 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning and Equilibrium Computation with Ranking Feedback
Mar 19, 2026Online learning in arbitrary, and possibly adversarial, environments has been extensively studied in sequential decision-making, and it is closely connected to equilibrium computation in game theory. Most existing online learning algorithms rely on \emph{numeric} utility feedback from the environment, which may be unavailable in human-in-the-loop applications and/or may be restricted by privacy concerns. In this paper, we study an online learning model in which the learner only observes a \emph{ranking} over a set of proposed actions at each timestep. We consider two ranking mechanisms: rankings induced by the \emph{instantaneous} utility at the current timestep, and rankings induced by the \emph{time-average} utility up to the current timestep, under both \emph{full-information} and \emph{bandit} feedback settings. Using the standard external-regret metric, we show that sublinear regret is impossible with instantaneous-utility ranking feedback in general. Moreover, when the ranking model is relatively deterministic, \emph{i.e.}, under the Plackett-Luce model with a temperature that is sufficiently small, sublinear regret is also impossible with time-average utility ranking feedback. We then develop new algorithms that achieve sublinear regret under the additional assumption that the utility sequence has sublinear total variation. Notably, for full-information time-average utility ranking feedback, this additional assumption can be removed. As a consequence, when all players in a normal-form game follow our algorithms, repeated play yields an approximate coarse correlated equilibrium. We also demonstrate the effectiveness of our algorithms in an online large-language-model routing task.
EST: Towards Efficient Scaling Laws in Click-Through Rate Prediction via Unified Modeling
Feb 11, 2026Efficiently scaling industrial Click-Through Rate (CTR) prediction has recently attracted significant research attention. Existing approaches typically employ early aggregation of user behaviors to maintain efficiency. However, such non-unified or partially unified modeling creates an information bottleneck by discarding fine-grained, token-level signals essential for unlocking scaling gains. In this work, we revisit the fundamental distinctions between CTR prediction and Large Language Models (LLMs), identifying two critical properties: the asymmetry in information density between behavioral and non-behavioral features, and the modality-specific priors of content-rich signals. Accordingly, we propose the Efficiently Scalable Transformer (EST), which achieves fully unified modeling by processing all raw inputs in a single sequence without lossy aggregation. EST integrates two modules: Lightweight Cross-Attention (LCA), which prunes redundant self-interactions to focus on high-impact cross-feature dependencies, and Content Sparse Attention (CSA), which utilizes content similarity to dynamically select high-signal behaviors. Extensive experiments show that EST exhibits a stable and efficient power-law scaling relationship, enabling predictable performance gains with model scale. Deployed on Taobao's display advertising platform, EST significantly outperforms production baselines, delivering a 3.27\% RPM (Revenue Per Mile) increase and a 1.22\% CTR lift, establishing a practical pathway for scalable industrial CTR prediction models.
On Temperature-Constrained Non-Deterministic Machine Translation: Potential and Evaluation
Jan 20, 2026In recent years, the non-deterministic properties of language models have garnered considerable attention and have shown a significant influence on real-world applications. However, such properties remain under-explored in machine translation (MT), a complex, non-deterministic NLP task. In this study, we systematically evaluate modern MT systems and identify temperature-constrained Non-Deterministic MT (ND-MT) as a distinct phenomenon. Additionally, we demonstrate that ND-MT exhibits significant potential in addressing the multi-modality issue that has long challenged MT research and provides higher-quality candidates than Deterministic MT (D-MT) under temperature constraints. However, ND-MT introduces new challenges in evaluating system performance. Specifically, the evaluation framework designed for D-MT fails to yield consistent evaluation results when applied to ND-MT. We further investigate this emerging challenge by evaluating five state-of-the-art ND-MT systems across three open datasets using both lexical-based and semantic-based metrics at varying sampling sizes. The results reveal a Buckets effect across these systems: the lowest-quality candidate generated by ND-MT consistently determines the overall system ranking across different sampling sizes for all reasonable metrics. Furthermore, we propose the ExpectoSample strategy to automatically assess the reliability of evaluation metrics for selecting robust ND-MT.
