 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak susceptibility prediction and mitigation via the behavioral geometry of models
May 26, 2026Evaluating and mitigating a generative system's susceptibility to jailbreak attacks is critical to its safe deployment. Given the number of deployable systems, full per-configuration evaluation and optimization is impractical. In this paper, we formalize the behavioral geometry of a population of models that, by leveraging previously evaluated and defended models, supports both efficient susceptibility prediction and effective defense transfer across a population. We apply the framework to 79 models spanning 24 providers and to 100 system configurations of a single base model. Simple methods that use the behavioral geometry reach an AUPRC of $0.94$ for susceptibility detection with $\approx98\%$ fewer probes relative to a full evaluation. Using the behavioral geometry to select which model to transfer an optimized defense from outperforms same-provider assignment ($+2\%$, $p = 0.03$) at no additional probe cost, with a set of three models sufficient to cover the population. Results are robust to hyperparameter selection and judge.
When prompt perturbations break your A/B test: A valid statistical test for generative surveying
May 26, 2026Generative surveying -- where collections of LLM-based personas provide feedback on messages -- has emerged as a cheap and scalable alternative to traditional market research. However, LLMs are sensitive to small variations in prompt design and conclusions drawn from generative surveys may depend on arbitrary phrasing choices. Controlling for this sensitivity requires including semantically equivalent perturbations in the analysis. In this paper, we show that standard hypothesis tests, including the sign test and Wilcoxon signed-rank test, are invalid under a statistical model for generative surveying that includes realistic perturbation structure. We propose a permutation test that is valid under this model and formally characterize the conditions under which standard tests fail. Applying our framework to a simple generative surveying problem, we estimate relevant parameters, characterize the power of the permutation test under realistic conditions, and provide practical guidance on budget allocation across personas, perturbations, and replicates. Finally, we show that both the magnitude and direction of the estimated effect are sensitive to the choice of model, even within the same model family.
Investigating social alignment via mirroring in a system of interacting language models
Dec 07, 2024Alignment is a social phenomenon wherein individuals share a common goal or perspective. Mirroring, or mimicking the behaviors and opinions of another individual, is one mechanism by which individuals can become aligned. Large scale investigations of the effect of mirroring on alignment have been limited due to the scalability of traditional experimental designs in sociology. In this paper, we introduce a simple computational framework that enables studying the effect of mirroring behavior on alignment in multi-agent systems. We simulate systems of interacting large language models in this framework and characterize overall system behavior and alignment with quantitative measures of agent dynamics. We find that system behavior is strongly influenced by the range of communication of each agent and that these effects are exacerbated by increased rates of mirroring. We discuss the observed simulated system behavior in the context of known human social dynamics.
Embedding-based statistical inference on generative models
Oct 01, 2024



The recent cohort of publicly available generative models can produce human expert level content across a variety of topics and domains. Given a model in this cohort as a base model, methods such as parameter efficient fine-tuning, in-context learning, and constrained decoding have further increased generative capabilities and improved both computational and data efficiency. Entire collections of derivative models have emerged as a byproduct of these methods and each of these models has a set of associated covariates such as a score on a benchmark, an indicator for if the model has (or had) access to sensitive information, etc. that may or may not be available to the user. For some model-level covariates, it is possible to use "similar" models to predict an unknown covariate. In this paper we extend recent results related to embedding-based representations of generative models -- the data kernel perspective space -- to classical statistical inference settings. We demonstrate that using the perspective space as the basis of a notion of "similar" is effective for multiple model-level inference tasks.
Tracking the perspectives of interacting language models
Jun 17, 2024Large language models (LLMs) are capable of producing high quality information at unprecedented rates. As these models continue to entrench themselves in society, the content they produce will become increasingly pervasive in databases that are, in turn, incorporated into the pre-training data, fine-tuning data, retrieval data, etc. of other language models. In this paper we formalize the idea of a communication network of LLMs and introduce a method for representing the perspective of individual models within a collection of LLMs. Given these tools we systematically study information diffusion in the communication network of LLMs in various simulated settings.
MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering
Jun 03, 2024

