 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving $\varepsilon^{-2}$ Dependence for Average-Reward Q-Learning with a New Contraction Principle
Jan 29, 2026We present the convergence rates of synchronous and asynchronous Q-learning for average-reward Markov decision processes, where the absence of contraction poses a fundamental challenge. Existing non-asymptotic results overcome this challenge by either imposing strong assumptions to enforce seminorm contraction or relying on discounted or episodic Markov decision processes as successive approximations, which either require unknown parameters or result in suboptimal sample complexity. In this work, under a reachability assumption, we establish optimal $\widetilde{O}(\varepsilon^{-2})$ sample complexity guarantees (up to logarithmic factors) for a simple variant of synchronous and asynchronous Q-learning that samples from the lazified dynamics, where the system remains in the current state with some fixed probability. At the core of our analysis is the construction of an instance-dependent seminorm and showing that, after a lazy transformation of the Markov decision process, the Bellman operator becomes one-step contractive under this seminorm.
Non-Asymptotic Guarantees for Average-Reward Q-Learning with Adaptive Stepsizes
Apr 25, 2025
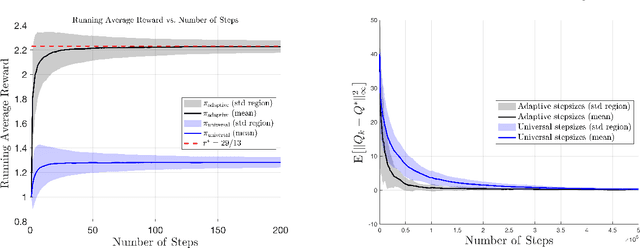
This work presents the first finite-time analysis for the last-iterate convergence of average-reward Q-learning with an asynchronous implementation. A key feature of the algorithm we study is the use of adaptive stepsizes, which serve as local clocks for each state-action pair. We show that the iterates generated by this Q-learning algorithm converge at a rate of $O(1/k)$ (in the mean-square sense) to the optimal relative Q-function in the span seminorm. Moreover, by adding a centering step to the algorithm, we further establish pointwise mean-square convergence to a centered optimal relative Q-function, also at a rate of $O(1/k)$. To prove these results, we show that adaptive stepsizes are necessary, as without them, the algorithm fails to converge to the correct target. In addition, adaptive stepsizes can be interpreted as a form of implicit importance sampling that counteracts the effects of asynchronous updates. Technically, the use of adaptive stepsizes makes each Q-learning update depend on the entire sample history, introducing strong correlations and making the algorithm a non-Markovian stochastic approximation (SA) scheme. Our approach to overcoming this challenge involves (1) a time-inhomogeneous Markovian reformulation of non-Markovian SA, and (2) a combination of almost-sure time-varying bounds, conditioning arguments, and Markov chain concentration inequalities to break the strong correlations between the adaptive stepsizes and the iterates. The tools developed in this work are likely to be broadly applicable to the analysis of general SA algorithms with adaptive stepsizes.
A Non-Asymptotic Theory of Seminorm Lyapunov Stability: From Deterministic to Stochastic Iterative Algorithms
Feb 20, 2025We study the problem of solving fixed-point equations for seminorm-contractive operators and establish foundational results on the non-asymptotic behavior of iterative algorithms in both deterministic and stochastic settings. Specifically, in the deterministic setting, we prove a fixed-point theorem for seminorm-contractive operators, showing that iterates converge geometrically to the kernel of the seminorm. In the stochastic setting, we analyze the corresponding stochastic approximation (SA) algorithm under seminorm-contractive operators and Markovian noise, providing a finite-sample analysis for various stepsize choices. A benchmark for equation solving is linear systems of equations, where the convergence behavior of fixed-point iteration is closely tied to the stability of linear dynamical systems. In this special case, our results provide a complete characterization of system stability with respect to a seminorm, linking it to the solution of a Lyapunov equation in terms of positive semi-definite matrices. In the stochastic setting, we establish a finite-sample analysis for linear Markovian SA without requiring the Hurwitzness assumption. Our theoretical results offer a unified framework for deriving finite-sample bounds for various reinforcement learning algorithms in the average reward setting, including TD($\lambda$) for policy evaluation (which is a special case of solving a Poisson equation) and Q-learning for control.
