 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Perceptual Artifacts: A Fine-Grained Benchmark for Interpretable AI-Generated Image Detection
Jan 27, 2026Current AI-Generated Image (AIGI) detection approaches predominantly rely on binary classification to distinguish real from synthetic images, often lacking interpretable or convincing evidence to substantiate their decisions. This limitation stems from existing AIGI detection benchmarks, which, despite featuring a broad collection of synthetic images, remain restricted in their coverage of artifact diversity and lack detailed, localized annotations. To bridge this gap, we introduce a fine-grained benchmark towards eXplainable AI-Generated image Detection, named X-AIGD, which provides pixel-level, categorized annotations of perceptual artifacts, spanning low-level distortions, high-level semantics, and cognitive-level counterfactuals. These comprehensive annotations facilitate fine-grained interpretability evaluation and deeper insight into model decision-making processes. Our extensive investigation using X-AIGD provides several key insights: (1) Existing AIGI detectors demonstrate negligible reliance on perceptual artifacts, even at the most basic distortion level. (2) While AIGI detectors can be trained to identify specific artifacts, they still substantially base their judgment on uninterpretable features. (3) Explicitly aligning model attention with artifact regions can increase the interpretability and generalization of detectors. The data and code are available at: https://github.com/Coxy7/X-AIGD.
Probe by Gaming: A Game-based Benchmark for Assessing Conceptual Knowledge in LLMs
May 23, 2025Concepts represent generalized abstractions that enable humans to categorize and reason efficiently, yet it is unclear to what extent Large Language Models (LLMs) comprehend these semantic relationships. Existing benchmarks typically focus on factual recall and isolated tasks, failing to evaluate the ability of LLMs to understand conceptual boundaries. To address this gap, we introduce CK-Arena, a multi-agent interaction game built upon the Undercover game, designed to evaluate the capacity of LLMs to reason with concepts in interactive settings. CK-Arena challenges models to describe, differentiate, and infer conceptual boundaries based on partial information, encouraging models to explore commonalities and distinctions between closely related concepts. By simulating real-world interaction, CK-Arena provides a scalable and realistic benchmark for assessing conceptual reasoning in dynamic environments. Experimental results show that LLMs' understanding of conceptual knowledge varies significantly across different categories and is not strictly aligned with parameter size or general model capabilities. The data and code are available at the project homepage: https://ck-arena.site.
RefRef: A Synthetic Dataset and Benchmark for Reconstructing Refractive and Reflective Objects
May 09, 2025Modern 3D reconstruction and novel view synthesis approaches have demonstrated strong performance on scenes with opaque Lambertian objects. However, most assume straight light paths and therefore cannot properly handle refractive and reflective materials. Moreover, datasets specialized for these effects are limited, stymieing efforts to evaluate performance and develop suitable techniques. In this work, we introduce a synthetic RefRef dataset and benchmark for reconstructing scenes with refractive and reflective objects from posed images. Our dataset has 50 such objects of varying complexity, from single-material convex shapes to multi-material non-convex shapes, each placed in three different background types, resulting in 150 scenes. We also propose an oracle method that, given the object geometry and refractive indices, calculates accurate light paths for neural rendering, and an approach based on this that avoids these assumptions. We benchmark these against several state-of-the-art methods and show that all methods lag significantly behind the oracle, highlighting the challenges of the task and dataset.
