 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow AI Aggregation Affects Knowledge
Apr 06, 2026Artificial intelligence (AI) changes social learning when aggregated outputs become training data for future predictions. To study this, we extend the DeGroot model by introducing an AI aggregator that trains on population beliefs and feeds synthesized signals back to agents. We define the learning gap as the deviation of long-run beliefs from the efficient benchmark, allowing us to capture how AI aggregation affects learning. Our main result identifies a threshold in the speed of updating: when the aggregator updates too quickly, there is no positive-measure set of training weights that robustly improves learning across a broad class of environments, whereas such weights exist when updating is sufficiently slow. We then compare global and local architectures. Local aggregators trained on proximate or topic-specific data robustly improve learning in all environments. Consequently, replacing specialized local aggregators with a single global aggregator worsens learning in at least one dimension of the state.
Online Learning and Equilibrium Computation with Ranking Feedback
Mar 19, 2026Online learning in arbitrary, and possibly adversarial, environments has been extensively studied in sequential decision-making, and it is closely connected to equilibrium computation in game theory. Most existing online learning algorithms rely on \emph{numeric} utility feedback from the environment, which may be unavailable in human-in-the-loop applications and/or may be restricted by privacy concerns. In this paper, we study an online learning model in which the learner only observes a \emph{ranking} over a set of proposed actions at each timestep. We consider two ranking mechanisms: rankings induced by the \emph{instantaneous} utility at the current timestep, and rankings induced by the \emph{time-average} utility up to the current timestep, under both \emph{full-information} and \emph{bandit} feedback settings. Using the standard external-regret metric, we show that sublinear regret is impossible with instantaneous-utility ranking feedback in general. Moreover, when the ranking model is relatively deterministic, \emph{i.e.}, under the Plackett-Luce model with a temperature that is sufficiently small, sublinear regret is also impossible with time-average utility ranking feedback. We then develop new algorithms that achieve sublinear regret under the additional assumption that the utility sequence has sublinear total variation. Notably, for full-information time-average utility ranking feedback, this additional assumption can be removed. As a consequence, when all players in a normal-form game follow our algorithms, repeated play yields an approximate coarse correlated equilibrium. We also demonstrate the effectiveness of our algorithms in an online large-language-model routing task.
Collaborative and Efficient Fine-tuning: Leveraging Task Similarity
Feb 06, 2026Adaptability has been regarded as a central feature in the foundation models, enabling them to effectively acclimate to unseen downstream tasks. Parameter-efficient fine-tuning methods such as celebrated LoRA facilitate efficient adaptation of large foundation models using labeled, high-quality and generally scarce task data. To mitigate data scarcity in fine-tuning of foundation models, we propose to leverage task similarity across multiple downstream users. Intuitively, users with similar tasks must be able to assist each other in boosting the effective fine-tuning data size. We propose Collaborative Low-Rank Adaptation, or CoLoRA, which exploits task similarity to collaboratively and efficiently fine-tune personalized foundation models. The main idea in CoLoRA is to train one shared adapter capturing underlying task similarities across all tasks, and personalized adapters tailored to user-specific tasks. We theoretically study CoLoRA on heterogeneous linear regression and provide provable guarantees for ground truth recovery. We also conduct several natural language experiments with varying task similarity, which further demonstrate that when trained together with similar tasks, individual performances are significantly boosted.
Post-Training LLMs as Better Decision-Making Agents: A Regret-Minimization Approach
Nov 06, 2025Large language models (LLMs) are increasingly deployed as "agents" for decision-making (DM) in interactive and dynamic environments. Yet, since they were not originally designed for DM, recent studies show that LLMs can struggle even in basic online DM problems, failing to achieve low regret or an effective exploration-exploitation tradeoff. To address this, we introduce Iterative Regret-Minimization Fine-Tuning (Iterative RMFT), a post-training procedure that repeatedly distills low-regret decision trajectories back into the base model. At each iteration, the model rolls out multiple decision trajectories, selects the k-lowest regret ones, and fine-tunes itself on them. Unlike prior methods that (a) distill action sequences from known DM algorithms or (b) rely on manually crafted chain-of-thought templates, our approach leverages the regret metric to elicit the model's own DM ability and reasoning rationales. This reliance on model-generated reasoning avoids rigid output engineering and provides more flexible, natural-language training signals. Empirical results show that Iterative RMFT improves LLMs' DM performance across diverse models - from Transformers with numerical input/output, to open-weight LLMs, and advanced closed-weight models like GPT-4o mini. Its flexibility in output and reasoning formats enables generalization across tasks with varying horizons, action spaces, reward processes, and natural-language contexts. Finally, we provide theoretical insight showing that a single-layer Transformer under this paradigm can act as a no-regret learner in a simplified setting. Overall, Iterative RMFT offers a principled and general post-training framework for enhancing LLMs' decision-making capabilities.