Last-Iterate Convergence of Payoff-Based Independent Learning in Zero-Sum Stochastic Games
Sep 02, 2024In this paper, we consider two-player zero-sum matrix and stochastic games and develop learning dynamics that are payoff-based, convergent, rational, and symmetric between the two players. Specifically, the learning dynamics for matrix games are based on the smoothed best-response dynamics, while the learning dynamics for stochastic games build upon those for matrix games, with additional incorporation of the minimax value iteration. To our knowledge, our theoretical results present the first finite-sample analysis of such learning dynamics with last-iterate guarantees. In the matrix game setting, the results imply a sample complexity of $O(\epsilon^{-1})$ to find the Nash distribution and a sample complexity of $O(\epsilon^{-8})$ to find a Nash equilibrium. In the stochastic game setting, the results also imply a sample complexity of $O(\epsilon^{-8})$ to find a Nash equilibrium. To establish these results, the main challenge is to handle stochastic approximation algorithms with multiple sets of coupled and stochastic iterates that evolve on (possibly) different time scales. To overcome this challenge, we developed a coupled Lyapunov-based approach, which may be of independent interest to the broader community studying the convergence behavior of stochastic approximation algorithms.
Approximate Global Convergence of Independent Learning in Multi-Agent Systems
May 30, 2024Independent learning (IL), despite being a popular approach in practice to achieve scalability in large-scale multi-agent systems, usually lacks global convergence guarantees. In this paper, we study two representative algorithms, independent $Q$-learning and independent natural actor-critic, within value-based and policy-based frameworks, and provide the first finite-sample analysis for approximate global convergence. The results imply a sample complexity of $\tilde{\mathcal{O}}(\epsilon^{-2})$ up to an error term that captures the dependence among agents and characterizes the fundamental limit of IL in achieving global convergence. To establish the result, we develop a novel approach for analyzing IL by constructing a separable Markov decision process (MDP) for convergence analysis and then bounding the gap due to model difference between the separable MDP and the original one. Moreover, we conduct numerical experiments using a synthetic MDP and an electric vehicle charging example to verify our theoretical findings and to demonstrate the practical applicability of IL.
Two-Timescale Q-Learning with Function Approximation in Zero-Sum Stochastic Games
Dec 08, 2023We consider two-player zero-sum stochastic games and propose a two-timescale $Q$-learning algorithm with function approximation that is payoff-based, convergent, rational, and symmetric between the two players. In two-timescale $Q$-learning, the fast-timescale iterates are updated in spirit to the stochastic gradient descent and the slow-timescale iterates (which we use to compute the policies) are updated by taking a convex combination between its previous iterate and the latest fast-timescale iterate. Introducing the slow timescale as well as its update equation marks as our main algorithmic novelty. In the special case of linear function approximation, we establish, to the best of our knowledge, the first last-iterate finite-sample bound for payoff-based independent learning dynamics of these types. The result implies a polynomial sample complexity to find a Nash equilibrium in such stochastic games. To establish the results, we model our proposed algorithm as a two-timescale stochastic approximation and derive the finite-sample bound through a Lyapunov-based approach. The key novelty lies in constructing a valid Lyapunov function to capture the evolution of the slow-timescale iterates. Specifically, through a change of variable, we show that the update equation of the slow-timescale iterates resembles the classical smoothed best-response dynamics, where the regularized Nash gap serves as a valid Lyapunov function. This insight enables us to construct a valid Lyapunov function via a generalized variant of the Moreau envelope of the regularized Nash gap. The construction of our Lyapunov function might be of broad independent interest in studying the behavior of stochastic approximation algorithms.