KLIPA: A Knowledge Graph and LLM-Driven QA Framework for IP Analysis
Sep 09, 2025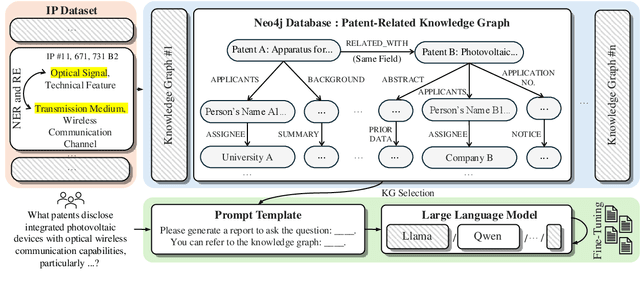
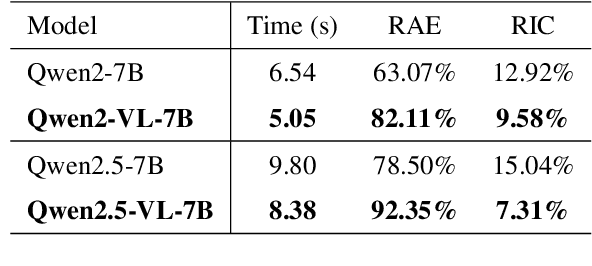
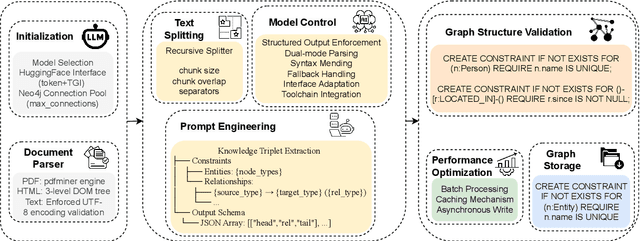
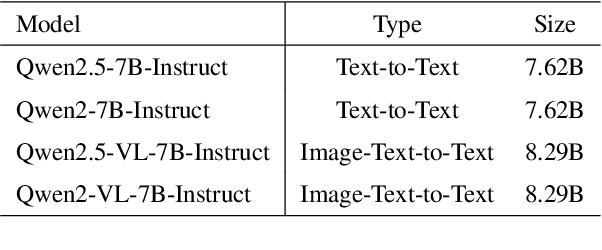
Effectively managing intellectual property is a significant challenge. Traditional methods for patent analysis depend on labor-intensive manual searches and rigid keyword matching. These approaches are often inefficient and struggle to reveal the complex relationships hidden within large patent datasets, hindering strategic decision-making. To overcome these limitations, we introduce KLIPA, a novel framework that leverages a knowledge graph and a large language model (LLM) to significantly advance patent analysis. Our approach integrates three key components: a structured knowledge graph to map explicit relationships between patents, a retrieval-augmented generation(RAG) system to uncover contextual connections, and an intelligent agent that dynamically determines the optimal strategy for resolving user queries. We validated KLIPA on a comprehensive, real-world patent database, where it demonstrated substantial improvements in knowledge extraction, discovery of novel connections, and overall operational efficiency. This combination of technologies enhances retrieval accuracy, reduces reliance on domain experts, and provides a scalable, automated solution for any organization managing intellectual property, including technology corporations and legal firms, allowing them to better navigate the complexities of strategic innovation and competitive intelligence.