Population-Proportional Preference Learning from Human Feedback: An Axiomatic Approach
Jun 05, 2025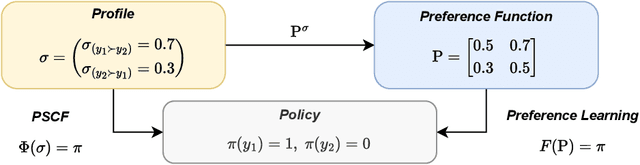

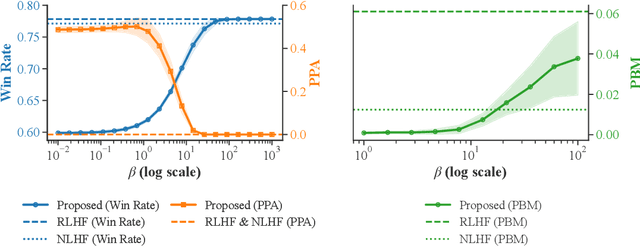
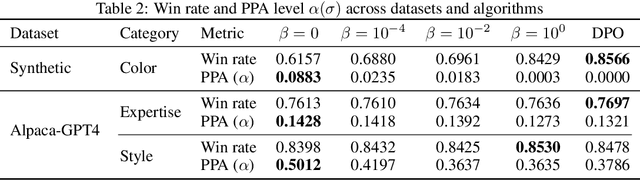
Conventional preference learning methods often prioritize opinions held more widely when aggregating preferences from multiple evaluators. This may result in policies that are biased in favor of some types of opinions or groups. The objective of this paper is to develop a novel preference learning framework capable of aligning aggregate opinions and policies proportionally with the true population distribution of evaluator preferences. Our approach infers the feasible set of evaluator population distributions directly from pairwise comparison data. Using these estimates, the algorithm constructs a policy that satisfies foundational axioms from social choice theory, namely monotonicity and Pareto efficiency, as well as our newly-introduced axioms of population-proportional representation and population-bounded robustness. We propose a soft-max relaxation method that smoothly trade-offs population-proportional representation with the selection of the Condorcet winner (which beats all other options in pairwise comparisons). Finally, we validate the effectiveness and scalability of our approach through experiments on both tabular recommendation tasks and large-scale language model alignment.
What Data Enables Optimal Decisions? An Exact Characterization for Linear Optimization
May 27, 2025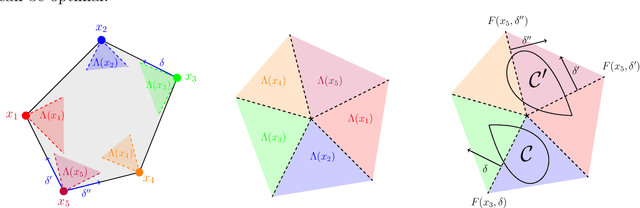
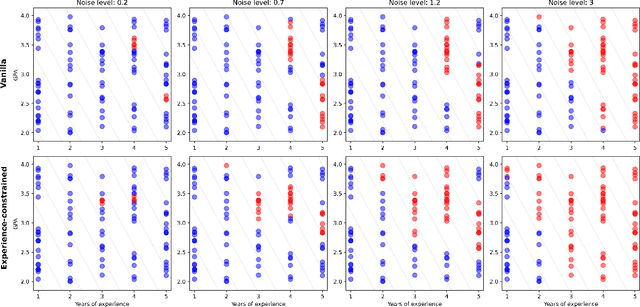
We study the fundamental question of how informative a dataset is for solving a given decision-making task. In our setting, the dataset provides partial information about unknown parameters that influence task outcomes. Focusing on linear programs, we characterize when a dataset is sufficient to recover an optimal decision, given an uncertainty set on the cost vector. Our main contribution is a sharp geometric characterization that identifies the directions of the cost vector that matter for optimality, relative to the task constraints and uncertainty set. We further develop a practical algorithm that, for a given task, constructs a minimal or least-costly sufficient dataset. Our results reveal that small, well-chosen datasets can often fully determine optimal decisions -- offering a principled foundation for task-aware data selection.
UFT: Unifying Supervised and Reinforcement Fine-Tuning
May 22, 2025



Post-training has demonstrated its importance in enhancing the reasoning capabilities of large language models (LLMs). The primary post-training methods can be categorized into supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT is efficient and well-suited for small language models, but it may lead to overfitting and limit the reasoning abilities of larger models. In contrast, RFT generally yields better generalization but depends heavily on the strength of the base model. To address the limitations of SFT and RFT, we propose Unified Fine-Tuning (UFT), a novel post-training paradigm that unifies SFT and RFT into a single, integrated process. UFT enables the model to effectively explore solutions while incorporating informative supervision signals, bridging the gap between memorizing and thinking underlying existing methods. Notably, UFT outperforms both SFT and RFT in general, regardless of model sizes. Furthermore, we theoretically prove that UFT breaks RFT's inherent exponential sample complexity bottleneck, showing for the first time that unified training can exponentially accelerate convergence on long-horizon reasoning tasks.
