 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCancerGUIDE: Cancer Guideline Understanding via Internal Disagreement Estimation
Sep 09, 2025
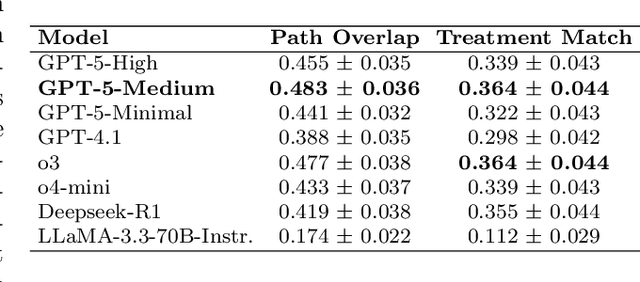
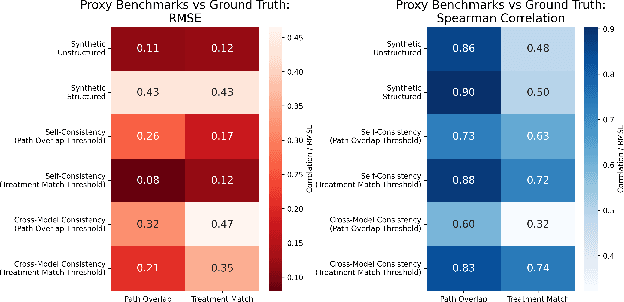

The National Comprehensive Cancer Network (NCCN) provides evidence-based guidelines for cancer treatment. Translating complex patient presentations into guideline-compliant treatment recommendations is time-intensive, requires specialized expertise, and is prone to error. Advances in large language model (LLM) capabilities promise to reduce the time required to generate treatment recommendations and improve accuracy. We present an LLM agent-based approach to automatically generate guideline-concordant treatment trajectories for patients with non-small cell lung cancer (NSCLC). Our contributions are threefold. First, we construct a novel longitudinal dataset of 121 cases of NSCLC patients that includes clinical encounters, diagnostic results, and medical histories, each expertly annotated with the corresponding NCCN guideline trajectories by board-certified oncologists. Second, we demonstrate that existing LLMs possess domain-specific knowledge that enables high-quality proxy benchmark generation for both model development and evaluation, achieving strong correlation (Spearman coefficient r=0.88, RMSE = 0.08) with expert-annotated benchmarks. Third, we develop a hybrid approach combining expensive human annotations with model consistency information to create both the agent framework that predicts the relevant guidelines for a patient, as well as a meta-classifier that verifies prediction accuracy with calibrated confidence scores for treatment recommendations (AUROC=0.800), a critical capability for communicating the accuracy of outputs, custom-tailoring tradeoffs in performance, and supporting regulatory compliance. This work establishes a framework for clinically viable LLM-based guideline adherence systems that balance accuracy, interpretability, and regulatory requirements while reducing annotation costs, providing a scalable pathway toward automated clinical decision support.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Creating General User Models from Computer Use
May 19, 2025Human-computer interaction has long imagined technology that understands us-from our preferences and habits, to the timing and purpose of our everyday actions. Yet current user models remain fragmented, narrowly tailored to specific apps, and incapable of the flexible reasoning required to fulfill these visions. This paper presents an architecture for a general user model (GUM) that learns about you by observing any interaction you have with your computer. The GUM takes as input any unstructured observation of a user (e.g., device screenshots) and constructs confidence-weighted propositions that capture user knowledge and preferences. GUMs can infer that a user is preparing for a wedding they're attending from messages with a friend. Or recognize that a user is struggling with a collaborator's feedback on a draft by observing multiple stalled edits and a switch to reading related work. GUMs introduce an architecture that infers new propositions about a user from multimodal observations, retrieves related propositions for context, and continuously revises existing propositions. To illustrate the breadth of applications that GUMs enable, we demonstrate how they augment chat-based assistants with context, manage OS notifications to selectively surface important information, and enable interactive agents that adapt to preferences across apps. We also instantiate proactive assistants (GUMBOs) that discover and execute useful suggestions on a user's behalf using their GUM. In our evaluations, we find that GUMs make calibrated and accurate inferences about users, and that assistants built on GUMs proactively identify and perform actions that users wouldn't think to request explicitly. Altogether, GUMs introduce methods that leverage multimodal models to understand unstructured context, enabling long-standing visions of HCI and entirely new interactive systems that anticipate user needs.
