programming language (PL) to another. Validating the functional equivalence of translation and repairing, if necessary, are critical steps in code translation. Existing automated validation and repair approaches struggle to generalize to many PLs due to high engineering overhead, and they rely on existing and often inadequate test suites, which results in false claims of equivalence and ineffective translation repair. We develop MatchFixAgent, a large language model (LLM)-based, PL-agnostic framework for equivalence validation and repair of translations. MatchFixAgent features a multi-agent architecture that divides equivalence validation into several sub-tasks to ensure thorough and consistent semantic analysis of the translation. Then it feeds this analysis to test agent to write and execute tests. Upon observing a test failure, the repair agent attempts to fix the translation bug. The final (in)equivalence decision is made by the verdict agent, considering semantic analyses and test execution results. We compare MatchFixAgent's validation and repair results with four repository-level code translation techniques. We use 2,219 translation pairs from their artifacts, which cover 6 PL pairs, and are collected from 24 GitHub projects totaling over 900K lines of code. Our results demonstrate that MatchFixAgent produces (in)equivalence verdicts for 99.2% of translation pairs, with the same equivalence validation result as prior work on 72.8% of them. When MatchFixAgent's result disagrees with prior work, we find that 60.7% of the time MatchFixAgent's result is actually correct. In addition, we show that MatchFixAgent can repair 50.6% of inequivalent translation, compared to prior work's 18.5%. This demonstrates that MatchFixAgent is far more adaptable to many PL pairs than prior work, while producing highly accurate validation results.
Hypergraph-Guided Regex Filter Synthesis for Event-Based Anomaly Detection
Sep 08, 2025We propose HyGLAD, a novel algorithm that automatically builds a set of interpretable patterns that model event data. These patterns can then be used to detect event-based anomalies in a stationary system, where any deviation from past behavior may indicate malicious activity. The algorithm infers equivalence classes of entities with similar behavior observed from the events, and then builds regular expressions that capture the values of those entities. As opposed to deep-learning approaches, the regular expressions are directly interpretable, which also translates to interpretable anomalies. We evaluate HyGLAD against all 7 unsupervised anomaly detection methods from DeepOD on five datasets from real-world systems. The experimental results show that on average HyGLAD outperforms existing deep-learning methods while being an order of magnitude more efficient in training and inference (single CPU vs GPU). Precision improved by 1.2x and recall by 1.3x compared to the second-best baseline.
Causal Explanations for Image Classifiers
Nov 13, 2024



Existing algorithms for explaining the output of image classifiers use different definitions of explanations and a variety of techniques to extract them. However, none of the existing tools use a principled approach based on formal definitions of causes and explanations for the explanation extraction. In this paper we present a novel black-box approach to computing explanations grounded in the theory of actual causality. We prove relevant theoretical results and present an algorithm for computing approximate explanations based on these definitions. We prove termination of our algorithm and discuss its complexity and the amount of approximation compared to the precise definition. We implemented the framework in a tool rex and we present experimental results and a comparison with state-of-the-art tools. We demonstrate that rex is the most efficient tool and produces the smallest explanations, in addition to outperforming other black-box tools on standard quality measures.
Neural Model Checking
Oct 31, 2024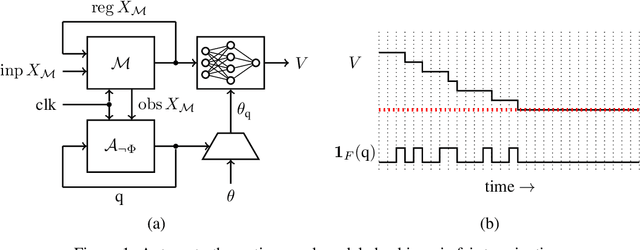



We introduce a machine learning approach to model checking temporal logic, with application to formal hardware verification. Model checking answers the question of whether every execution of a given system satisfies a desired temporal logic specification. Unlike testing, model checking provides formal guarantees. Its application is expected standard in silicon design and the EDA industry has invested decades into the development of performant symbolic model checking algorithms. Our new approach combines machine learning and symbolic reasoning by using neural networks as formal proof certificates for linear temporal logic. We train our neural certificates from randomly generated executions of the system and we then symbolically check their validity using satisfiability solving which, upon the affirmative answer, establishes that the system provably satisfies the specification. We leverage the expressive power of neural networks to represent proof certificates as well as the fact that checking a certificate is much simpler than finding one. As a result, our machine learning procedure for model checking is entirely unsupervised, formally sound, and practically effective. We experimentally demonstrate that our method outperforms the state-of-the-art academic and commercial model checkers on a set of standard hardware designs written in SystemVerilog.
