 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Robustness in Large Language Models under Tabular Distortions
Jan 08, 2026We investigate how large language models (LLMs) fail when tabular data in an otherwise canonical representation is subjected to semantic and structural distortions. Our findings reveal that LLMs lack an inherent ability to detect and correct subtle distortions in table representations. Only when provided with an explicit prior, via a system prompt, do models partially adjust their reasoning strategies and correct some distortions, though not consistently or completely. To study this phenomenon, we introduce a small, expert-curated dataset that explicitly evaluates LLMs on table question answering (TQA) tasks requiring an additional error-correction step prior to analysis. Our results reveal systematic differences in how LLMs ingest and interpret tabular information under distortion, with even SoTA models such as GPT-5.2 model exhibiting a drop of minimum 22% accuracy under distortion. These findings raise important questions for future research, particularly regarding when and how models should autonomously decide to realign tabular inputs, analogous to human behavior, without relying on explicit prompts or tabular data pre-processing.
Soft-Label Training Preserves Epistemic Uncertainty
Nov 18, 2025Many machine learning tasks involve inherent subjectivity, where annotators naturally provide varied labels. Standard practice collapses these label distributions into single labels, aggregating diverse human judgments into point estimates. We argue that this approach is epistemically misaligned for ambiguous data--the annotation distribution itself should be regarded as the ground truth. Training on collapsed single labels forces models to express false confidence on fundamentally ambiguous cases, creating a misalignment between model certainty and the diversity of human perception. We demonstrate empirically that soft-label training, which treats annotation distributions as ground truth, preserves epistemic uncertainty. Across both vision and NLP tasks, soft-label training achieves 32% lower KL divergence from human annotations and 61% stronger correlation between model and annotation entropy, while matching the accuracy of hard-label training. Our work repositions annotation distributions from noisy signals to be aggregated away, to faithful representations of epistemic uncertainty that models should learn to reproduce.
Progressive Safeguards for Safe and Model-Agnostic Reinforcement Learning
Oct 31, 2024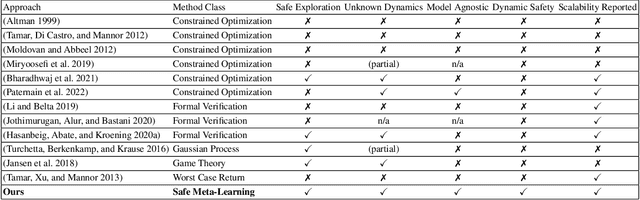


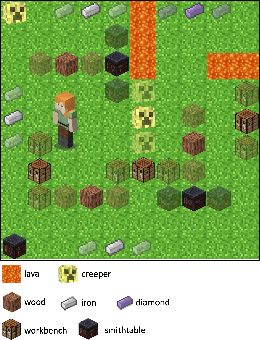
In this paper we propose a formal, model-agnostic meta-learning framework for safe reinforcement learning. Our framework is inspired by how parents safeguard their children across a progression of increasingly riskier tasks, imparting a sense of safety that is carried over from task to task. We model this as a meta-learning process where each task is synchronized with a safeguard that monitors safety and provides a reward signal to the agent. The safeguard is implemented as a finite-state machine based on a safety specification; the reward signal is formally shaped around this specification. The safety specification and its corresponding safeguard can be arbitrarily complex and non-Markovian, which adds flexibility to the training process and explainability to the learned policy. The design of the safeguard is manual but it is high-level and model-agnostic, which gives rise to an end-to-end safe learning approach with wide applicability, from pixel-level game control to language model fine-tuning. Starting from a given set of safety specifications (tasks), we train a model such that it can adapt to new specifications using only a small number of training samples. This is made possible by our method for efficiently transferring safety bias between tasks, which effectively minimizes the number of safety violations. We evaluate our framework in a Minecraft-inspired Gridworld, a VizDoom game environment, and an LLM fine-tuning application. Agents trained with our approach achieve near-minimal safety violations, while baselines are shown to underperform.