Differentially Private Equilibrium Finding in Polymatrix Games
Mar 12, 2025



We study equilibrium finding in polymatrix games under differential privacy constraints. To start, we show that high accuracy and asymptotically vanishing differential privacy budget (as the number of players goes to infinity) cannot be achieved simultaneously under either of the two settings: (i) We seek to establish equilibrium approximation guarantees in terms of Euclidean distance to the equilibrium set, and (ii) the adversary has access to all communication channels. Then, assuming the adversary has access to a constant number of communication channels, we develop a novel distributed algorithm that recovers strategies with simultaneously vanishing Nash gap (in expected utility, also referred to as exploitability and privacy budget as the number of players increases.
MAPoRL: Multi-Agent Post-Co-Training for Collaborative Large Language Models with Reinforcement Learning
Feb 25, 2025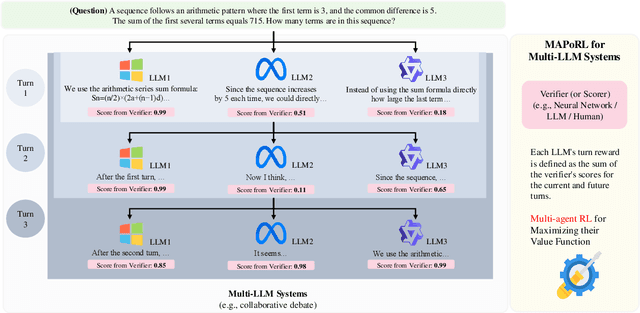
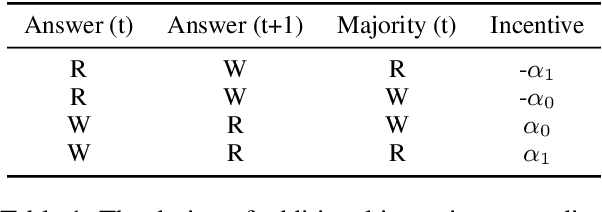
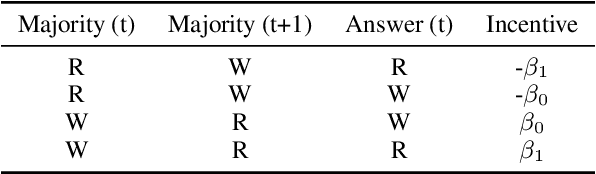
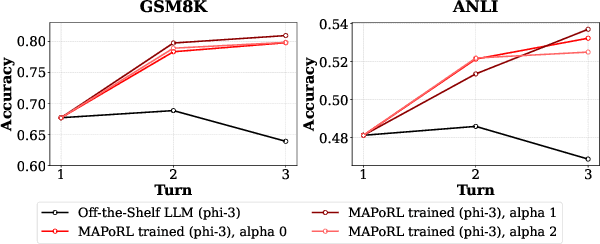
Leveraging multiple large language models (LLMs) to build collaborative multi-agentic workflows has demonstrated significant potential. However, most previous studies focus on prompting the out-of-the-box LLMs, relying on their innate capability for collaboration, which may not improve LLMs' performance as shown recently. In this paper, we introduce a new post-training paradigm MAPoRL (Multi-Agent Post-co-training for collaborative LLMs with Reinforcement Learning), to explicitly elicit the collaborative behaviors and further unleash the power of multi-agentic LLM frameworks. In MAPoRL, multiple LLMs first generate their own responses independently and engage in a multi-turn discussion to collaboratively improve the final answer. In the end, a MAPoRL verifier evaluates both the answer and the discussion, by assigning a score that verifies the correctness of the answer, while adding incentives to encourage corrective and persuasive discussions. The score serves as the co-training reward, and is then maximized through multi-agent RL. Unlike existing LLM post-training paradigms, MAPoRL advocates the co-training of multiple LLMs together using RL for better generalization. Accompanied by analytical insights, our experiments demonstrate that training individual LLMs alone is insufficient to induce effective collaboration. In contrast, multi-agent co-training can boost the collaboration performance across benchmarks, with generalization to unseen domains.
Last-Iterate Convergence of Payoff-Based Independent Learning in Zero-Sum Stochastic Games
Sep 02, 2024
In this paper, we consider two-player zero-sum matrix and stochastic games and develop learning dynamics that are payoff-based, convergent, rational, and symmetric between the two players. Specifically, the learning dynamics for matrix games are based on the smoothed best-response dynamics, while the learning dynamics for stochastic games build upon those for matrix games, with additional incorporation of the minimax value iteration. To our knowledge, our theoretical results present the first finite-sample analysis of such learning dynamics with last-iterate guarantees. In the matrix game setting, the results imply a sample complexity of $O(\epsilon^{-1})$ to find the Nash distribution and a sample complexity of $O(\epsilon^{-8})$ to find a Nash equilibrium. In the stochastic game setting, the results also imply a sample complexity of $O(\epsilon^{-8})$ to find a Nash equilibrium. To establish these results, the main challenge is to handle stochastic approximation algorithms with multiple sets of coupled and stochastic iterates that evolve on (possibly) different time scales. To overcome this challenge, we developed a coupled Lyapunov-based approach, which may be of independent interest to the broader community studying the convergence behavior of stochastic approximation algorithms.