 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSePO: Self-Evolving Prompt Agent for System Prompt Optimization
Jun 03, 2026System prompt optimization improves agent behavior without modifying the underlying model, yielding human-readable, model-agnostic instructions. Existing methods build a prompt agent that refines task agents' system prompts, yet leave the prompt agent's own system prompt hand-engineered and fixed. We propose Self-Evolving Prompt Optimization (SePO), which treats the prompt agent's own system prompt as an optimization target alongside task agents' system prompts. SePO adopts a self-referential design. A single prompt agent improves both task agents' system prompts and its own under an open-ended evolutionary search that maintains an archive of candidate prompts as stepping stones. Training proceeds in two stages: pre-training evolves the prompt agent on a multi-task pool, and fine-tuning then applies it to a target task. Across five benchmarks spanning math (AIME'25), abstract reasoning (ARC-AGI-1), graduate-level science (GPQA), code generation (MBPP), and logic puzzles (Sudoku), SePO consistently outperforms Manual-CoT, TextGrad, and MetaSPO, improving the average accuracy by 4.49 points compared to Manual-CoT. The prompt optimization skill from pre-training also generalizes to tasks beyond the pre-training mixture, rather than memorizing per-task prompts.
IFPV: An Integrated Multi-Agent Framework for Generative Operational Planning and High-Fidelity Plan Verification
May 14, 2026Operational plan generation and verification are critical for modern complex and rapidly changing battlefield environments, yet traditional generation and verification methods still respectively face the challenges of generation infeasibility and verification insufficiency. To alleviate these limitations, we propose an Integrated Multi-Agent Framework for Generative Operational Planning and High-Fidelity Plan Verification (IFPV). IFPV consists of two tightly coupled modules: Multi-Perspective Hierarchical Agents (MPHA) for generative operational planning and an Adversarial Cognitive Simulation Engine (ACSE) for high-fidelity adversarial plan verification. MPHA decomposes commander intent into executable multi-platform tactical action sequences through the collaboration of Pathfinder, Analyst, and Planner agents. ACSE introduces an opponent equipped with a customized world model, which predicts the future evolution of mission-critical platforms and conducts dynamic counteractions against candidate plans. Simulation experiments in the Asymmetric Combat Tactic Simulator (ACTS) show that IFPV improves mission success by 19.4% and reduces operational cost by 41.7% compared with a single-step large language model (LLM) planning baseline. Compared with a traditional rule-based validator, ACSE increases the average suppression rate by 31.8%, indicating that the proposed verification environment is stricter and more discriminative in revealing the latent vulnerabilities of candidate plans. The code for IFPV can be found at https://github.com/zhigao3ks/IFPV.
VC-Soup: Value-Consistency Guided Multi-Value Alignment for Large Language Models
Mar 18, 2026As large language models (LLMs) increasingly shape content generation, interaction, and decision-making across the Web, aligning them with human values has become a central objective in trustworthy AI. This challenge becomes even more pronounced when aligning multiple, potentially conflicting human values. Although recent approaches, such as reward reweighting, prompt-based supervised fine-tuning, and model merging, attempt to tackle multi-value alignment, they still face two major limitations: (1) training separate models for each value combination is prohibitively expensive; (2) value conflicts substantially degrade alignment performance. These limitations make it difficult to achieve favorable trade-offs across diverse human values. To address these challenges, we revisit multi-value alignment from the perspective of value consistency in data and propose VC-soup, a data filtering and parameter merging framework grounded in value-consistent learning. We first design a value consistency metric based on the cosine similarity between the reward-gap vector of each preference pair and an all-ones vector, which quantifies its cross-value coherence. We then filter out low-consistency preference pairs in each value dataset and train on the remaining data to obtain smooth, value-consistent policy models that better preserve linear mode connectivity. Finally, we linearly combine these policies and apply Pareto filtering across values to obtain solutions with balanced multi-value performance. Extensive experiments and theoretical analysis demonstrate that VC-soup effectively mitigates conflicts and consistently outperforms existing multi-value alignment methods.
Bridging the Skill Gap in Clinical CBCT Interpretation with CBCTRepD
Mar 11, 2026Generative AI has advanced rapidly in medical report generation; however, its application to oral and maxillofacial CBCT reporting remains limited, largely because of the scarcity of high-quality paired CBCT-report data and the intrinsic complexity of volumetric CBCT interpretation. To address this, we introduce CBCTRepD, a bilingual oral and maxillofacial CBCT report-generation system designed for integration into routine radiologist-AI co-authoring workflows. We curated a large-scale, high-quality paired CBCT-report dataset comprising approximately 7,408 studies, covering 55 oral disease entities across diverse acquisition settings, and used it to develop the system. We further established a clinically grounded, multi-level evaluation framework that assesses both direct AI-generated drafts and radiologist-edited collaboration reports using automatic metrics together with radiologist- and clinician-centered evaluation. Using this framework, we show that CBCTRepD achieves superior report-generation performance and produces drafts with writing quality and standardization comparable to those of intermediate radiologists. More importantly, in radiologist-AI collaboration, CBCTRepD provides consistent and clinically meaningful benefits across experience levels: it helps novice radiologists improve toward intermediate-level reporting, enables intermediate radiologists to approach senior-level performance, and even assists senior radiologists by reducing omission-related errors, including clinically important missed lesions. By improving report structure, reducing omissions, and promoting attention to co-existing lesions across anatomical regions, CBCTRepD shows strong and reliable potential as a practical assistant for real-world CBCT reporting across multi-level care settings.