Safeguarded Progress in Reinforcement Learning: Safe Bayesian Exploration for Control Policy Synthesis
Dec 18, 2023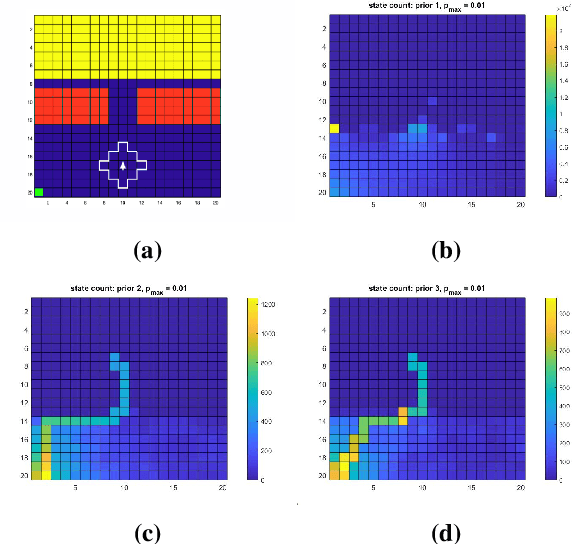
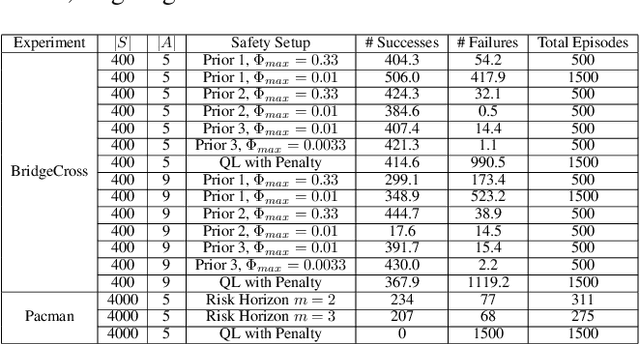
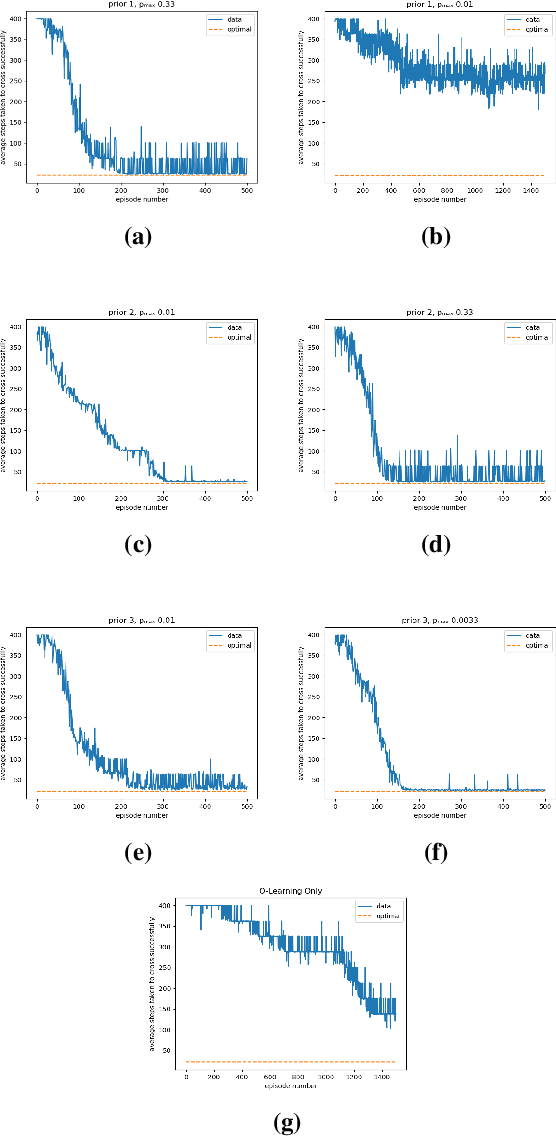
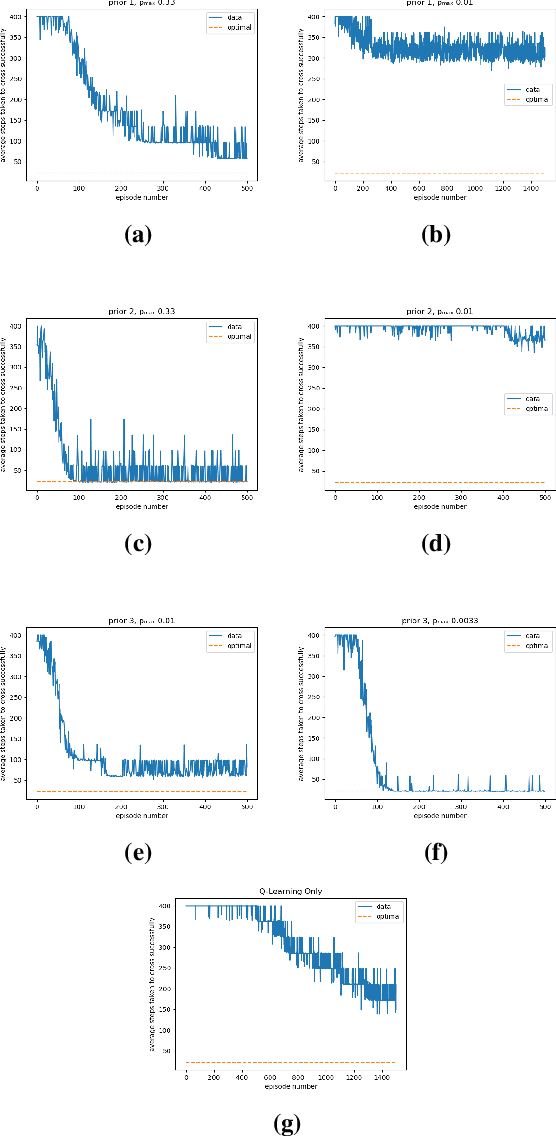
This paper addresses the problem of maintaining safety during training in Reinforcement Learning (RL), such that the safety constraint violations are bounded at any point during learning. In a variety of RL applications the safety of the agent is particularly important, e.g. autonomous platforms or robots that work in proximity of humans. As enforcing safety during training might severely limit the agent's exploration, we propose here a new architecture that handles the trade-off between efficient progress and safety during exploration. As the exploration progresses, we update via Bayesian inference Dirichlet-Categorical models of the transition probabilities of the Markov decision process that describes the environment dynamics. This paper proposes a way to approximate moments of belief about the risk associated to the action selection policy. We construct those approximations, and prove the convergence results. We propose a novel method for leveraging the expectation approximations to derive an approximate bound on the confidence that the risk is below a certain level. This approach can be easily interleaved with RL and we present experimental results to showcase the performance of the overall architecture.
Mission-driven Exploration for Accelerated Deep Reinforcement Learning with Temporal Logic Task Specifications
Nov 28, 2023


This paper addresses the problem of designing optimal control policies for mobile robots with mission and safety requirements specified using Linear Temporal Logic (LTL). We consider robots with unknown stochastic dynamics operating in environments with unknown geometric structure. The robots are equipped with sensors allowing them to detect obstacles. Our goal is to synthesize a control policy that maximizes the probability of satisfying an LTL-encoded task in the presence of motion and environmental uncertainty. Several deep reinforcement learning (DRL) algorithms have been proposed recently to address similar problems. A common limitation in related works is that of slow learning performance. In order to address this issue, we propose a novel DRL algorithm, which has the capability to learn control policies at a notably faster rate compared to similar methods. Its sample efficiency is due to a mission-driven exploration strategy that prioritizes exploration towards directions that may contribute to mission accomplishment. Identifying these directions relies on an automaton representation of the LTL task as well as a learned neural network that (partially) models the unknown system dynamics. We provide comparative experiments demonstrating the efficiency of our algorithm on robot navigation tasks in unknown environments.
