 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI-Empowered Dynamic Survey Framework
Feb 03, 2026Survey papers play a central role in synthesizing and organizing scientific knowledge, yet they are increasingly strained by the rapid growth of research output. As new work continues to appear after publication, surveys quickly become outdated, contributing to redundancy and fragmentation in the literature. We reframe survey writing as a long-horizon maintenance problem rather than a one-time generation task, treating surveys as living documents that evolve alongside the research they describe. We propose an agentic Dynamic Survey Framework that supports the continuous updating of existing survey papers by incrementally integrating new work while preserving survey structure and minimizing unnecessary disruption. Using a retrospective experimental setup, we demonstrate that the proposed framework effectively identifies and incorporates emerging research while preserving the coherence and structure of existing surveys.
MMHOI: Modeling Complex 3D Multi-Human Multi-Object Interactions
Oct 09, 2025



Real-world scenes often feature multiple humans interacting with multiple objects in ways that are causal, goal-oriented, or cooperative. Yet existing 3D human-object interaction (HOI) benchmarks consider only a fraction of these complex interactions. To close this gap, we present MMHOI -- a large-scale, Multi-human Multi-object Interaction dataset consisting of images from 12 everyday scenarios. MMHOI offers complete 3D shape and pose annotations for every person and object, along with labels for 78 action categories and 14 interaction-specific body parts, providing a comprehensive testbed for next-generation HOI research. Building on MMHOI, we present MMHOI-Net, an end-to-end transformer-based neural network for jointly estimating human-object 3D geometries, their interactions, and associated actions. A key innovation in our framework is a structured dual-patch representation for modeling objects and their interactions, combined with action recognition to enhance the interaction prediction. Experiments on MMHOI and the recently proposed CORE4D datasets demonstrate that our approach achieves state-of-the-art performance in multi-HOI modeling, excelling in both accuracy and reconstruction quality.
Noise Consistency Regularization for Improved Subject-Driven Image Synthesis
Jun 06, 2025Fine-tuning Stable Diffusion enables subject-driven image synthesis by adapting the model to generate images containing specific subjects. However, existing fine-tuning methods suffer from two key issues: underfitting, where the model fails to reliably capture subject identity, and overfitting, where it memorizes the subject image and reduces background diversity. To address these challenges, we propose two auxiliary consistency losses for diffusion fine-tuning. First, a prior consistency regularization loss ensures that the predicted diffusion noise for prior (non-subject) images remains consistent with that of the pretrained model, improving fidelity. Second, a subject consistency regularization loss enhances the fine-tuned model's robustness to multiplicative noise modulated latent code, helping to preserve subject identity while improving diversity. Our experimental results demonstrate that incorporating these losses into fine-tuning not only preserves subject identity but also enhances image diversity, outperforming DreamBooth in terms of CLIP scores, background variation, and overall visual quality.
Improving Open-World Object Localization by Discovering Background
Apr 24, 2025



Our work addresses the problem of learning to localize objects in an open-world setting, i.e., given the bounding box information of a limited number of object classes during training, the goal is to localize all objects, belonging to both the training and unseen classes in an image, during inference. Towards this end, recent work in this area has focused on improving the characterization of objects either explicitly by proposing new objective functions (localization quality) or implicitly using object-centric auxiliary-information, such as depth information, pixel/region affinity map etc. In this work, we address this problem by incorporating background information to guide the learning of the notion of objectness. Specifically, we propose a novel framework to discover background regions in an image and train an object proposal network to not detect any objects in these regions. We formulate the background discovery task as that of identifying image regions that are not discriminative, i.e., those that are redundant and constitute low information content. We conduct experiments on standard benchmarks to showcase the effectiveness of our proposed approach and observe significant improvements over the previous state-of-the-art approaches for this task.
ComplexVAD: Detecting Interaction Anomalies in Video
Jan 16, 2025Existing video anomaly detection datasets are inadequate for representing complex anomalies that occur due to the interactions between objects. The absence of complex anomalies in previous video anomaly detection datasets affects research by shifting the focus onto simple anomalies. To address this problem, we introduce a new large-scale dataset: ComplexVAD. In addition, we propose a novel method to detect complex anomalies via modeling the interactions between objects using a scene graph with spatio-temporal attributes. With our proposed method and two other state-of-the-art video anomaly detection methods, we obtain baseline scores on ComplexVAD and demonstrate that our new method outperforms existing works.