Navigating Rifts in Human-LLM Grounding: Study and Benchmark
Mar 18, 2025Language models excel at following instructions but often struggle with the collaborative aspects of conversation that humans naturally employ. This limitation in grounding -- the process by which conversation participants establish mutual understanding -- can lead to outcomes ranging from frustrated users to serious consequences in high-stakes scenarios. To systematically study grounding challenges in human-LLM interactions, we analyze logs from three human-assistant datasets: WildChat, MultiWOZ, and Bing Chat. We develop a taxonomy of grounding acts and build models to annotate and forecast grounding behavior. Our findings reveal significant differences in human-human and human-LLM grounding: LLMs were three times less likely to initiate clarification and sixteen times less likely to provide follow-up requests than humans. Additionally, early grounding failures predicted later interaction breakdowns. Building on these insights, we introduce RIFTS: a benchmark derived from publicly available LLM interaction data containing situations where LLMs fail to initiate grounding. We note that current frontier models perform poorly on RIFTS, highlighting the need to reconsider how we train and prompt LLMs for human interaction. To this end, we develop a preliminary intervention that mitigates grounding failures.
Generating Structured Outputs from Language Models: Benchmark and Studies
Jan 18, 2025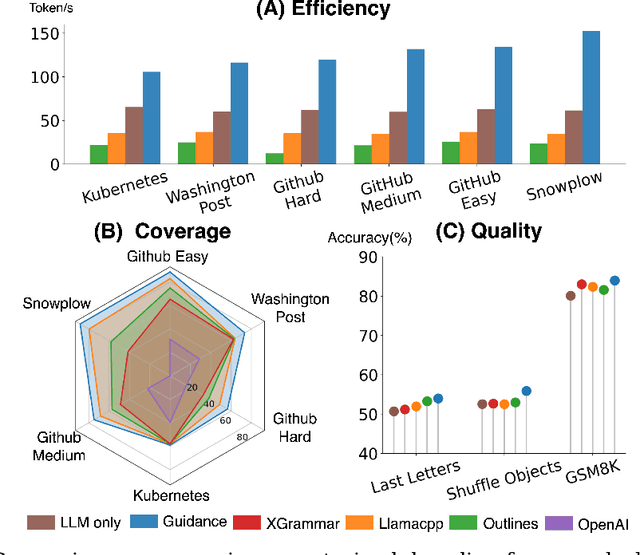
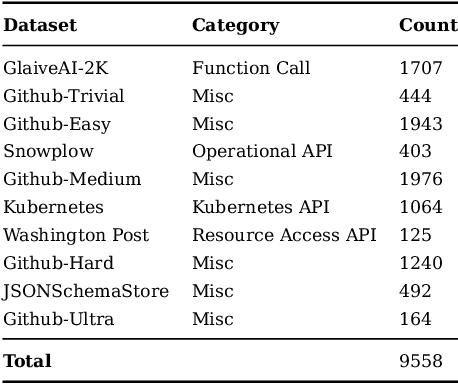
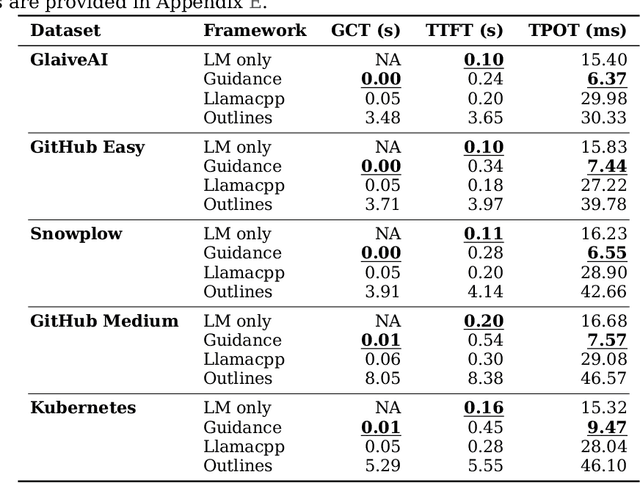
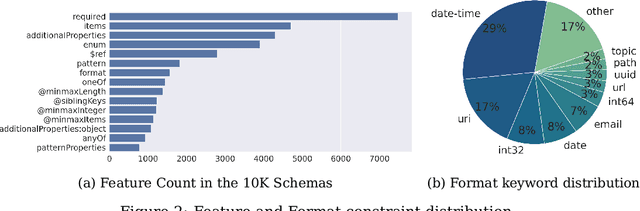
Reliably generating structured outputs has become a critical capability for modern language model (LM) applications. Constrained decoding has emerged as the dominant technology across sectors for enforcing structured outputs during generation. Despite its growing adoption, little has been done with the systematic evaluation of the behaviors and performance of constrained decoding. Constrained decoding frameworks have standardized around JSON Schema as a structured data format, with most uses guaranteeing constraint compliance given a schema. However, there is poor understanding of the effectiveness of the methods in practice. We present an evaluation framework to assess constrained decoding approaches across three critical dimensions: efficiency in generating constraint-compliant outputs, coverage of diverse constraint types, and quality of the generated outputs. To facilitate this evaluation, we introduce JSONSchemaBench, a benchmark