Concentration of Contractive Stochastic Approximation: Additive and Multiplicative Noise
Mar 28, 2023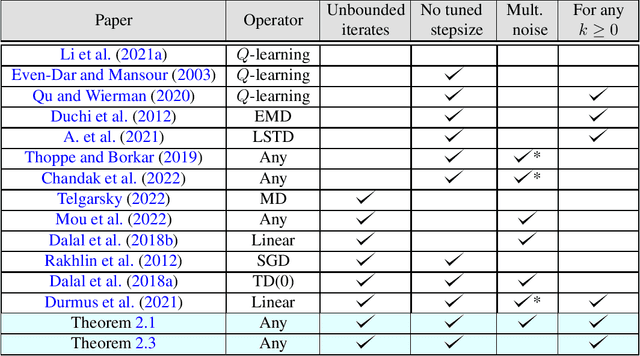
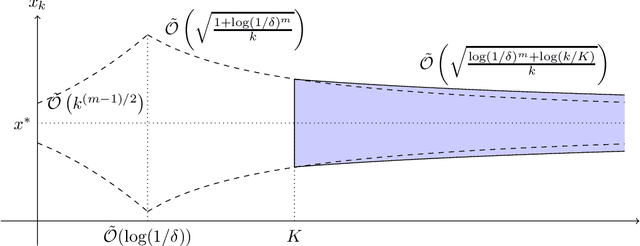
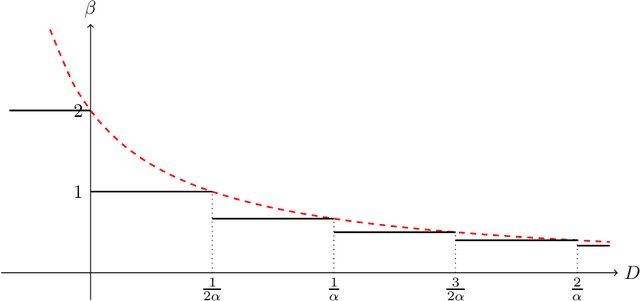
In this work, we study the concentration behavior of a stochastic approximation (SA) algorithm under a contractive operator with respect to an arbitrary norm. We consider two settings where the iterates are potentially unbounded: (1) bounded multiplicative noise, and (2) additive sub-Gaussian noise. We obtain maximal concentration inequalities on the convergence errors, and show that these errors have sub-Gaussian tails in the additive noise setting, and super-polynomial tails (faster than polynomial decay) in the multiplicative noise setting. In addition, we provide an impossibility result showing that it is in general not possible to achieve sub-exponential tails for SA with multiplicative noise. To establish these results, we develop a novel bootstrapping argument that involves bounding the moment generating function of the generalized Moreau envelope of the error and the construction of an exponential supermartingale to enable using Ville's maximal inequality. To demonstrate the applicability of our theoretical results, we use them to provide maximal concentration bounds for a large class of reinforcement learning algorithms, including but not limited to on-policy TD-learning with linear function approximation, off-policy TD-learning with generalized importance sampling factors, and $Q$-learning. To the best of our knowledge, super-polynomial concentration bounds for off-policy TD-learning have not been established in the literature due to the challenge of handling the combination of unbounded iterates and multiplicative noise.
Convergence Rates for Localized Actor-Critic in Networked Markov Potential Games
Mar 08, 2023

We introduce a class of networked Markov potential games where agents are associated with nodes in a network. Each agent has its own local potential function, and the reward of each agent depends only on the states and actions of agents within a $\kappa$-hop neighborhood. In this context, we propose a localized actor-critic algorithm. The algorithm is scalable since each agent uses only local information and does not need access to the global state. Further, the algorithm overcomes the curse of dimensionality through the use of function approximation. Our main results provide finite-sample guarantees up to a localization error and a function approximation error. Specifically, we achieve an $\tilde{\mathcal{O}}(\epsilon^{-4})$ sample complexity measured by the averaged Nash regret. This is the first finite-sample bound for multi-agent competitive games that does not depend on the number of agents.
A Finite-Sample Analysis of Payoff-Based Independent Learning in Zero-Sum Stochastic Games
Mar 03, 2023We study two-player zero-sum stochastic games, and propose a form of independent learning dynamics called Doubly Smoothed Best-Response dynamics, which integrates a discrete and doubly smoothed variant of the best-response dynamics into temporal-difference (TD)-learning and minimax value iteration. The resulting dynamics are payoff-based, convergent, rational, and symmetric among players. Our main results provide finite-sample guarantees. In particular, we prove the first-known $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity bound for payoff-based independent learning dynamics, up to a smoothing bias. In the special case where the stochastic game has only one state (i.e., matrix games), we provide a sharper $\tilde{\mathcal{O}}(1/\epsilon)$ sample complexity. Our analysis uses a novel coupled Lyapunov drift approach to capture the evolution of multiple sets of coupled and stochastic iterates, which might be of independent interest.
Global Convergence of Localized Policy Iteration in Networked Multi-Agent Reinforcement Learning
Nov 30, 2022We study a multi-agent reinforcement learning (MARL) problem where the agents interact over a given network. The goal of the agents is to cooperatively maximize the average of their entropy-regularized long-term rewards. To overcome the curse of dimensionality and to reduce communication, we propose a Localized Policy Iteration (LPI) algorithm that provably learns a near-globally-optimal policy using only local information. In particular, we show that, despite restricting each agent's attention to only its $\kappa$-hop neighborhood, the agents are able to learn a policy with an optimality gap that decays polynomially in $\kappa$. In addition, we show the finite-sample convergence of LPI to the global optimal policy, which explicitly captures the trade-off between optimality and computational complexity in choosing $\kappa$. Numerical simulations demonstrate the effectiveness of LPI.