 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
May 25, 2026Success in generative modeling across language, image, and video demonstrates that large, well-curated datasets are the key driver for building capable models. 3D Human motion, however, has lagged behind, constrained by an unsatisfying choice between small, high-fidelity motion capture datasets and large-scale in-the-wild collections dominated by static or low-quality sequences. We introduce RoMo, a rich, large-scale, carefully curated dataset of in-the-wild human motions that resolves these tradeoffs. To ensure quality, we introduce a taxonomy-aware filtering pipeline that aggressively removes static and artifact-prone sequences. Every sequence is annotated with detailed captions and organized by a novel three-level semantic taxonomy. This hierarchical structure enables fine-grained, per-category evaluation, that reveals model strengths and weaknesses obscured by global metrics. We demonstrate that models trained on RoMo achieve state-of-the-art fidelity and diversity while gaining a superior understanding of complex, subtle text prompts. Finally, we release the Motion Toolbox to standardize metrics, data conversion, and visualization, establishing a foundation for reproducible and interpretable motion generation research.
Learning Lifted Action Models from Unsupervised Visual Traces
Apr 21, 2026Efficient construction of models capturing the preconditions and effects of actions is essential for applying AI planning in real-world domains. Extensive prior work has explored learning such models from high-level descriptions of state and/or action sequences. In this paper, we tackle a more challenging setting: learning lifted action models from sequences of state images, without action observation. We propose a deep learning framework that jointly learns state prediction, action prediction, and a lifted action model. We also introduce a mixed-integer linear program (MILP) to prevent prediction collapse and self-reinforcing errors among predictions. The MILP takes the predicted states, actions, and action model over a subset of traces and solves for logically consistent states, actions, and action model that are as close as possible to the original predictions. Pseudo-labels extracted from the MILP solution are then used to guide further training. Experiments across multiple domains show that integrating MILP-based correction helps the model escape local optima and converge toward globally consistent solutions.
Flexible Geometric Guidance for Probabilistic Human Pose Estimation with Diffusion Models
Feb 03, 20263D human pose estimation from 2D images is a challenging problem due to depth ambiguity and occlusion. Because of these challenges the task is underdetermined, where there exists multiple -- possibly infinite -- poses that are plausible given the image. Despite this, many prior works assume the existence of a deterministic mapping and estimate a single pose given an image. Furthermore, methods based on machine learning require a large amount of paired 2D-3D data to train and suffer from generalization issues to unseen scenarios. To address both of these issues, we propose a framework for pose estimation using diffusion models, which enables sampling from a probability distribution over plausible poses which are consistent with a 2D image. Our approach falls under the guidance framework for conditional generation, and guides samples from an unconditional diffusion model, trained only on 3D data, using the gradients of the heatmaps from a 2D keypoint detector. We evaluate our method on the Human 3.6M dataset under best-of-$m$ multiple hypothesis evaluation, showing state-of-the-art performance among methods which do not require paired 2D-3D data for training. We additionally evaluate the generalization ability using the MPI-INF-3DHP and 3DPW datasets and demonstrate competitive performance. Finally, we demonstrate the flexibility of our framework by using it for novel tasks including pose generation and pose completion, without the need to train bespoke conditional models. We make code available at https://github.com/fsnelgar/diffusion_pose .
Gromov Wasserstein Optimal Transport for Semantic Correspondences
Feb 03, 2026Establishing correspondences between image pairs is a long studied problem in computer vision. With recent large-scale foundation models showing strong zero-shot performance on downstream tasks including classification and segmentation, there has been interest in using the internal feature maps of these models for the semantic correspondence task. Recent works observe that features from DINOv2 and Stable Diffusion (SD) are complementary, the former producing accurate but sparse correspondences, while the latter produces spatially consistent correspondences. As a result, current state-of-the-art methods for semantic correspondence involve combining features from both models in an ensemble. While the performance of these methods is impressive, they are computationally expensive, requiring evaluating feature maps from large-scale foundation models. In this work we take a different approach, instead replacing SD features with a superior matching algorithm which is imbued with the desirable spatial consistency property. Specifically, we replace the standard nearest neighbours matching with an optimal transport algorithm that includes a Gromov Wasserstein spatial smoothness prior. We show that we can significantly boost the performance of the DINOv2 baseline, and be competitive and sometimes surpassing state-of-the-art methods using Stable Diffusion features, while being 5--10x more efficient. We make code available at https://github.com/fsnelgar/semantic_matching_gwot .
Sharper Convergence Rates for Nonconvex Optimisation via Reduction Mappings
Jun 10, 2025