for constrained decoding comprising 10K real-world JSON schemas that encompass a wide range of constraints with varying complexity. We pair the benchmark with the existing official JSON Schema Test Suite and evaluate six state-of-the-art constrained decoding frameworks, including Guidance, Outlines, Llamacpp, XGrammar, OpenAI, and Gemini. Through extensive experiments, we gain insights into the capabilities and limitations of constrained decoding on structured generation with real-world JSON schemas. Our work provides actionable insights for improving constrained decoding frameworks and structured generation tasks, setting a new standard for evaluating constrained decoding and structured generation. We release JSONSchemaBench at https://github.com/guidance-ai/jsonschemabench
Superhuman performance of a large language model on the reasoning tasks of a physician
Dec 14, 2024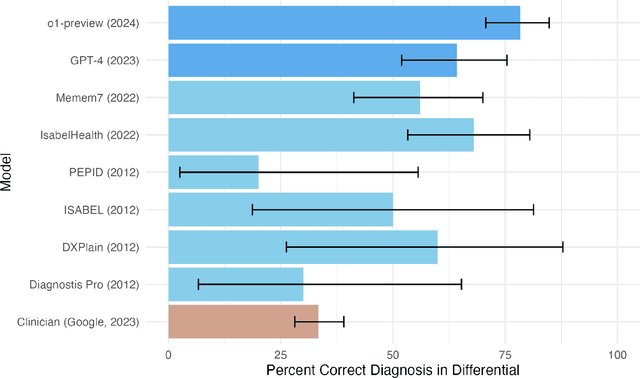
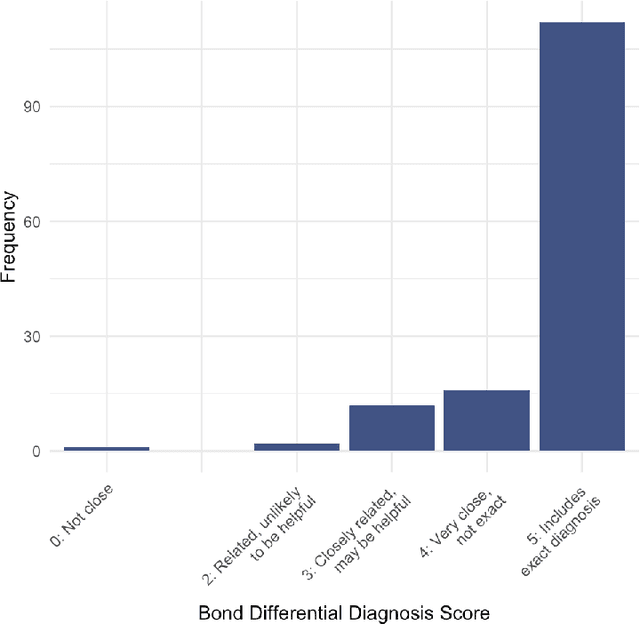

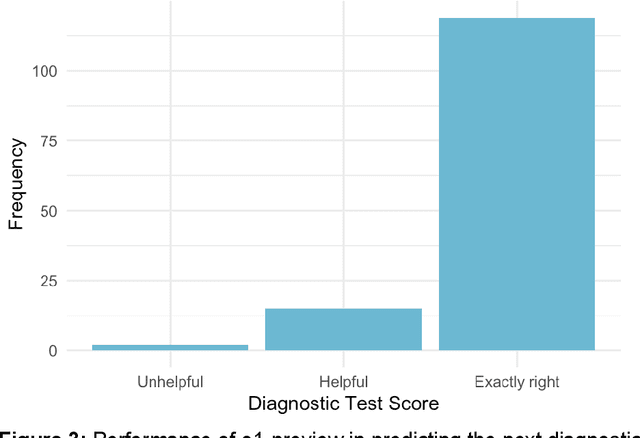
Performance of large language models (LLMs) on medical tasks has traditionally been evaluated using multiple choice question benchmarks. However, such benchmarks are highly constrained, saturated with repeated impressive performance by LLMs, and have an unclear relationship to performance in real clinical scenarios. Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance. Prior LLMs have shown promise in outperforming clinicians in routine and complex diagnostic scenarios. We sought to evaluate OpenAI's o1-preview model, a model developed to increase run-time via chain of thought processes prior to generating a response. We characterize the performance of o1-preview with five experiments including differential diagnosis generation, display of diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics. Our primary outcome was comparison of the o1-preview output to identical prior experiments that have historical human controls and benchmarks of previous LLMs. Significant improvements were observed with differential diagnosis generation and quality of diagnostic and management reasoning. No improvements were observed with probabilistic reasoning or triage differential diagnosis. This study highlights o1-preview's ability to perform strongly on tasks that require complex critical thinking such as diagnosis and management while its performance on probabilistic reasoning tasks was similar to past models. New robust benchmarks and scalable evaluation of LLM capabilities compared to human physicians are needed along with trials evaluating AI in real clinical settings.