PIVOTS: Aligning unseen Structures using Preoperative to Intraoperative Volume-To-Surface Registration for Liver Navigation
Jul 27, 2025
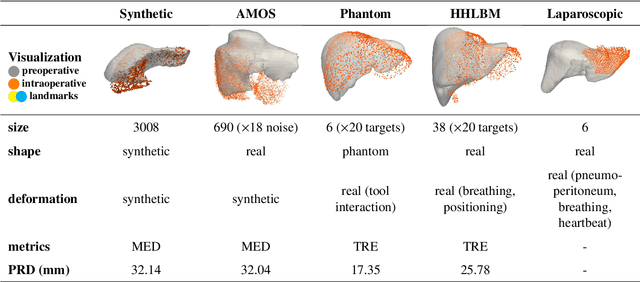


Non-rigid registration is essential for Augmented Reality guided laparoscopic liver surgery by fusing preoperative information, such as tumor location and vascular structures, into the limited intraoperative view, thereby enhancing surgical navigation. A prerequisite is the accurate prediction of intraoperative liver deformation which remains highly challenging due to factors such as large deformation caused by pneumoperitoneum, respiration and tool interaction as well as noisy intraoperative data, and limited field of view due to occlusion and constrained camera movement. To address these challenges, we introduce PIVOTS, a Preoperative to Intraoperative VOlume-To-Surface registration neural network that directly takes point clouds as input for deformation prediction. The geometric feature extraction encoder allows multi-resolution feature extraction, and the decoder, comprising novel deformation aware cross attention modules, enables pre- and intraoperative information interaction and accurate multi-level displacement prediction. We train the neural network on synthetic data simulated from a biomechanical simulation pipeline and validate its performance on both synthetic and real datasets. Results demonstrate superior registration performance of our method compared to baseline methods, exhibiting strong robustness against high amounts of noise, large deformation, and various levels of intraoperative visibility. We publish the training and test sets as evaluation benchmarks and call for a fair comparison of liver registration methods with volume-to-surface data. Code and datasets are available here https://github.com/pengliu-nct/PIVOTS.
UFT: Unifying Supervised and Reinforcement Fine-Tuning
May 22, 2025



Post-training has demonstrated its importance in enhancing the reasoning capabilities of large language models (LLMs). The primary post-training methods can be categorized into supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT is efficient and well-suited for small language models, but it may lead to overfitting and limit the reasoning abilities of larger models. In contrast, RFT generally yields better generalization but depends heavily on the strength of the base model. To address the limitations of SFT and RFT, we propose Unified Fine-Tuning (UFT), a novel post-training paradigm that unifies SFT and RFT into a single, integrated process. UFT enables the model to effectively explore solutions while incorporating informative supervision signals, bridging the gap between memorizing and thinking underlying existing methods. Notably, UFT outperforms both SFT and RFT in general, regardless of model sizes. Furthermore, we theoretically prove that UFT breaks RFT's inherent exponential sample complexity bottleneck, showing for the first time that unified training can exponentially accelerate convergence on long-horizon reasoning tasks.
Activation-Guided Consensus Merging for Large Language Models
May 20, 2025Recent research has increasingly focused on reconciling the reasoning capabilities of System 2 with the efficiency of System 1. While existing training-based and prompt-based approaches face significant challenges in terms of efficiency and stability, model merging emerges as a promising strategy to integrate the diverse capabilities of different Large Language Models (LLMs) into a unified model. However, conventional model merging methods often assume uniform importance across layers, overlooking the functional heterogeneity inherent in neural components. To address this limitation, we propose \textbf{A}ctivation-Guided \textbf{C}onsensus \textbf{M}erging (\textbf{ACM}), a plug-and-play merging framework that determines layer-specific merging coefficients based on mutual information between activations of pre-trained and fine-tuned models. ACM effectively preserves task-specific capabilities without requiring gradient computations or additional training. Extensive experiments on Long-to-Short (L2S) and general merging tasks demonstrate that ACM consistently outperforms all baseline methods. For instance, in the case of Qwen-7B models, TIES-Merging equipped with ACM achieves a \textbf{55.3\%} reduction in response length while simultaneously improving reasoning accuracy by \textbf{1.3} points. We submit the code with the paper for reproducibility, and it will be publicly available.