Merging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
RouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
From Atom to Community: Structured and Evolving Agent Memory for User Behavior Modeling
Jan 26, 2026User behavior modeling lies at the heart of personalized applications like recommender systems. With LLM-based agents, user preference representation has evolved from latent embeddings to semantic memory. While existing memory mechanisms show promise in textual dialogues, modeling non-textual behaviors remains challenging, as preferences must be inferred from implicit signals like clicks without ground truth supervision. Current approaches rely on a single unstructured summary, updated through simple overwriting. However, this is suboptimal: users exhibit multi-faceted interests that get conflated, preferences evolve yet naive overwriting causes forgetting, and sparse individual interactions necessitate collaborative signals. We present STEAM (\textit{\textbf{ST}ructured and \textbf{E}volving \textbf{A}gent \textbf{M}emory}), a novel framework that reimagines how agent memory is organized and updated. STEAM decomposes preferences into atomic memory units, each capturing a distinct interest dimension with explicit links to observed behaviors. To exploit collaborative patterns, STEAM organizes similar memories across users into communities and generates prototype memories for signal propagation. The framework further incorporates adaptive evolution mechanisms, including consolidation for refining memories and formation for capturing emerging interests. Experiments on three real-world datasets demonstrate that STEAM substantially outperforms state-of-the-art baselines in recommendation accuracy, simulation fidelity, and diversity.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
RecGPT-V2 Technical Report
Dec 16, 2025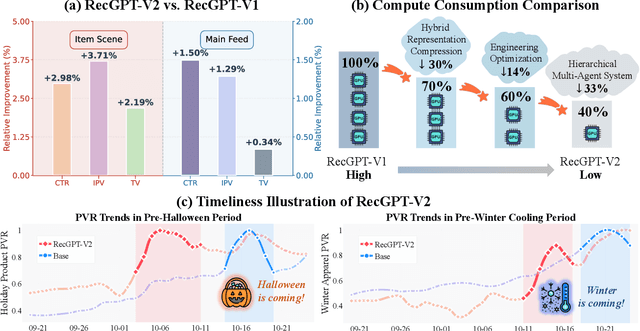
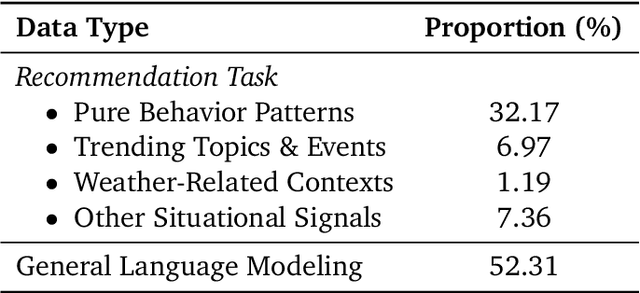
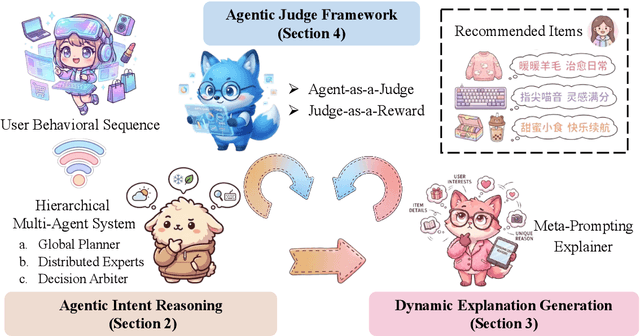

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
A Survey on Generative Recommendation: Data, Model, and Tasks
Oct 31, 2025Recommender systems serve as foundational infrastructure in modern information ecosystems, helping users navigate digital content and discover items aligned with their preferences. At their core, recommender systems address a fundamental problem: matching users with items. Over the past decades, the field has experienced successive paradigm shifts, from collaborative filtering and matrix factorization in the machine learning era to neural architectures in the deep learning era. Recently, the emergence of generative models, especially large language models (LLMs) and diffusion models, have sparked a new paradigm: generative recommendation, which reconceptualizes recommendation as a generation task rather than discriminative scoring. This survey provides a comprehensive examination through a unified tripartite framework spanning data, model, and task dimensions. Rather than simply categorizing works, we systematically decompose approaches into operational stages-data augmentation and unification, model alignment and training, task formulation and execution. At the data level, generative models enable knowledge-infused augmentation and agent-based simulation while unifying heterogeneous signals. At the model level, we taxonomize LLM-based methods, large recommendation models, and diffusion approaches, analyzing their alignment mechanisms and innovations. At the task level, we illuminate new capabilities including conversational interaction, explainable reasoning, and personalized content generation. We identify five key advantages: world knowledge integration, natural language understanding, reasoning capabilities, scaling laws, and creative generation. We critically examine challenges in benchmark design, model robustness, and deployment efficiency, while charting a roadmap toward intelligent recommendation assistants that fundamentally reshape human-information interaction.