 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSirenFNO: Efficient and Full Frequency Learning of Fourier Neural Operators
Jun 09, 2026Fourier neural operators (FNOs) are effective and efficient surrogates for approximating solutions of PDEs and generalize across discretizations. However, owing to the reliance on frequency truncation to maintain learning efficiency of FNOs, empirical studies suggest that FNOs exhibit spectral bias toward low-frequency information, which may hinder the learning capability especially for certain PDEs with strong high-frequency oscillations. To address this limitation, we propose SirenFNO, a novel framework that leverages sinusoidal representation networks (SIRENs) to learn implicit neural representations and performs mode-wise kernel parameterization. Our SIREN parameterization learns a full-grid spectrum with a constant and discretization-independent parameter count, thereby eliminating the need for frequency truncation. We further extend SirenFNO with functional tensor decompositions to enhance parameter and learning efficiency. Empirical results show that our SirenFNO consistently outperforms FNO with approximately $4$ to $15$ times parameter reductions with preserved discretization invariance, and our functional decomposition variants obtain performance improvements with a maximum of $73$ times fewer parameters across multiple PDE benchmarks.
MoEMeta: Mixture-of-Experts Meta Learning for Few-Shot Relational Learning
Oct 27, 2025Few-shot knowledge graph relational learning seeks to perform reasoning over relations given only a limited number of training examples. While existing approaches largely adopt a meta-learning framework for enabling fast adaptation to new relations, they suffer from two key pitfalls. First, they learn relation meta-knowledge in isolation, failing to capture common relational patterns shared across tasks. Second, they struggle to effectively incorporate local, task-specific contexts crucial for rapid adaptation. To address these limitations, we propose MoEMeta, a novel meta-learning framework that disentangles globally shared knowledge from task-specific contexts to enable both effective generalization and rapid adaptation. MoEMeta introduces two key innovations: (i) a mixture-of-experts (MoE) model that learns globally shared relational prototypes to enhance generalization, and (ii) a task-tailored adaptation mechanism that captures local contexts for fast task-specific adaptation. By balancing global generalization with local adaptability, MoEMeta significantly advances few-shot relational learning. Extensive experiments and analyses on three KG benchmarks demonstrate that MoEMeta consistently outperforms existing baselines, achieving state-of-the-art performance.
Unbiased Online Curvature Approximation for Regularized Graph Continual Learning
Sep 16, 2025



Graph continual learning (GCL) aims to learn from a continuous sequence of graph-based tasks. Regularization methods are vital for preventing catastrophic forgetting in GCL, particularly in the challenging replay-free, class-incremental setting, where each task consists of a set of unique classes. In this work, we first establish a general regularization framework for GCL based on the curved parameter space induced by the Fisher information matrix (FIM). We show that the dominant Elastic Weight Consolidation (EWC) and its variants are a special case within this framework, using a diagonal approximation of the empirical FIM based on parameters from previous tasks. To overcome their limitations, we propose a new unbiased online curvature approximation of the full FIM based on the model's current learning state. Our method directly estimates the regularization term in an online manner without explicitly evaluating and storing the FIM itself. This enables the model to better capture the loss landscape during learning new tasks while retaining the knowledge learned from previous tasks. Extensive experiments on three graph datasets demonstrate that our method significantly outperforms existing regularization-based methods, achieving a superior trade-off between stability (retaining old knowledge) and plasticity (acquiring new knowledge).
Prompted Meta-Learning for Few-shot Knowledge Graph Completion
May 08, 2025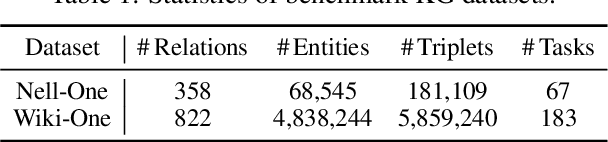