Safeguarded Progress in Reinforcement Learning: Safe Bayesian Exploration for Control Policy Synthesis
Dec 18, 2023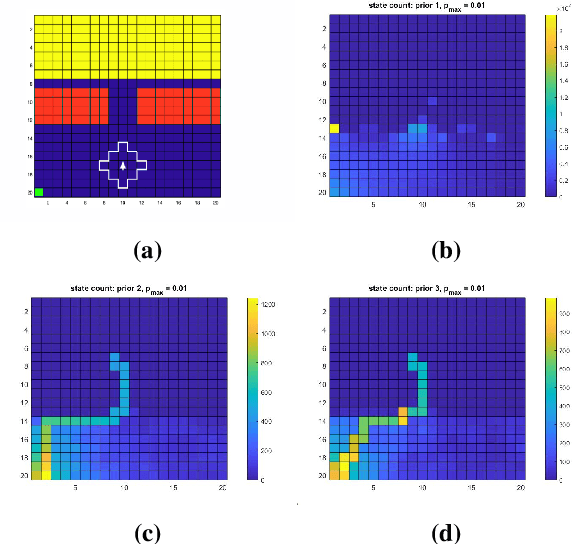
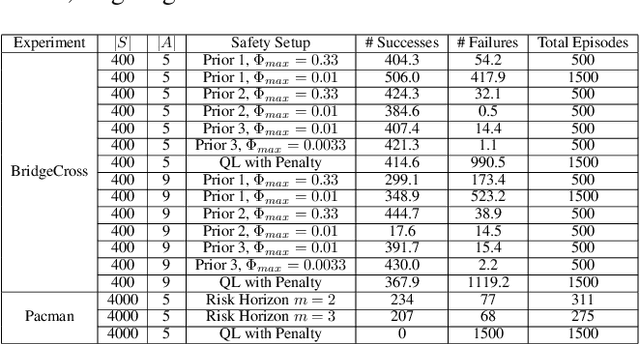
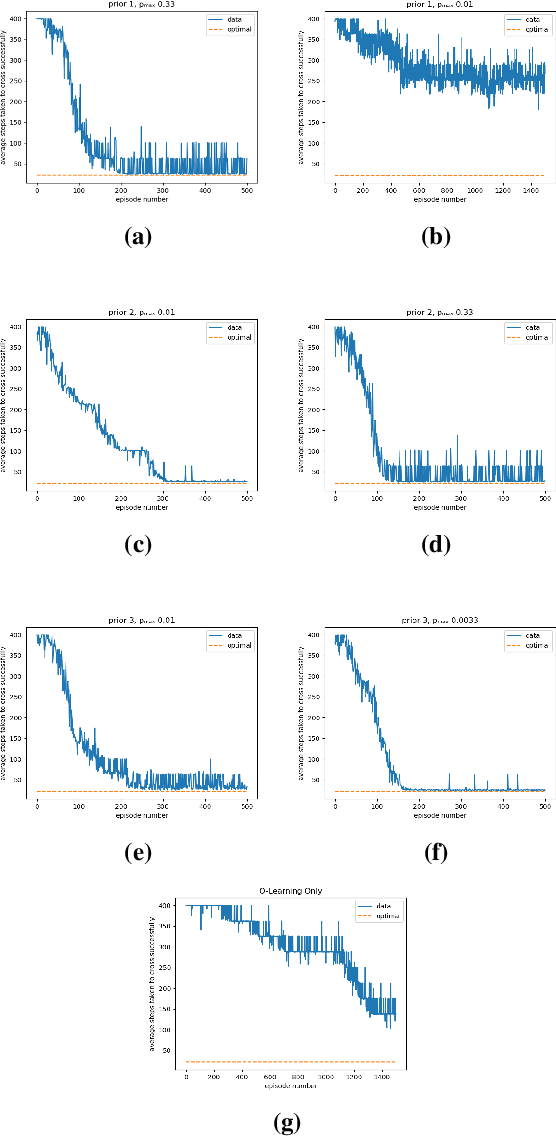
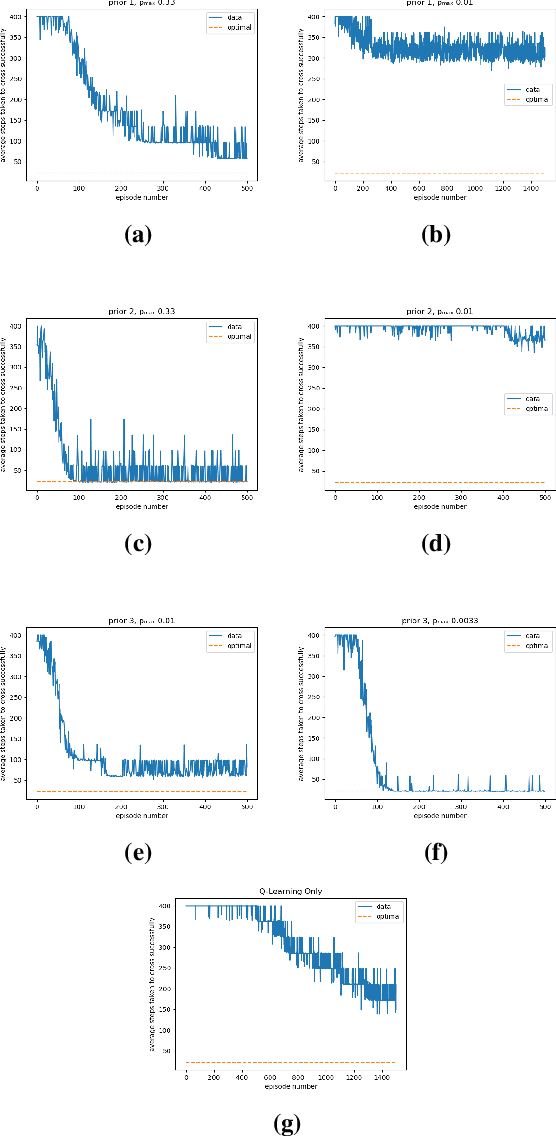
This paper addresses the problem of maintaining safety during training in Reinforcement Learning (RL), such that the safety constraint violations are bounded at any point during learning. In a variety of RL applications the safety of the agent is particularly important, e.g. autonomous platforms or robots that work in proximity of humans. As enforcing safety during training might severely limit the agent's exploration, we propose here a new architecture that handles the trade-off between efficient progress and safety during exploration. As the exploration progresses, we update via Bayesian inference Dirichlet-Categorical models of the transition probabilities of the Markov decision process that describes the environment dynamics. This paper proposes a way to approximate moments of belief about the risk associated to the action selection policy. We construct those approximations, and