 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk the Talk? Measuring the Faithfulness of Large Language Model Explanations
Apr 19, 2025Large language models (LLMs) are capable of generating plausible explanations of how they arrived at an answer to a question. However, these explanations can misrepresent the model's "reasoning" process, i.e., they can be unfaithful. This, in turn, can lead to over-trust and misuse. We introduce a new approach for measuring the faithfulness of LLM explanations. First, we provide a rigorous definition of faithfulness. Since LLM explanations mimic human explanations, they often reference high-level concepts in the input question that purportedly influenced the model. We define faithfulness in terms of the difference between the set of concepts that LLM explanations imply are influential and the set that truly are. Second, we present a novel method for estimating faithfulness that is based on: (1) using an auxiliary LLM to modify the values of concepts within model inputs to create realistic counterfactuals, and (2) using a Bayesian hierarchical model to quantify the causal effects of concepts at both the example- and dataset-level. Our experiments show that our method can be used to quantify and discover interpretable patterns of unfaithfulness. On a social bias task, we uncover cases where LLM explanations hide the influence of social bias. On a medical question answering task, we uncover cases where LLM explanations provide misleading claims about which pieces of evidence influenced the model's decisions.
MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering
Jun 03, 2024

Large language models (LLM) have achieved impressive performance on medical question-answering benchmarks. However, high benchmark accuracy does not imply that the performance generalizes to real-world clinical settings. Medical question-answering benchmarks rely on assumptions consistent with quantifying LLM performance but that may not hold in the open world of the clinic. Yet LLMs learn broad knowledge that can help the LLM generalize to practical conditions regardless of unrealistic assumptions in celebrated benchmarks. We seek to quantify how well LLM medical question-answering benchmark performance generalizes when benchmark assumptions are violated. Specifically, we present an adversarial method that we call MedFuzz (for medical fuzzing). MedFuzz attempts to modify benchmark questions in ways aimed at confounding the LLM. We demonstrate the approach by targeting strong assumptions about patient characteristics presented in the MedQA benchmark. Successful "attacks" modify a benchmark item in ways that would be unlikely to fool a medical expert but nonetheless "trick" the LLM into changing from a correct to an incorrect answer. Further, we present a permutation test technique that can ensure a successful attack is statistically significant. We show how to use performance on a "MedFuzzed" benchmark, as well as individual successful attacks. The methods show promise at providing insights into the ability of an LLM to operate robustly in more realistic settings.
Physics-Based Causal Reasoning for Safe & Robust Next-Best Action Selection in Robot Manipulation Tasks
Mar 21, 2024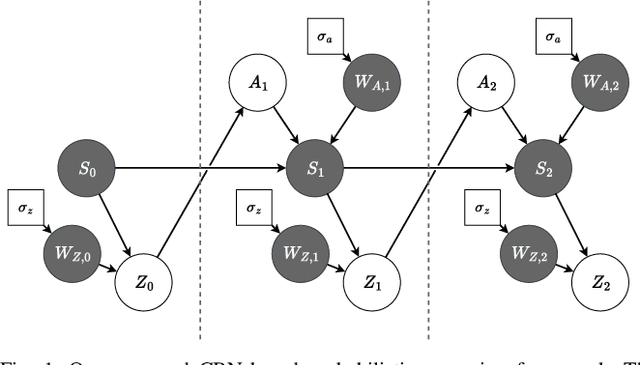