Can We Achieve Efficient Diffusion without Self-Attention? Distilling Self-Attention into Convolutions
Apr 30, 2025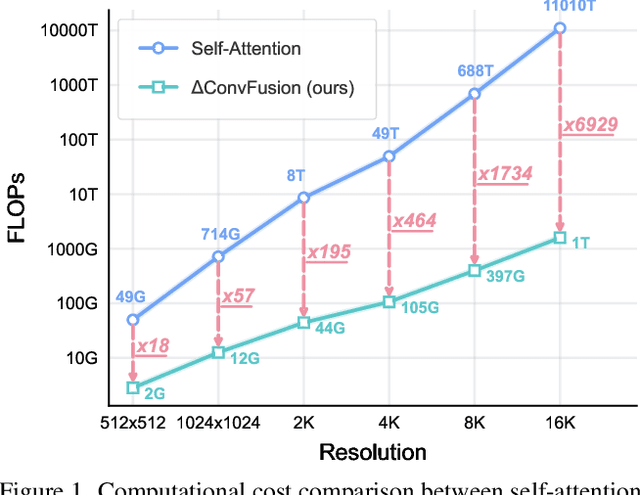
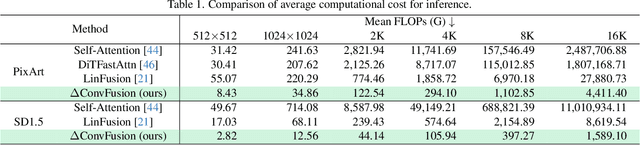

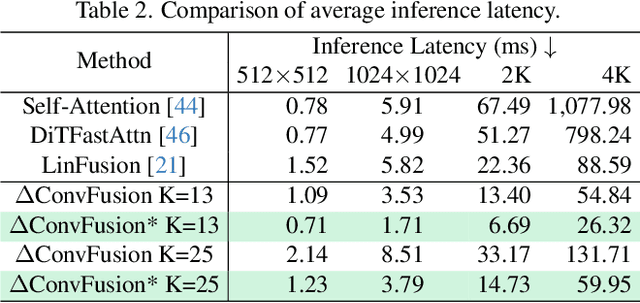
Contemporary diffusion models built upon U-Net or Diffusion Transformer (DiT) architectures have revolutionized image generation through transformer-based attention mechanisms. The prevailing paradigm has commonly employed self-attention with quadratic computational complexity to handle global spatial relationships in complex images, thereby synthesizing high-fidelity images with coherent visual semantics.Contrary to conventional wisdom, our systematic layer-wise analysis reveals an interesting discrepancy: self-attention in pre-trained diffusion models predominantly exhibits localized attention patterns, closely resembling convolutional inductive biases. This suggests that global interactions in self-attention may be less critical than commonly assumed.Driven by this, we propose \(\Delta\)ConvFusion to replace conventional self-attention modules with Pyramid Convolution Blocks (\(\Delta\)ConvBlocks).By distilling attention patterns into localized convolutional operations while keeping other components frozen, \(\Delta\)ConvFusion achieves performance comparable to transformer-based counterparts while reducing computational cost by 6929$\times$ and surpassing LinFusion by 5.42$\times$ in efficiency--all without compromising generative fidelity.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Ranked from Within: Ranking Large Multimodal Models for Visual Question Answering Without Labels
Dec 09, 2024



As large multimodal models (LMMs) are increasingly deployed across diverse applications, the need for adaptable, real-world model ranking has become paramount. Traditional evaluation methods are largely dataset-centric, relying on fixed, labeled datasets and supervised metrics, which are resource-intensive and may lack generalizability to novel scenarios, highlighting the importance of unsupervised ranking. In this work, we explore unsupervised model ranking for LMMs by leveraging their uncertainty signals, such as softmax probabilities. We evaluate state-of-the-art LMMs (e.g., LLaVA) across visual question answering benchmarks, analyzing how uncertainty-based metrics can reflect model performance. Our findings show that uncertainty scores derived from softmax distributions provide a robust, consistent basis for ranking models across varied tasks. This finding enables the ranking of LMMs on real-world, unlabeled data for visual question answering, providing a practical approach for selecting models across diverse domains without requiring manual annotation.