prove the convergence results. We propose a novel method for leveraging the expectation approximations to derive an approximate bound on the confidence that the risk is below a certain level. This approach can be easily interleaved with RL and we present experimental results to showcase the performance of the overall architecture.
You Only Explain Once
Nov 23, 2023
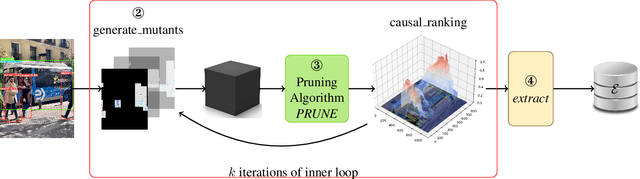


In this paper, we propose a new black-box explainability algorithm and tool, YO-ReX, for efficient explanation of the outputs of object detectors. The new algorithm computes explanations for all objects detected in the image simultaneously. Hence, compared to the baseline, the new algorithm reduces the number of queries by a factor of 10X for the case of ten detected objects. The speedup increases further with with the number of objects. Our experimental results demonstrate that YO-ReX can explain the outputs of YOLO with a negligible overhead over the running time of YOLO. We also demonstrate similar results for explaining SSD and Faster R-CNN. The speedup is achieved by avoiding backtracking by combining aggressive pruning with a causal analysis.