In-Context Learning in Large Language Models: A Neuroscience-inspired Analysis of Representations
Oct 18, 2023



Large language models (LLMs) exhibit remarkable performance improvement through in-context learning (ICL) by leveraging task-specific examples in the input. However, the mechanisms behind this improvement remain elusive. In this work, we investigate embeddings and attention representations in Llama-2 70B and Vicuna 13B. Specifically, we study how embeddings and attention change after in-context-learning, and how these changes mediate improvement in behavior. We employ neuroscience-inspired techniques, such as representational similarity analysis (RSA), and propose novel methods for parameterized probing and attention ratio analysis (ARA, measuring the ratio of attention to relevant vs. irrelevant information). We designed three tasks with a priori relationships among their conditions: reading comprehension, linear regression, and adversarial prompt injection. We formed hypotheses about expected similarities in task representations to investigate latent changes in embeddings and attention. Our analyses revealed a meaningful correlation between changes in both embeddings and attention representations with improvements in behavioral performance after ICL. This empirical framework empowers a nuanced understanding of how latent representations affect LLM behavior with and without ICL, offering valuable tools and insights for future research and practical applications.
ALLURE: Auditing and Improving LLM-based Evaluation of Text using Iterative In-Context-Learning
Sep 27, 2023



From grading papers to summarizing medical documents, large language models (LLMs) are evermore used for evaluation of text generated by humans and AI alike. However, despite their extensive utility, LLMs exhibit distinct failure modes, necessitating a thorough audit and improvement of their text evaluation capabilities. Here we introduce ALLURE, a systematic approach to Auditing Large Language Models Understanding and Reasoning Errors. ALLURE involves comparing LLM-generated evaluations with annotated data, and iteratively incorporating instances of significant deviation into the evaluator, which leverages in-context learning (ICL) to enhance and improve robust evaluation of text by LLMs. Through this iterative process, we refine the performance of the evaluator LLM, ultimately reducing reliance on human annotators in the evaluation process. We anticipate ALLURE to serve diverse applications of LLMs in various domains related to evaluation of textual data, such as medical summarization, education, and and productivity.
Evaluating Cognitive Maps and Planning in Large Language Models with CogEval
Sep 25, 2023


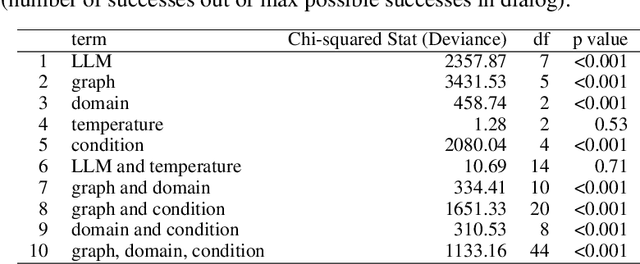
Recently an influx of studies claim emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions. First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and getting trapped in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.
LCRL: Certified Policy Synthesis via Logically-Constrained Reinforcement Learning
Sep 21, 2022LCRL is a software tool that implements model-free Reinforcement Learning (RL) algorithms over unknown Markov Decision Processes (MDPs), synthesising policies that satisfy a given linear temporal specification with maximal probability. LCRL leverages partially deterministic finite-state machines known as Limit Deterministic Buchi Automata (LDBA) to express a given linear temporal specification. A reward function for the RL algorithm is shaped on-the-fly, based on the structure of the LDBA. Theoretical guarantees under proper assumptions ensure the convergence of the RL algorithm to an optimal policy that maximises the satisfaction probability. We present case studies to demonstrate the applicability, ease of use, scalability, and performance of LCRL. Owing to the LDBA-guided exploration and LCRL model-free architecture, we observe robust performance, which also scales well when compared to standard RL approaches (whenever applicable to LTL specifications). Full instructions on how to execute all the case studies in this paper are provided on a GitHub page that accompanies the LCRL distribution www.github.com/grockious/lcrl.