Large language models (LLM) have achieved impressive performance on medical question-answering benchmarks. However, high benchmark accuracy does not imply that the performance generalizes to real-world clinical settings. Medical question-answering benchmarks rely on assumptions consistent with quantifying LLM performance but that may not hold in the open world of the clinic. Yet LLMs learn broad knowledge that can help the LLM generalize to practical conditions regardless of unrealistic assumptions in celebrated benchmarks. We seek to quantify how well LLM medical question-answering benchmark performance generalizes when benchmark assumptions are violated. Specifically, we present an adversarial method that we call MedFuzz (for medical fuzzing). MedFuzz attempts to modify benchmark questions in ways aimed at confounding the LLM. We demonstrate the approach by targeting strong assumptions about patient characteristics presented in the MedQA benchmark. Successful "attacks" modify a benchmark item in ways that would be unlikely to fool a medical expert but nonetheless "trick" the LLM into changing from a correct to an incorrect answer. Further, we present a permutation test technique that can ensure a successful attack is statistically significant. We show how to use performance on a "MedFuzzed" benchmark, as well as individual successful attacks. The methods show promise at providing insights into the ability of an LLM to operate robustly in more realistic settings.
A Statistical Turing Test for Generative Models
Sep 16, 2023

The emergence of human-like abilities of AI systems for content generation in domains such as text, audio, and vision has prompted the development of classifiers to determine whether content originated from a human or a machine. Implicit in these efforts is an assumption that the generation properties of a human are different from that of the machine. In this work, we provide a framework in the language of statistical pattern recognition that quantifies the difference between the distributions of human and machine-generated content conditioned on an evaluation context. We describe current methods in the context of the framework and demonstrate how to use the framework to evaluate the progression of generative models towards human-like capabilities, among many axes of analysis.
Vertex Classification on Weighted Networks
Jun 07, 2019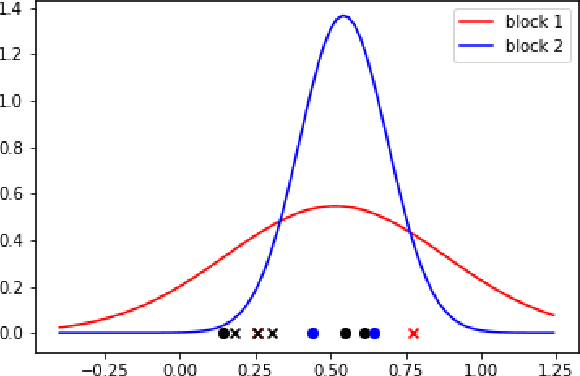

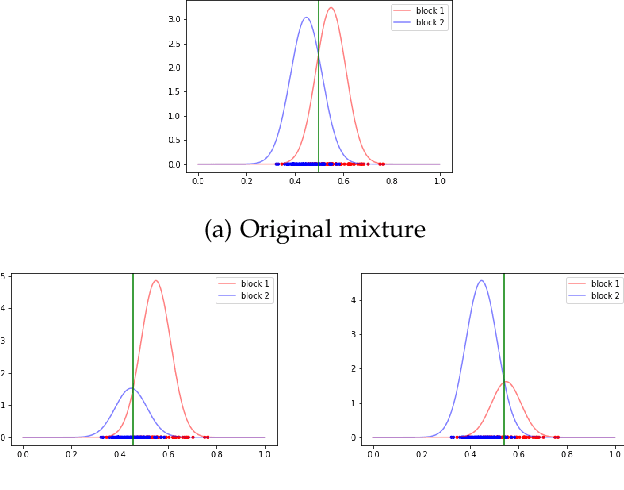
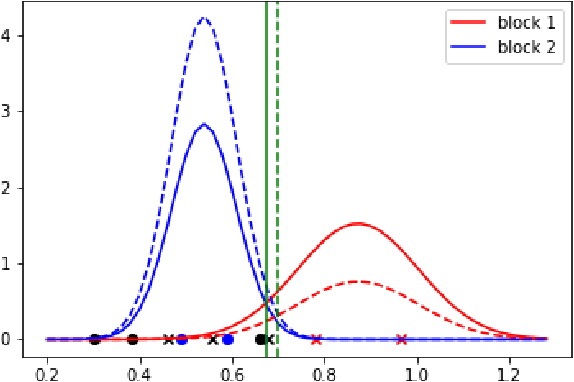
This paper proposes a discrimination technique for vertices in a weighted network. We assume that the edge weights and adjacencies in the network are conditionally independent and that both sources of information encode class membership information. In particular, we introduce a edge weight distribution matrix to the standard K-Block Stochastic Block Model to model weighted networks. This allows us to develop simple yet powerful extensions of classification techniques using the spectral embedding of the unweighted adjacency matrix. We consider two assumptions on the edge weight distributions and propose classification procedures in both settings. We show the effectiveness of the proposed classifiers by comparing them to quadratic discriminant analysis following the spectral embedding of a transformed weighted network. Moreover, we discuss and show how the methods perform when the edge weights do not encode class membership information.