Multiple Different Explanations for Image Classifiers
Sep 28, 2023
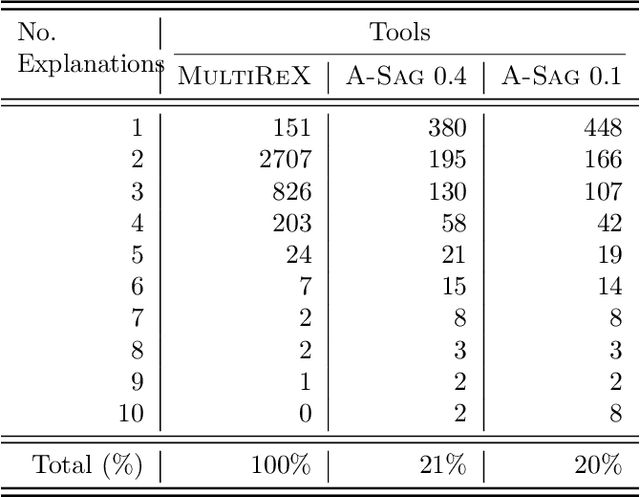

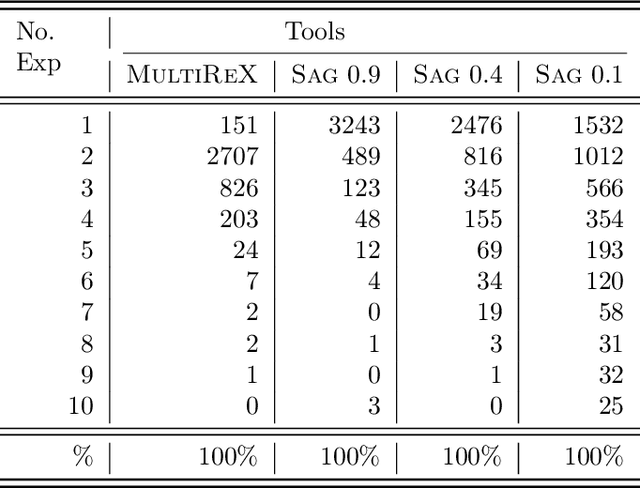
Existing explanation tools for image classifiers usually give only one single explanation for an image. For many images, however, both humans and image classifiers accept more than one explanation for the image label. Thus, restricting the number of explanations to just one severely limits the insight into the behavior of the classifier. In this paper, we describe an algorithm and a tool, REX, for computing multiple explanations of the output of a black-box image classifier for a given image. Our algorithm uses a principled approach based on causal theory. We analyse its theoretical complexity and provide experimental results showing that REX finds multiple explanations on 7 times more images than the previous work on the ImageNet-mini benchmark.
LCRL: Certified Policy Synthesis via Logically-Constrained Reinforcement Learning
Sep 21, 2022LCRL is a software tool that implements model-free Reinforcement Learning (RL) algorithms over unknown Markov Decision Processes (MDPs), synthesising policies that satisfy a given linear temporal specification with maximal probability. LCRL leverages partially deterministic finite-state machines known as Limit Deterministic Buchi Automata (LDBA) to express a given linear temporal specification. A reward function for the RL algorithm is shaped on-the-fly, based on the structure of the LDBA. Theoretical guarantees under proper assumptions ensure the convergence of the RL algorithm to an optimal policy that maximises the satisfaction probability. We present case studies to demonstrate the applicability, ease of use, scalability, and performance of LCRL. Owing to the LDBA-guided exploration and LCRL model-free architecture, we observe robust performance, which also scales well when compared to standard RL approaches (whenever applicable to LTL specifications). Full instructions on how to execute all the case studies in this paper are provided on a GitHub page that accompanies the LCRL distribution www.github.com/grockious/lcrl.
Exposing Previously Undetectable Faults in Deep Neural Networks
Jun 01, 2021


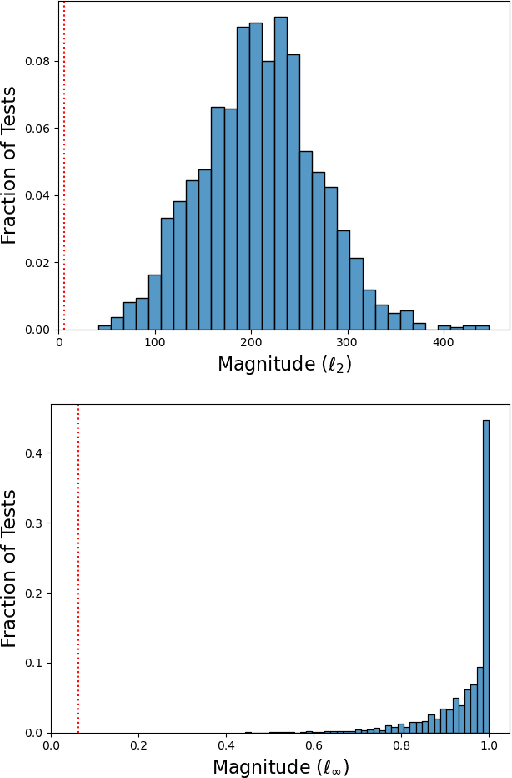
Existing methods for testing DNNs solve the oracle problem by constraining the raw features (e.g. image pixel values) to be within a small distance of a dataset example for which the desired DNN output is known. But this limits the kinds of faults these approaches are able to detect. In this paper, we introduce a novel DNN testing method that is able to find faults in DNNs that other methods cannot. The crux is that, by leveraging generative machine learning, we can generate fresh test inputs that vary in their high-level features (for images, these include object shape, location, texture, and colour). We demonstrate that our approach is capable of detecting deliberately injected faults as well as new faults in state-of-the-art DNNs, and that in both cases, existing methods are unable to find these faults.