SoundLoc3D: Invisible 3D Sound Source Localization and Classification Using a Multimodal RGB-D Acoustic Camera
Dec 22, 2024Accurately localizing 3D sound sources and estimating their semantic labels -- where the sources may not be visible, but are assumed to lie on the physical surface of objects in the scene -- have many real applications, including detecting gas leak and machinery malfunction. The audio-visual weak-correlation in such setting poses new challenges in deriving innovative methods to answer if or how we can use cross-modal information to solve the task. Towards this end, we propose to use an acoustic-camera rig consisting of a pinhole RGB-D camera and a coplanar four-channel microphone array~(Mic-Array). By using this rig to record audio-visual signals from multiviews, we can use the cross-modal cues to estimate the sound sources 3D locations. Specifically, our framework SoundLoc3D treats the task as a set prediction problem, each element in the set corresponds to a potential sound source. Given the audio-visual weak-correlation, the set representation is initially learned from a single view microphone array signal, and then refined by actively incorporating physical surface cues revealed from multiview RGB-D images. We demonstrate the efficiency and superiority of SoundLoc3D on large-scale simulated dataset, and further show its robustness to RGB-D measurement inaccuracy and ambient noise interference.
* Accepted by WACV2025
Manual-PA: Learning 3D Part Assembly from Instruction Diagrams
Nov 27, 2024



Assembling furniture amounts to solving the discrete-continuous optimization task of selecting the furniture parts to assemble and estimating their connecting poses in a physically realistic manner. The problem is hampered by its combinatorially large yet sparse solution space thus making learning to assemble a challenging task for current machine learning models. In this paper, we attempt to solve this task by leveraging the assembly instructions provided in diagrammatic manuals that typically accompany the furniture parts. Our key insight is to use the cues in these diagrams to split the problem into discrete and continuous phases. Specifically, we present Manual-PA, a transformer-based instruction Manual-guided 3D Part Assembly framework that learns to semantically align 3D parts with their illustrations in the manuals using a contrastive learning backbone towards predicting the assembly order and infers the 6D pose of each part via relating it to the final furniture depicted in the manual. To validate the efficacy of our method, we conduct experiments on the benchmark PartNet dataset. Our results show that using the diagrams and the order of the parts lead to significant improvements in assembly performance against the state of the art. Further, Manual-PA demonstrates strong generalization to real-world IKEA furniture assembly on the IKEA-Manual dataset.
LLMPhy: Complex Physical Reasoning Using Large Language Models and World Models
Nov 12, 2024Physical reasoning is an important skill needed for robotic agents when operating in the real world. However, solving such reasoning problems often involves hypothesizing and reflecting over complex multi-body interactions under the effect of a multitude of physical forces and thus learning all such interactions poses a significant hurdle for state-of-the-art machine learning frameworks, including large language models (LLMs). To study this problem, we propose a new physical reasoning task and a dataset, dubbed TraySim. Our task involves predicting the dynamics of several objects on a tray that is given an external impact -- the domino effect of the ensued object interactions and their dynamics thus offering a challenging yet controlled setup, with the goal of reasoning being to infer the stability of the objects after the impact. To solve this complex physical reasoning task, we present LLMPhy, a zero-shot black-box optimization framework that leverages the physics knowledge and program synthesis abilities of LLMs, and synergizes these abilities with the world models built into modern physics engines. Specifically, LLMPhy uses an LLM to generate code to iteratively estimate the physical hyperparameters of the system (friction, damping, layout, etc.) via an implicit analysis-by-synthesis approach using a (non-differentiable) simulator in the loop and uses the inferred parameters to imagine the dynamics of the scene towards solving the reasoning task. To show the effectiveness of LLMPhy, we present experiments on our TraySim dataset to predict the steady-state poses of the objects. Our results show that the combination of the LLM and the physics engine leads to state-of-the-art zero-shot physical reasoning performance, while demonstrating superior convergence against standard black-box optimization methods and better estimation of the physical parameters.