Many high-dimensional optimisation problems exhibit rich geometric structures in their set of minimisers, often forming smooth manifolds due to over-parametrisation or symmetries. When this structure is known, at least locally, it can be exploited through reduction mappings that reparametrise part of the parameter space to lie on the solution manifold. These reductions naturally arise from inner optimisation problems and effectively remove redundant directions, yielding a lower-dimensional objective. In this work, we introduce a general framework to understand how such reductions influence the optimisation landscape. We show that well-designed reduction mappings improve curvature properties of the objective, leading to better-conditioned problems and theoretically faster convergence for gradient-based methods. Our analysis unifies a range of scenarios where structural information at optimality is leveraged to accelerate convergence, offering a principled explanation for the empirical gains observed in such optimisation algorithms.
DiSA: Diffusion Step Annealing in Autoregressive Image Generation
May 26, 2025



An increasing number of autoregressive models, such as MAR, FlowAR, xAR, and Harmon adopt diffusion sampling to improve the quality of image generation. However, this strategy leads to low inference efficiency, because it usually takes 50 to 100 steps for diffusion to sample a token. This paper explores how to effectively address this issue. Our key motivation is that as more tokens are generated during the autoregressive process, subsequent tokens follow more constrained distributions and are easier to sample. To intuitively explain, if a model has generated part of a dog, the remaining tokens must complete the dog and thus are more constrained. Empirical evidence supports our motivation: at later generation stages, the next tokens can be well predicted by a multilayer perceptron, exhibit low variance, and follow closer-to-straight-line denoising paths from noise to tokens. Based on our finding, we introduce diffusion step annealing (DiSA), a training-free method which gradually uses fewer diffusion steps as more tokens are generated, e.g., using 50 steps at the beginning and gradually decreasing to 5 steps at later stages. Because DiSA is derived from our finding specific to diffusion in autoregressive models, it is complementary to existing acceleration methods designed for diffusion alone. DiSA can be implemented in only a few lines of code on existing models, and albeit simple, achieves $5-10\times$ faster inference for MAR and Harmon and $1.4-2.5\times$ for FlowAR and xAR, while maintaining the generation quality.
VI3NR: Variance Informed Initialization for Implicit Neural Representations
Apr 27, 2025



Implicit Neural Representations (INRs) are a versatile and powerful tool for encoding various forms of data, including images, videos, sound, and 3D shapes. A critical factor in the success of INRs is the initialization of the network, which can significantly impact the convergence and accuracy of the learned model. Unfortunately, commonly used neural network initializations are not widely applicable for many activation functions, especially those used by INRs. In this paper, we improve upon previous initialization methods by deriving an initialization that has stable variance across layers, and applies to any activation function. We show that this generalizes many previous initialization methods, and has even better stability for well studied activations. We also show that our initialization leads to improved results with INR activation functions in multiple signal modalities. Our approach is particularly effective for Gaussian INRs, where we demonstrate that the theory of our initialization matches with task performance in multiple experiments, allowing us to achieve improvements in image, audio, and 3D surface reconstruction.
Interior Point Differential Dynamic Programming, Redux
Apr 11, 2025



We present IPDDP2, a structure-exploiting algorithm for solving discrete-time, finite horizon optimal control problems with nonlinear constraints. Inequality constraints are handled using a primal-dual interior point formulation and step acceptance for equality constraints follows a line-search filter approach. The iterates of the algorithm are derived under the Differential Dynamic Programming (DDP) framework. Our numerical experiments evaluate IPDDP2 on four robotic motion planning problems. IPDDP2 reliably converges to low optimality error and exhibits local quadratic and global convergence from remote starting points. Notably, we showcase the robustness of IPDDP2 by using it to solve a contact-implicit, joint limited acrobot swing-up problem involving complementarity constraints from a range of initial conditions. We provide a full implementation of IPDDP2 in the Julia programming language.
Scaling Prompt Instructed Zero Shot Composed Image Retrieval with Image-Only Data
Apr 01, 2025