SAM2-ELNet: Label Enhancement and Automatic Annotation for Remote Sensing Segmentation
Mar 16, 2025Remote sensing image segmentation is crucial for environmental monitoring, disaster assessment, and resource management, directly affecting the accuracy and efficiency of surface information extraction. The performance of existing supervised models in remote sensing image segmentation tasks highly depends on the quality of label data. However, current label data mainly relies on manual annotation, which comes with high time costs and is subject to subjective interference, resulting in distortion of label boundaries and often a loss of detail. To solve the above problems, our work proposes an Edge-enhanced Labeling Network, called SAM2-ELNet, which incorporates a labeling module and an edge attention mechanism. This model effectively addresses issues such as label detail loss, fragmentation, and inaccurate boundaries. Due to the scarcity of manually annotated remote sensing data, the feature extraction capabilities of traditional neural networks are limited. Our method uses the Hiera backbone of the pre-trained self-supervised large model segment anything model 2 (SAM2) as the encoder, achieves high-quality and efficient feature extraction even with small samples by fine-tuning on downstream tasks. This study compared the training effects of original and enhanced labels on the manually annotated Deep-SAR Oil Spill (SOS) dataset. Results showed that the model trained with enhanced labels performed better and had a lower final loss, indicating closer alignment with the real data distribution. Our work also explores the potential of extending the model into an efficient automatic annotation framework through generalization experiments, facilitating large-scale remote sensing image interpretation and intelligent recognition.
Differentially Private Equilibrium Finding in Polymatrix Games
Mar 12, 2025



We study equilibrium finding in polymatrix games under differential privacy constraints. To start, we show that high accuracy and asymptotically vanishing differential privacy budget (as the number of players goes to infinity) cannot be achieved simultaneously under either of the two settings: (i) We seek to establish equilibrium approximation guarantees in terms of Euclidean distance to the equilibrium set, and (ii) the adversary has access to all communication channels. Then, assuming the adversary has access to a constant number of communication channels, we develop a novel distributed algorithm that recovers strategies with simultaneously vanishing Nash gap (in expected utility, also referred to as exploitability and privacy budget as the number of players increases.
DiffETM: Diffusion Process Enhanced Embedded Topic Model
Jan 01, 2025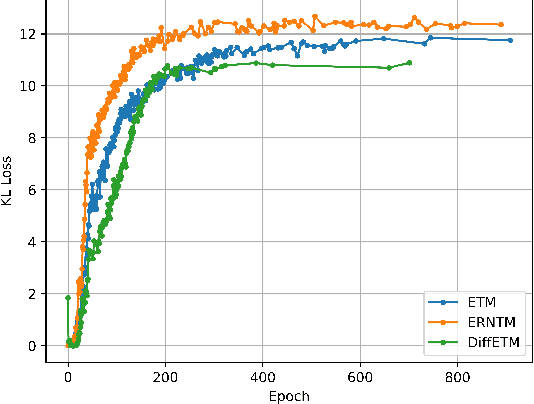
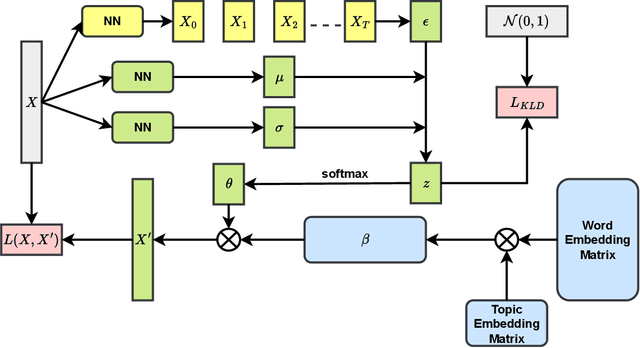
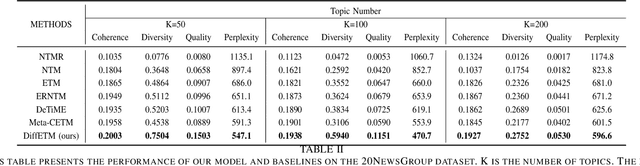
The embedded topic model (ETM) is a widely used approach that assumes the sampled document-topic distribution conforms to the logistic normal distribution for easier optimization. However, this assumption oversimplifies the real document-topic distribution, limiting the model's performance. In response, we propose a novel method that introduces the diffusion process into the sampling process of document-topic distribution to overcome this limitation and maintain an easy optimization process. We validate our method through extensive experiments on two mainstream datasets, proving its effectiveness in improving topic modeling performance.