 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Domain Generalization in Contrastive Learning using Adaptive Temperature Control
Jan 12, 2026Self-supervised pre-training with contrastive learning is a powerful method for learning from sparsely labeled data. However, performance can drop considerably when there is a shift in the distribution of data from training to test time. We study this phenomenon in a setting in which the training data come from multiple domains, and the test data come from a domain not seen at training that is subject to significant covariate shift. We present a new method for contrastive learning that incorporates domain labels to increase the domain invariance of learned representations, leading to improved out-of-distribution generalization. Our method adjusts the temperature parameter in the InfoNCE loss -- which controls the relative weighting of negative pairs -- using the probability that a negative sample comes from the same domain as the anchor. This upweights pairs from more similar domains, encouraging the model to discriminate samples based on domain-invariant attributes. Through experiments on a variant of the MNIST dataset, we demonstrate that our method yields better out-of-distribution performance than domain generalization baselines. Furthermore, our method maintains strong in-distribution task performance, substantially outperforming baselines on this measure.
Classifying Phonotrauma Severity from Vocal Fold Images with Soft Ordinal Regression
Nov 12, 2025



Phonotrauma refers to vocal fold tissue damage resulting from exposure to forces during voicing. It occurs on a continuum from mild to severe, and treatment options can vary based on severity. Assessment of severity involves a clinician's expert judgment, which is costly and can vary widely in reliability. In this work, we present the first method for automatically classifying phonotrauma severity from vocal fold images. To account for the ordinal nature of the labels, we adopt a widely used ordinal regression framework. To account for label uncertainty, we propose a novel modification to ordinal regression loss functions that enables them to operate on soft labels reflecting annotator rating distributions. Our proposed soft ordinal regression method achieves predictive performance approaching that of clinical experts, while producing well-calibrated uncertainty estimates. By providing an automated tool for phonotrauma severity assessment, our work can enable large-scale studies of phonotrauma, ultimately leading to improved clinical understanding and patient care.
Walk the Talk? Measuring the Faithfulness of Large Language Model Explanations
Apr 19, 2025Large language models (LLMs) are capable of generating plausible explanations of how they arrived at an answer to a question. However, these explanations can misrepresent the model's "reasoning" process, i.e., they can be unfaithful. This, in turn, can lead to over-trust and misuse. We introduce a new approach for measuring the faithfulness of LLM explanations. First, we provide a rigorous definition of faithfulness. Since LLM explanations mimic human explanations, they often reference high-level concepts in the input question that purportedly influenced the model. We define faithfulness in terms of the difference between the set of concepts that LLM explanations imply are influential and the set that truly are. Second, we present a novel method for estimating faithfulness that is based on: (1) using an auxiliary LLM to modify the values of concepts within model inputs to create realistic counterfactuals, and (2) using a Bayesian hierarchical model to quantify the causal effects of concepts at both the example- and dataset-level. Our experiments show that our method can be used to quantify and discover interpretable patterns of unfaithfulness. On a social bias task, we uncover cases where LLM explanations hide the influence of social bias. On a medical question answering task, we uncover cases where LLM explanations provide misleading claims about which pieces of evidence influenced the model's decisions.
MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering
Jun 03, 2024

Large language models (LLM) have achieved impressive performance on medical question-answering benchmarks. However, high benchmark accuracy does not imply that the performance generalizes to real-world clinical settings. Medical question-answering benchmarks rely on assumptions consistent with quantifying LLM performance but that may not hold in the open world of the clinic. Yet LLMs learn broad knowledge that can help the LLM generalize to practical conditions regardless of unrealistic assumptions in celebrated benchmarks. We seek to quantify how well LLM medical question-answering benchmark performance generalizes when benchmark assumptions are violated. Specifically, we present an adversarial method that we call MedFuzz (for medical fuzzing). MedFuzz attempts to modify benchmark questions in ways aimed at confounding the LLM. We demonstrate the approach by targeting strong assumptions about patient characteristics presented in the MedQA benchmark. Successful "attacks" modify a benchmark item in ways that would be unlikely to fool a medical expert but nonetheless "trick" the LLM into changing from a correct to an incorrect answer. Further, we present a permutation test technique that can ensure a successful attack is statistically significant. We show how to use performance on a "MedFuzzed" benchmark, as well as individual successful attacks. The methods show promise at providing insights into the ability of an LLM to operate robustly in more realistic settings.
Quantifying the Effects of COVID-19 on Mental Health Support Forums
Sep 08, 2020
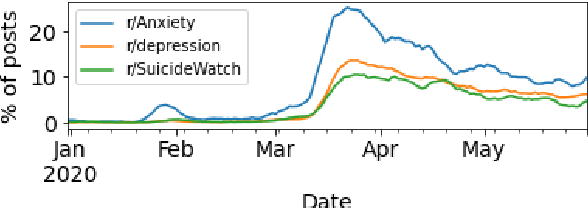