Manual-PA: Learning 3D Part Assembly from Instruction Diagrams
Nov 27, 2024



Assembling furniture amounts to solving the discrete-continuous optimization task of selecting the furniture parts to assemble and estimating their connecting poses in a physically realistic manner. The problem is hampered by its combinatorially large yet sparse solution space thus making learning to assemble a challenging task for current machine learning models. In this paper, we attempt to solve this task by leveraging the assembly instructions provided in diagrammatic manuals that typically accompany the furniture parts. Our key insight is to use the cues in these diagrams to split the problem into discrete and continuous phases. Specifically, we present Manual-PA, a transformer-based instruction Manual-guided 3D Part Assembly framework that learns to semantically align 3D parts with their illustrations in the manuals using a contrastive learning backbone towards predicting the assembly order and infers the 6D pose of each part via relating it to the final furniture depicted in the manual. To validate the efficacy of our method, we conduct experiments on the benchmark PartNet dataset. Our results show that using the diagrams and the order of the parts lead to significant improvements in assembly performance against the state of the art. Further, Manual-PA demonstrates strong generalization to real-world IKEA furniture assembly on the IKEA-Manual dataset.
Toward a Holistic Evaluation of Robustness in CLIP Models
Oct 02, 2024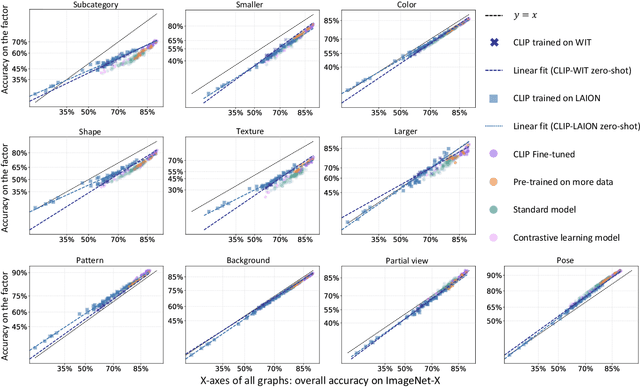
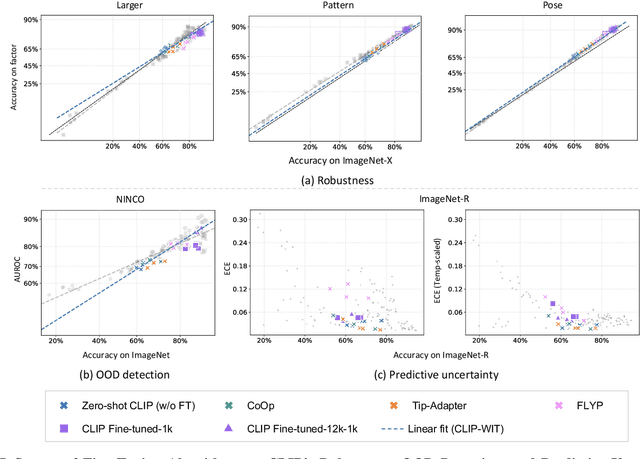


Contrastive Language-Image Pre-training (CLIP) models have shown significant potential, particularly in zero-shot classification across diverse distribution shifts. Building on existing evaluations of overall classification robustness, this work aims to provide a more comprehensive assessment of CLIP by introducing several new perspectives. First, we investigate their robustness to variations in specific visual factors. Second, we assess two critical safety objectives--confidence uncertainty and out-of-distribution detection--beyond mere classification accuracy. Third, we evaluate the finesse with which CLIP models bridge the image and text modalities. Fourth, we extend our examination to 3D awareness in CLIP models, moving beyond traditional 2D image understanding. Finally, we explore the interaction between vision and language encoders within modern large multimodal models (LMMs) that utilize CLIP as the visual backbone, focusing on how this interaction impacts classification robustness. In each aspect, we consider the impact of six factors on CLIP models: model architecture, training distribution, training set size, fine-tuning, contrastive loss, and test-time prompts. Our study uncovers several previously unknown insights into CLIP. For instance, the architecture of the visual encoder in CLIP plays a significant role in their robustness against 3D corruption. CLIP models tend to exhibit a bias towards shape when making predictions. Moreover, this bias tends to diminish after fine-tuning on ImageNet. Vision-language models like LLaVA, leveraging the CLIP vision encoder, could exhibit benefits in classification performance for challenging categories over CLIP alone. Our findings are poised to offer valuable guidance for enhancing the robustness and reliability of CLIP models.