Few-shot knowledge graph completion (KGC) has obtained significant attention due to its practical applications in real-world scenarios, where new knowledge often emerges with limited available data. While most existing methods for few-shot KGC have predominantly focused on leveraging relational information, rich semantics inherent in KGs have been largely overlooked. To address this gap, we propose a novel prompted meta-learning (PromptMeta) framework that seamlessly integrates meta-semantics with relational information for few-shot KGC. PrompMeta has two key innovations: (1) a meta-semantic prompt pool that captures and consolidates high-level meta-semantics, enabling effective knowledge transfer and adaptation to rare and newly emerging relations. (2) a learnable fusion prompt that dynamically combines meta-semantic information with task-specific relational information tailored to different few-shot tasks. Both components are optimized together with model parameters within a meta-learning framework. Extensive experiments on two benchmark datasets demonstrate the effectiveness of our approach.
Multi-Granular Attention based Heterogeneous Hypergraph Neural Network
May 07, 2025



Heterogeneous graph neural networks (HeteGNNs) have demonstrated strong abilities to learn node representations by effectively extracting complex structural and semantic information in heterogeneous graphs. Most of the prevailing HeteGNNs follow the neighborhood aggregation paradigm, leveraging meta-path based message passing to learn latent node representations. However, due to the pairwise nature of meta-paths, these models fail to capture high-order relations among nodes, resulting in suboptimal performance. Additionally, the challenge of ``over-squashing'', where long-range message passing in HeteGNNs leads to severe information distortion, further limits the efficacy of these models. To address these limitations, this paper proposes MGA-HHN, a Multi-Granular Attention based Heterogeneous Hypergraph Neural Network for heterogeneous graph representation learning. MGA-HHN introduces two key innovations: (1) a novel approach for constructing meta-path based heterogeneous hypergraphs that explicitly models higher-order semantic information in heterogeneous graphs through multiple views, and (2) a multi-granular attention mechanism that operates at both the node and hyperedge levels. This mechanism enables the model to capture fine-grained interactions among nodes sharing the same semantic context within a hyperedge type, while preserving the diversity of semantics across different hyperedge types. As such, MGA-HHN effectively mitigates long-range message distortion and generates more expressive node representations. Extensive experiments on real-world benchmark datasets demonstrate that MGA-HHN outperforms state-of-the-art models, showcasing its effectiveness in node classification, node clustering and visualization tasks.
An Attack Traffic Identification Method Based on Temporal Spectrum
Nov 12, 2024



To address the issues of insufficient robustness, unstable features, and data noise interference in existing network attack detection and identification models, this paper proposes an attack traffic detection and identification method based on temporal spectrum. First, traffic data is segmented by a sliding window to construct a feature sequence and a corresponding label sequence for network traffic. Next, the proposed spectral label generation methods, SSPE and COAP, are applied to transform the label sequence into spectral labels and the feature sequence into temporal features. Spectral labels and temporal features are used to capture and represent behavioral patterns of attacks. Finally, the constructed temporal features and spectral labels are used to train models, which subsequently detects and identifies network attack behaviors. Experimental results demonstrate that compared to traditional methods, models trained with the SSPE or COAP method improve identification accuracy by 10%, and exhibit strong robustness, particularly in noisy environments.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024

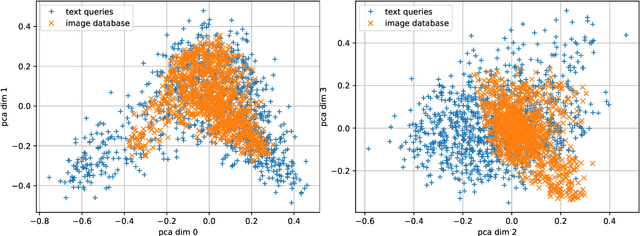

The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
Disentangled Acoustic Fields For Multimodal Physical Scene Understanding
Jul 16, 2024