The COVID-19 pandemic, like many of the disease outbreaks that have preceded it, is likely to have a profound effect on mental health. Understanding its impact can inform strategies for mitigating negative consequences. In this work, we seek to better understand the effects of COVID-19 on mental health by examining discussions within mental health support communities on Reddit. First, we quantify the rate at which COVID-19 is discussed in each community, or subreddit, in order to understand levels of preoccupation with the pandemic. Next, we examine the volume of activity in order to determine whether the quantity of people seeking online mental health support has risen. Finally, we analyze how COVID-19 has influenced language use and topics of discussion within each subreddit.
When to Intervene: Detecting Abnormal Mood using Everyday Smartphone Conversations
Oct 03, 2019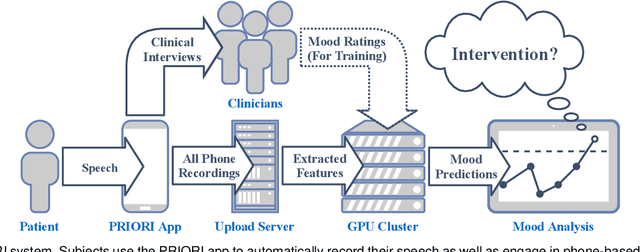
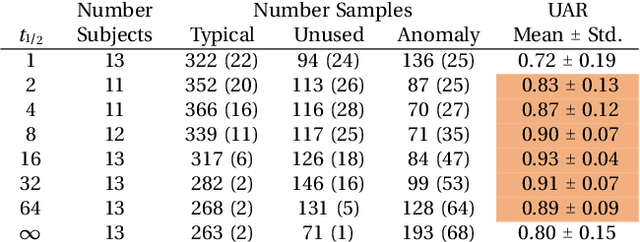
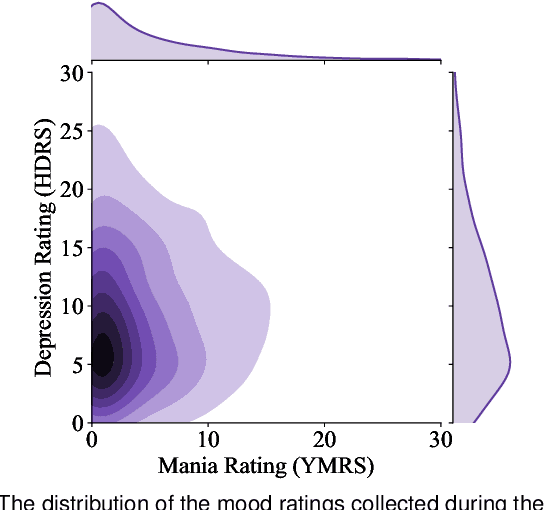

Bipolar disorder (BPD) is a chronic mental illness characterized by extreme mood and energy changes from mania to depression. These changes drive behaviors that often lead to devastating personal or social consequences. BPD is managed clinically with regular interactions with care providers, who assess mood, energy levels, and the form and content of speech. Recent work has proposed smartphones for monitoring mood using speech. However, these works do not predict when to intervene. Predicting when to intervene is challenging because there is not a single measure that is relevant for every person: different individuals may have different levels of symptom severity considered typical. Additionally, this typical mood, or baseline, may change over time, making a single symptom threshold insufficient. This work presents an innovative approach that expands clinical mood monitoring to predict when interventions are necessary using an anomaly detection framework, which we call Temporal Normalization. We first validate the model using a dataset annotated for clinical interventions and then incorporate this method in a deep learning framework to predict mood anomalies from natural, unstructured, telephone speech data. The combination of these approaches provides a framework to enable real-world speech-focused mood monitoring.