Temporally Grounding Instructional Diagrams in Unconstrained Videos
Jul 16, 2024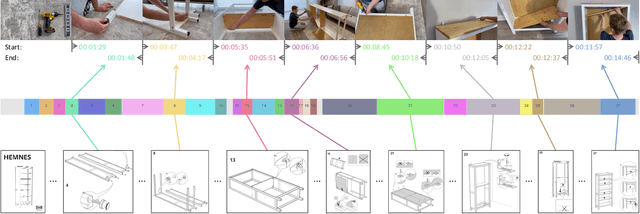
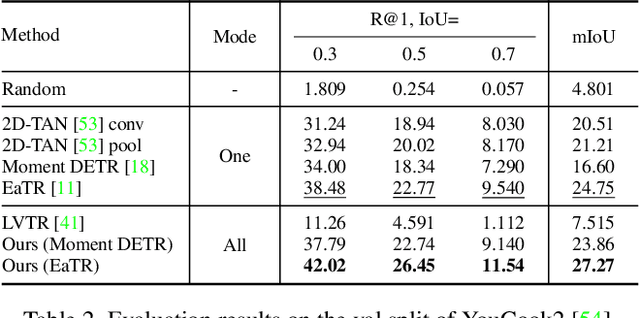
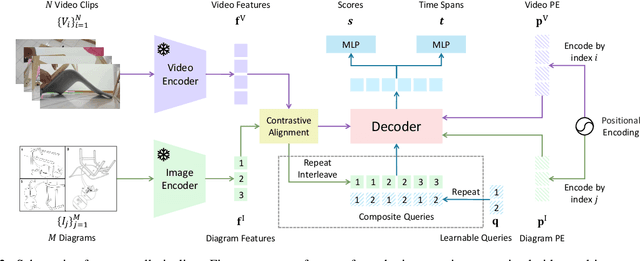
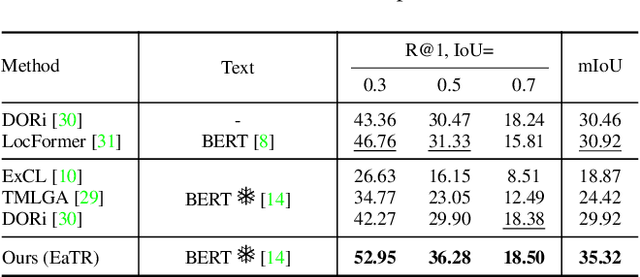
We study the challenging problem of simultaneously localizing a sequence of queries in the form of instructional diagrams in a video. This requires understanding not only the individual queries but also their interrelationships. However, most existing methods focus on grounding one query at a time, ignoring the inherent structures among queries such as the general mutual exclusiveness and the temporal order. Consequently, the predicted timespans of different step diagrams may overlap considerably or violate the temporal order, thus harming the accuracy. In this paper, we tackle this issue by simultaneously grounding a sequence of step diagrams. Specifically, we propose composite queries, constructed by exhaustively pairing up the visual content features of the step diagrams and a fixed number of learnable positional embeddings. Our insight is that self-attention among composite queries carrying different content features suppress each other to reduce timespan overlaps in predictions, while the cross-attention corrects the temporal misalignment via content and position joint guidance. We demonstrate the effectiveness of our approach on the IAW dataset for grounding step diagrams and the YouCook2 benchmark for grounding natural language queries, significantly outperforming existing methods while simultaneously grounding multiple queries.
Disentangled Acoustic Fields For Multimodal Physical Scene Understanding
Jul 16, 2024



We study the problem of multimodal physical scene understanding, where an embodied agent needs to find fallen objects by inferring object properties, direction, and distance of an impact sound source. Previous works adopt feed-forward neural networks to directly regress the variables from sound, leading to poor generalization and domain adaptation issues. In this paper, we illustrate that learning a disentangled model of acoustic formation, referred to as disentangled acoustic field (DAF), to capture the sound generation and propagation process, enables the embodied agent to construct a spatial uncertainty map over where the objects may have fallen. We demonstrate that our analysis-by-synthesis framework can jointly infer sound properties by explicitly decomposing and factorizing the latent space of the disentangled model. We further show that the spatial uncertainty map can significantly improve the success rate for the localization of fallen objects by proposing multiple plausible exploration locations.