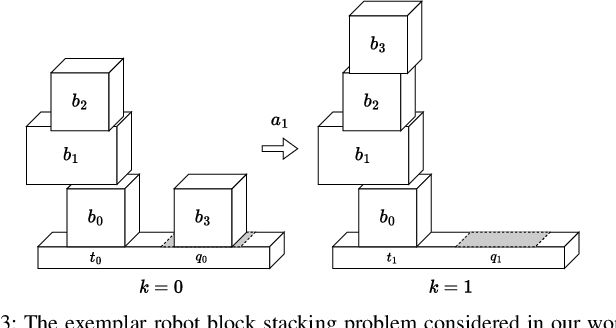
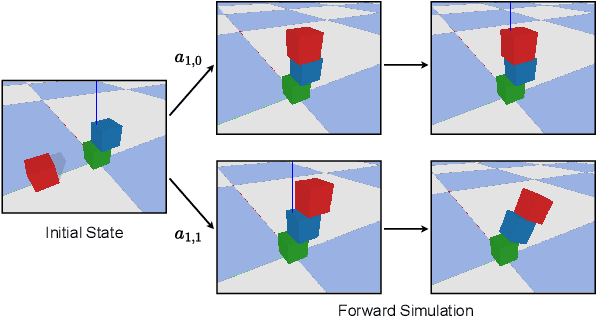
Safe and efficient object manipulation is a key enabler of many real-world robot applications. However, this is challenging because robot operation must be robust to a range of sensor and actuator uncertainties. In this paper, we present a physics-informed causal-inference-based framework for a robot to probabilistically reason about candidate actions in a block stacking task in a partially observable setting. We integrate a physics-based simulation of the rigid-body system dynamics with a causal Bayesian network (CBN) formulation to define a causal generative probabilistic model of the robot decision-making process. Using simulation-based Monte Carlo experiments, we demonstrate our framework's ability to successfully: (1) predict block tower stability with high accuracy (Pred Acc: 88.6%); and, (2) select an approximate next-best action for the block stacking task, for execution by an integrated robot system, achieving 94.2% task success rate. We also demonstrate our framework's suitability for real-world robot systems by demonstrating successful task executions with a domestic support robot, with perception and manipulation sub-system integration. Hence, we show that by embedding physics-based causal reasoning into robots' decision-making processes, we can make robot task execution safer, more reliable, and more robust to various types of uncertainty.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023
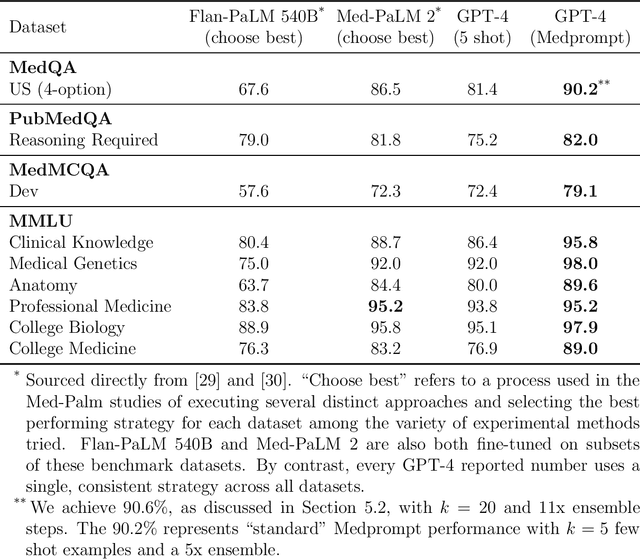


Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Evaluating Cognitive Maps and Planning in Large Language Models with CogEval
Sep 25, 2023


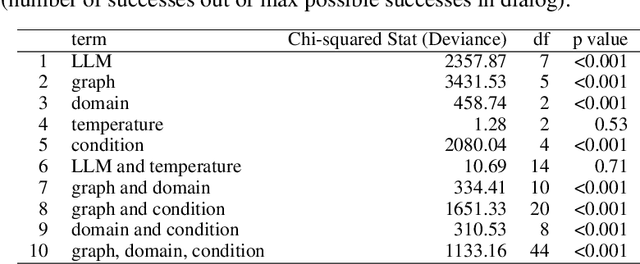
Recently an influx of studies claim emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions. First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and getting trapped in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.
Integrating Markov processes with structural causal modeling enables counterfactual inference in complex systems
Nov 06, 2019
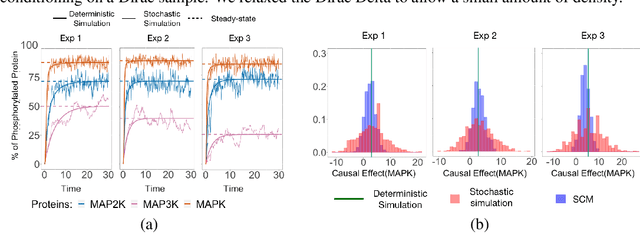
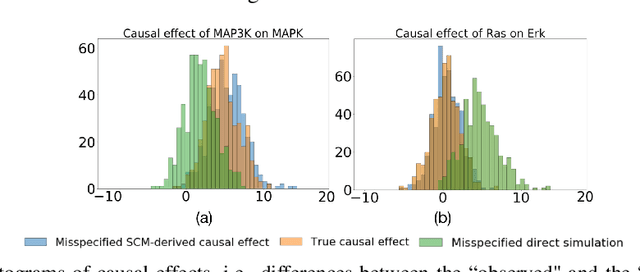
This manuscript contributes a general and practical framework for casting a Markov process model of a system at equilibrium as a structural causal model, and carrying out counterfactual inference. Markov processes mathematically describe the mechanisms in the system, and predict the system's equilibrium behavior upon intervention, but do not support counterfactual inference. In contrast, structural causal models support counterfactual inference, but do not identify the mechanisms. This manuscript leverages the benefits of both approaches. We define the structural causal models in terms of the parameters and the equilibrium dynamics of the Markov process models, and counterfactual inference flows from these settings. The proposed approach alleviates the identifiability drawback of the structural causal models, in that the counterfactual inference is consistent with the counterfactual trajectories simulated from the Markov process model. We showcase the benefits of this framework in case studies of complex biomolecular systems with nonlinear dynamics. We illustrate that, in presence of Markov process model misspecification, counterfactual inference leverages prior data, and therefore estimates the outcome of an intervention more accurately than a direct simulation.