What Does Softmax Probability Tell Us about Classifiers Ranking Across Diverse Test Conditions?
Jun 14, 2024

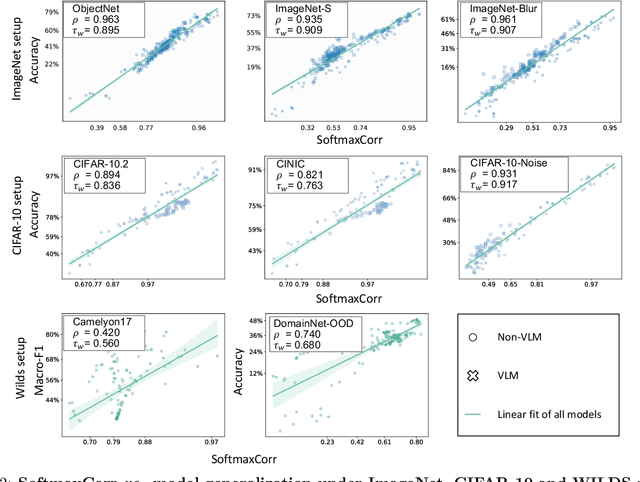
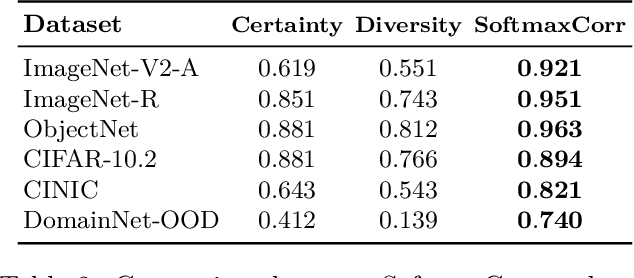
This work aims to develop a measure that can accurately rank the performance of various classifiers when they are tested on unlabeled data from out-of-distribution (OOD) distributions. We commence by demonstrating that conventional uncertainty metrics, notably the maximum Softmax prediction probability, possess inherent utility in forecasting model generalization across certain OOD contexts. Building on this insight, we introduce a new measure called Softmax Correlation (SoftmaxCorr). It calculates the cosine similarity between a class-class correlation matrix, constructed from Softmax output vectors across an unlabeled test dataset, and a predefined reference matrix that embodies ideal class correlations. A high resemblance of predictions to the reference matrix signals that the model delivers confident and uniform predictions across all categories, reflecting minimal uncertainty and confusion. Through rigorous evaluation across a suite of datasets, including ImageNet, CIFAR-10, and WILDS, we affirm the predictive validity of SoftmaxCorr in accurately forecasting model performance within both in-distribution (ID) and OOD settings. Furthermore, we discuss the limitations of our proposed measure and suggest avenues for future research.
MANO: Exploiting Matrix Norm for Unsupervised Accuracy Estimation Under Distribution Shifts
May 29, 2024



Leveraging the models' outputs, specifically the logits, is a common approach to estimating the test accuracy of a pre-trained neural network on out-of-distribution (OOD) samples without requiring access to the corresponding ground truth labels. Despite their ease of implementation and computational efficiency, current logit-based methods are vulnerable to overconfidence issues, leading to prediction bias, especially under the natural shift. In this work, we first study the relationship between logits and generalization performance from the view of low-density separation assumption. Our findings motivate our proposed method MaNo which (1) applies a data-dependent normalization on the logits to reduce prediction bias, and (2) takes the $L_p$ norm of the matrix of normalized logits as the estimation score. Our theoretical analysis highlights the connection between the provided score and the model's uncertainty. We conduct an extensive empirical study on common unsupervised accuracy estimation benchmarks and demonstrate that MaNo achieves state-of-the-art performance across various architectures in the presence of synthetic, natural, or subpopulation shifts.