We study the problem of multimodal physical scene understanding, where an embodied agent needs to find fallen objects by inferring object properties, direction, and distance of an impact sound source. Previous works adopt feed-forward neural networks to directly regress the variables from sound, leading to poor generalization and domain adaptation issues. In this paper, we illustrate that learning a disentangled model of acoustic formation, referred to as disentangled acoustic field (DAF), to capture the sound generation and propagation process, enables the embodied agent to construct a spatial uncertainty map over where the objects may have fallen. We demonstrate that our analysis-by-synthesis framework can jointly infer sound properties by explicitly decomposing and factorizing the latent space of the disentangled model. We further show that the spatial uncertainty map can significantly improve the success rate for the localization of fallen objects by proposing multiple plausible exploration locations.
Ground-Fusion: A Low-cost Ground SLAM System Robust to Corner Cases
Feb 22, 2024We introduce Ground-Fusion, a low-cost sensor fusion simultaneous localization and mapping (SLAM) system for ground vehicles. Our system features efficient initialization, effective sensor anomaly detection and handling, real-time dense color mapping, and robust localization in diverse environments. We tightly integrate RGB-D images, inertial measurements, wheel odometer and GNSS signals within a factor graph to achieve accurate and reliable localization both indoors and outdoors. To ensure successful initialization, we propose an efficient strategy that comprises three different methods: stationary, visual, and dynamic, tailored to handle diverse cases. Furthermore, we develop mechanisms to detect sensor anomalies and degradation, handling them adeptly to maintain system accuracy. Our experimental results on both public and self-collected datasets demonstrate that Ground-Fusion outperforms existing low-cost SLAM systems in corner cases. We release the code and datasets at https://github.com/SJTU-ViSYS/Ground-Fusion.