Composed Image Retrieval (CIR) is the task of retrieving images matching a reference image augmented with a text, where the text describes changes to the reference image in natural language. Traditionally, models designed for CIR have relied on triplet data containing a reference image, reformulation text, and a target image. However, curating such triplet data often necessitates human intervention, leading to prohibitive costs. This challenge has hindered the scalability of CIR model training even with the availability of abundant unlabeled data. With the recent advances in foundational models, we advocate a shift in the CIR training paradigm where human annotations can be efficiently replaced by large language models (LLMs). Specifically, we demonstrate the capability of large captioning and language models in efficiently generating data for CIR only relying on unannotated image collections. Additionally, we introduce an embedding reformulation architecture that effectively combines image and text modalities. Our model, named InstructCIR, outperforms state-of-the-art methods in zero-shot composed image retrieval on CIRR and FashionIQ datasets. Furthermore, we demonstrate that by increasing the amount of generated data, our zero-shot model gets closer to the performance of supervised baselines.
ARINAR: Bi-Level Autoregressive Feature-by-Feature Generative Models
Mar 04, 2025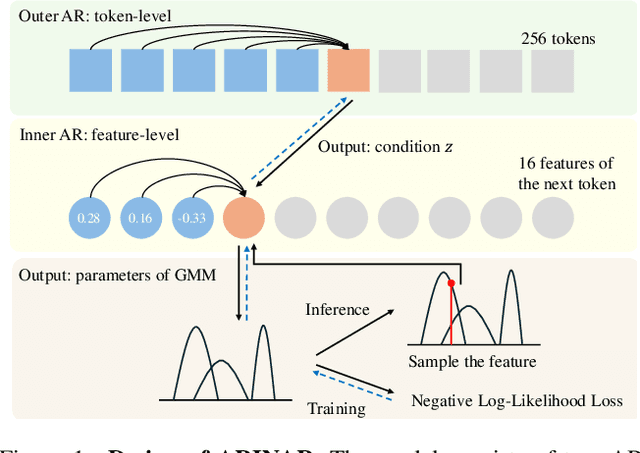
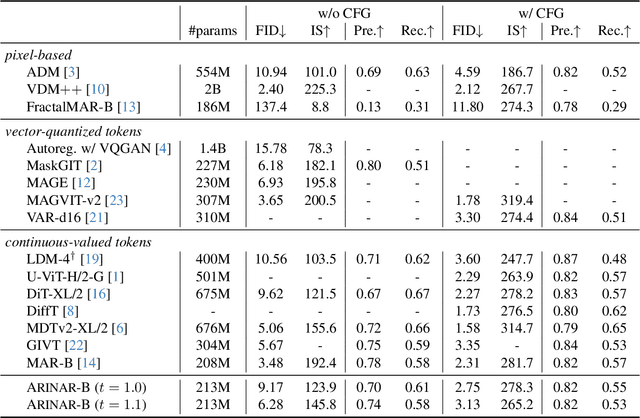
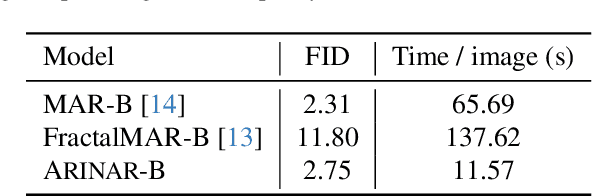

Existing autoregressive (AR) image generative models use a token-by-token generation schema. That is, they predict a per-token probability distribution and sample the next token from that distribution. The main challenge is how to model the complex distribution of high-dimensional tokens. Previous methods either are too simplistic to fit the distribution or result in slow generation speed. Instead of fitting the distribution of the whole tokens, we explore using a AR model to generate each token in a feature-by-feature way, i.e., taking the generated features as input and generating the next feature. Based on that, we propose ARINAR (AR-in-AR), a bi-level AR model. The outer AR layer take previous tokens as input, predicts a condition vector z for the next token. The inner layer, conditional on z, generates features of the next token autoregressively. In this way, the inner layer only needs to model the distribution of a single feature, for example, using a simple Gaussian Mixture Model. On the ImageNet 256x256 image generation task, ARINAR-B with 213M parameters achieves an FID of 2.75, which is comparable to the state-of-the-art MAR-B model (FID=2.31), while five times faster than the latter.