Steering Language Model Refusal with Sparse Autoencoders
Nov 18, 2024



Responsible practices for deploying language models include guiding models to recognize and refuse answering prompts that are considered unsafe, while complying with safe prompts. Achieving such behavior typically requires updating model weights, which is costly and inflexible. We explore opportunities to steering model activations at inference time, which does not require updating weights. Using sparse autoencoders, we identify and steer features in Phi-3 Mini that mediate refusal behavior. We find that feature steering can improve Phi-3 Minis robustness to jailbreak attempts across various harms, including challenging multi-turn attacks. However, we discover that feature steering can adversely affect overall performance on benchmarks. These results suggest that identifying steerable mechanisms for refusal via sparse autoencoders is a promising approach for enhancing language model safety, but that more research is needed to mitigate feature steerings adverse effects on performance.
From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond
Nov 06, 2024



Run-time steering strategies like Medprompt are valuable for guiding large language models (LLMs) to top performance on challenging tasks. Medprompt demonstrates that a general LLM can be focused to deliver state-of-the-art performance on specialized domains like medicine by using a prompt to elicit a run-time strategy involving chain of thought reasoning and ensembling. OpenAI's o1-preview model represents a new paradigm, where a model is designed to do run-time reasoning before generating final responses. We seek to understand the behavior of o1-preview on a diverse set of medical challenge problem benchmarks. Following on the Medprompt study with GPT-4, we systematically evaluate the o1-preview model across various medical benchmarks. Notably, even without prompting techniques, o1-preview largely outperforms the GPT-4 series with Medprompt. We further systematically study the efficacy of classic prompt engineering strategies, as represented by Medprompt, within the new paradigm of reasoning models. We found that few-shot prompting hinders o1's performance, suggesting that in-context learning may no longer be an effective steering approach for reasoning-native models. While ensembling remains viable, it is resource-intensive and requires careful cost-performance optimization. Our cost and accuracy analysis across run-time strategies reveals a Pareto frontier, with GPT-4o representing a more affordable option and o1-preview achieving state-of-the-art performance at higher cost. Although o1-preview offers top performance, GPT-4o with steering strategies like Medprompt retains value in specific contexts. Moreover, we note that the o1-preview model has reached near-saturation on many existing medical benchmarks, underscoring the need for new, challenging benchmarks. We close with reflections on general directions for inference-time computation with LLMs.
Decision-Focused Uncertainty Quantification
Oct 02, 2024There is increasing interest in ''decision-focused'' machine learning methods which train models to account for how their predictions are used in downstream optimization problems. Doing so can often improve performance on subsequent decision problems. However, current methods for uncertainty quantification do not incorporate any information at all about downstream decisions. We develop a framework based on conformal prediction to produce prediction sets that account for a downstream decision loss function, making them more appropriate to inform high-stakes decision-making. Our approach harnesses the strengths of conformal methods--modularity, model-agnosticism, and statistical coverage guarantees--while incorporating downstream decisions and user-specified utility functions. We prove that our methods retain standard coverage guarantees. Empirical evaluation across a range of datasets and utility metrics demonstrates that our methods achieve significantly lower decision loss compared to standard conformal methods. Additionally, we present a real-world use case in healthcare diagnosis, where our method effectively incorporates the hierarchical structure of dermatological diseases. It successfully generates sets with coherent diagnostic meaning, aiding the triage process during dermatology diagnosis and illustrating how our method can ground high-stakes decision-making on external domain knowledge.
How to Build the Virtual Cell with Artificial Intelligence: Priorities and Opportunities
Sep 18, 2024

The cell is arguably the smallest unit of life and is central to understanding biology. Accurate modeling of cells is important for this understanding as well as for determining the root causes of disease. Recent advances in artificial intelligence (AI), combined with the ability to generate large-scale experimental data, present novel opportunities to model cells. Here we propose a vision of AI-powered Virtual Cells, where robust representations of cells and cellular systems under different conditions are directly learned from growing biological data across measurements and scales. We discuss desired capabilities of AI Virtual Cells, including generating universal representations of biological entities across scales, and facilitating interpretable in silico experiments to predict and understand their behavior using Virtual Instruments. We further address the challenges, opportunities and requirements to realize this vision including data needs, evaluation strategies, and community standards and engagement to ensure biological accuracy and broad utility. We envision a future where AI Virtual Cells help identify new drug targets, predict cellular responses to perturbations, as well as scale hypothesis exploration. With open science collaborations across the biomedical ecosystem that includes academia, philanthropy, and the biopharma and AI industries, a comprehensive predictive understanding of cell mechanisms and interactions is within reach.