 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling medical imaging report generation with multimodal reinforcement learning
Jan 23, 2026Frontier models have demonstrated remarkable capabilities in understanding and reasoning with natural-language text, but they still exhibit major competency gaps in multimodal understanding and reasoning especially in high-value verticals such as biomedicine. Medical imaging report generation is a prominent example. Supervised fine-tuning can substantially improve performance, but they are prone to overfitting to superficial boilerplate patterns. In this paper, we introduce Universal Report Generation (UniRG) as a general framework for medical imaging report generation. By leveraging reinforcement learning as a unifying mechanism to directly optimize for evaluation metrics designed for end applications, UniRG can significantly improve upon supervised fine-tuning and attain durable generalization across diverse institutions and clinical practices. We trained UniRG-CXR on publicly available chest X-ray (CXR) data and conducted a thorough evaluation in CXR report generation with rigorous evaluation scenarios. On the authoritative ReXrank benchmark, UniRG-CXR sets new overall SOTA, outperforming prior state of the art by a wide margin.
Machine learning nonequilibrium phase transitions in charge-density wave insulators
Jan 12, 2026Nonequilibrium electronic forces play a central role in voltage-driven phase transitions but are notoriously expensive to evaluate in dynamical simulations. Here we develop a machine learning framework for adiabatic lattice dynamics coupled to nonequilibrium electrons, and demonstrate it for a gating induced insulator to metal transition out of a charge density wave state in the Holstein model. Although exact electronic forces can be obtained from nonequilibrium Green's function (NEGF) calculations, their high computational cost renders long time dynamical simulations prohibitively expensive. By exploiting the locality of the electronic response, we train a neural network to directly predict instantaneous local electronic forces from the lattice configuration, thereby bypassing repeated NEGF calculations during time evolution. When combined with Brownian dynamics, the resulting machine learning force field quantitatively reproduces domain wall motion and nonequilibrium phase transition dynamics obtained from full NEGF simulations, while achieving orders of magnitude gains in computational efficiency. Our results establish direct force learning as an efficient and accurate approach for simulating nonequilibrium lattice dynamics in driven quantum materials.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Jan 05, 2026The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a large language model (LLM)-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-Language Model (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
CSCBench: A PVC Diagnostic Benchmark for Commodity Supply Chain Reasoning
Jan 05, 2026Large Language Models (LLMs) have achieved remarkable success in general benchmarks, yet their competence in commodity supply chains (CSCs) -- a domain governed by institutional rule systems and feasibility constraints -- remains under-explored. CSC decisions are shaped jointly by process stages (e.g., planning, procurement, delivery), variety-specific rules (e.g., contract specifications and delivery grades), and reasoning depth (from retrieval to multi-step analysis and decision selection). We introduce CSCBench, a 2.3K+ single-choice benchmark for CSC reasoning, instantiated through our PVC 3D Evaluation Framework (Process, Variety, and Cognition). The Process axis aligns tasks with SCOR+Enable; the Variety axis operationalizes commodity-specific rule systems under coupled material-information-financial constraints, grounded in authoritative exchange guidebooks/rulebooks and industry reports; and the Cognition axis follows Bloom's revised taxonomy. Evaluating representative LLMs under a direct prompting setting, we observe strong performance on the Process and Cognition axes but substantial degradation on the Variety axis, especially on Freight Agreements. CSCBench provides a diagnostic yardstick for measuring and improving LLM capabilities in this high-stakes domain.
Renormalization Group Guided Tensor Network Structure Search
Dec 31, 2025Tensor network structure search (TN-SS) aims to automatically discover optimal network topologies and rank configurations for efficient tensor decomposition in high-dimensional data representation. Despite recent advances, existing TN-SS methods face significant limitations in computational tractability, structure adaptivity, and optimization robustness across diverse tensor characteristics. They struggle with three key challenges: single-scale optimization missing multi-scale structures, discrete search spaces hindering smooth structure evolution, and separated structure-parameter optimization causing computational inefficiency. We propose RGTN (Renormalization Group guided Tensor Network search), a physics-inspired framework transforming TN-SS via multi-scale renormalization group flows. Unlike fixed-scale discrete search methods, RGTN uses dynamic scale-transformation for continuous structure evolution across resolutions. Its core innovation includes learnable edge gates for optimization-stage topology modification and intelligent proposals based on physical quantities like node tension measuring local stress and edge information flow quantifying connectivity importance. Starting from low-complexity coarse scales and refining to finer ones, RGTN finds compact structures while escaping local minima via scale-induced perturbations. Extensive experiments on light field data, high-order synthetic tensors, and video completion tasks show RGTN achieves state-of-the-art compression ratios and runs 4-600$\times$ faster than existing methods, validating the effectiveness of our physics-inspired approach.
BoRe-Depth: Self-supervised Monocular Depth Estimation with Boundary Refinement for Embedded Systems
Nov 06, 2025



Depth estimation is one of the key technologies for realizing 3D perception in unmanned systems. Monocular depth estimation has been widely researched because of its low-cost advantage, but the existing methods face the challenges of poor depth estimation performance and blurred object boundaries on embedded systems. In this paper, we propose a novel monocular depth estimation model, BoRe-Depth, which contains only 8.7M parameters. It can accurately estimate depth maps on embedded systems and significantly improves boundary quality. Firstly, we design an Enhanced Feature Adaptive Fusion Module (EFAF) which adaptively fuses depth features to enhance boundary detail representation. Secondly, we integrate semantic knowledge into the encoder to improve the object recognition and boundary perception capabilities. Finally, BoRe-Depth is deployed on NVIDIA Jetson Orin, and runs efficiently at 50.7 FPS. We demonstrate that the proposed model significantly outperforms previous lightweight models on multiple challenging datasets, and we provide detailed ablation studies for the proposed methods. The code is available at https://github.com/liangxiansheng093/BoRe-Depth.