Adaptive Hierarchical Origami Metastructures
Nov 29, 2023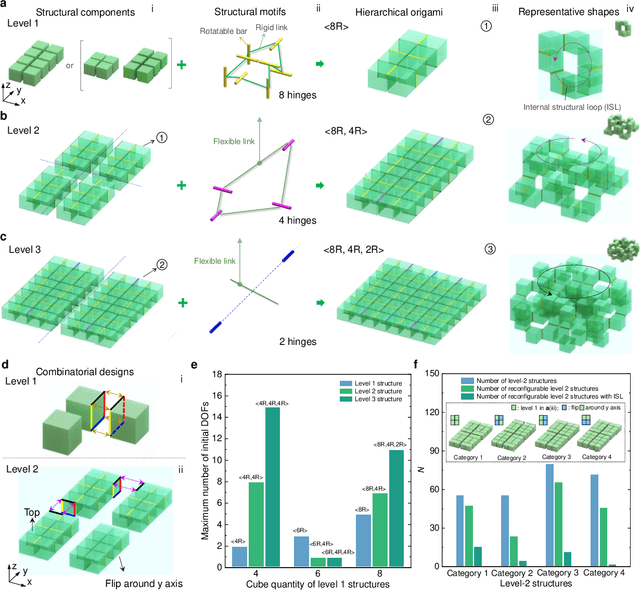
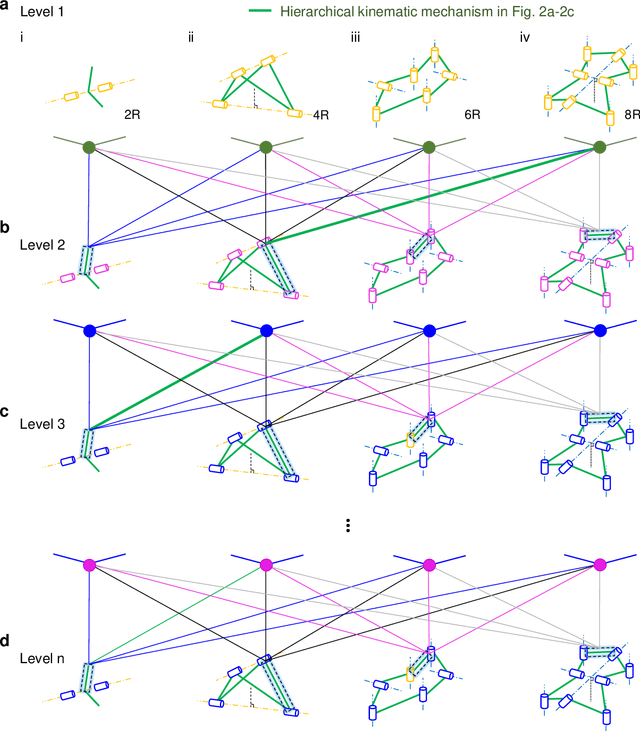
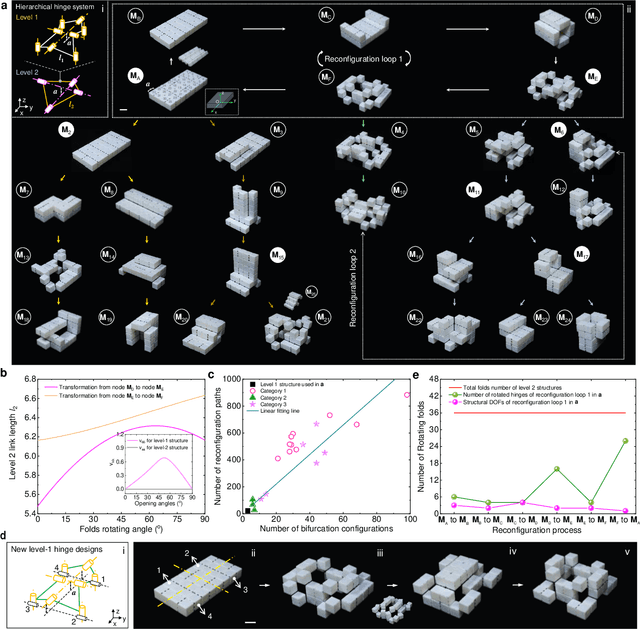
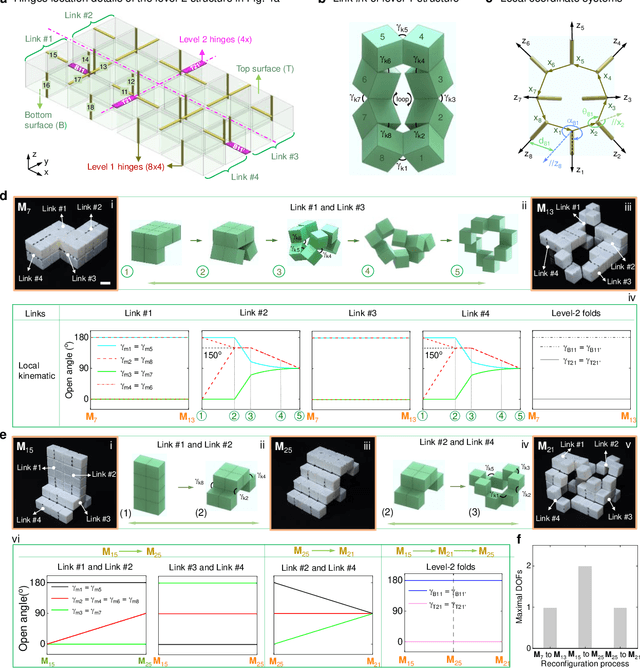
Shape-morphing capabilities are crucial for enabling multifunctionality in both biological and artificial systems. Various strategies for shape morphing have been proposed for applications in metamaterials and robotics. However, few of these approaches have achieved the ability to seamlessly transform into a multitude of volumetric shapes post-fabrication using a relatively simple actuation and control mechanism. Taking inspiration from thick origami and hierarchies in nature, we present a new hierarchical construction method based on polyhedrons to create an extensive library of compact origami metastructures. We show that a single hierarchical origami structure can autonomously adapt to over 103 versatile architectural configurations, achieved with the utilization of fewer than 3 actuation degrees of freedom and employing simple transition kinematics. We uncover the fundamental principles governing theses shape transformation through theoretical models. Furthermore, we also demonstrate the wide-ranging potential applications of these transformable hierarchical structures. These include their uses as untethered and autonomous robotic transformers capable of various gait-shifting and multidirectional locomotion, as well as rapidly self-deployable and self-reconfigurable architecture, exemplifying its scalability up to the meter scale. Lastly, we introduce the concept of multitask reconfigurable and deployable space robots and habitats, showcasing the adaptability and versatility of these metastructures.