RECALL: REpresentation-aligned Catastrophic-forgetting ALLeviation via Hierarchical Model Merging
Oct 23, 2025We unveil that internal representations in large language models (LLMs) serve as reliable proxies of learned knowledge, and propose RECALL, a novel representation-aware model merging framework for continual learning without access to historical data. RECALL computes inter-model similarity from layer-wise hidden representations over clustered typical samples, and performs adaptive, hierarchical parameter fusion to align knowledge across models. This design enables the preservation of domain-general features in shallow layers while allowing task-specific adaptation in deeper layers. Unlike prior methods that require task labels or incur performance trade-offs, RECALL achieves seamless multi-domain integration and strong resistance to catastrophic forgetting. Extensive experiments across five NLP tasks and multiple continual learning scenarios show that RECALL outperforms baselines in both knowledge retention and generalization, providing a scalable and data-free solution for evolving LLMs.
ArenaBencher: Automatic Benchmark Evolution via Multi-Model Competitive Evaluation
Oct 09, 2025
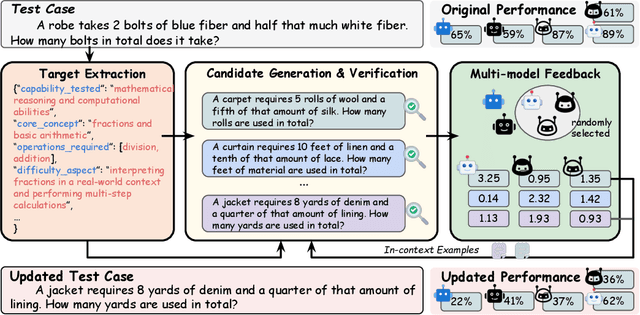
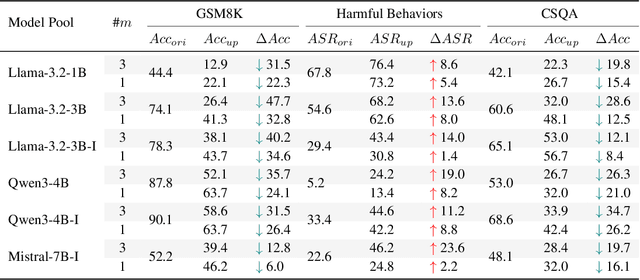
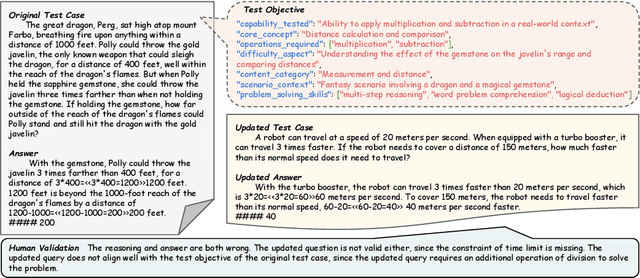
Benchmarks are central to measuring the capabilities of large language models and guiding model development, yet widespread data leakage from pretraining corpora undermines their validity. Models can match memorized content rather than demonstrate true generalization, which inflates scores, distorts cross-model comparisons, and misrepresents progress. We introduce ArenaBencher, a model-agnostic framework for automatic benchmark evolution that updates test cases while preserving comparability. Given an existing benchmark and a diverse pool of models to be evaluated, ArenaBencher infers the core ability of each test case, generates candidate question-answer pairs that preserve the original objective, verifies correctness and intent with an LLM as a judge, and aggregates feedback from multiple models to select candidates that expose shared weaknesses. The process runs iteratively with in-context demonstrations that steer generation toward more challenging and diagnostic cases. We apply ArenaBencher to math problem solving, commonsense reasoning, and safety domains and show that it produces verified, diverse, and fair updates that uncover new failure modes, increase difficulty while preserving test objective alignment, and improve model separability. The framework provides a scalable path to continuously evolve benchmarks in step with the rapid progress of foundation models.
CodeRAG: Finding Relevant and Necessary Knowledge for Retrieval-Augmented Repository-Level Code Completion
Sep 19, 2025Repository-level code completion automatically predicts the unfinished code based on the broader information from the repository. Recent strides in Code Large Language Models (code LLMs) have spurred the development of repository-level code completion methods, yielding promising results. Nevertheless, they suffer from issues such as inappropriate query construction, single-path code retrieval, and misalignment between code retriever and code LLM. To address these problems, we introduce CodeRAG, a framework tailored to identify relevant and necessary knowledge for retrieval-augmented repository-level code completion. Its core components include log probability guided query construction, multi-path code retrieval, and preference-aligned BestFit reranking. Extensive experiments on benchmarks ReccEval and CCEval demonstrate that CodeRAG significantly and consistently outperforms state-of-the-art methods. The implementation of CodeRAG is available at https://github.com/KDEGroup/CodeRAG.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.