 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANO: Exploiting Matrix Norm for Unsupervised Accuracy Estimation Under Distribution Shifts
May 29, 2024



Leveraging the models' outputs, specifically the logits, is a common approach to estimating the test accuracy of a pre-trained neural network on out-of-distribution (OOD) samples without requiring access to the corresponding ground truth labels. Despite their ease of implementation and computational efficiency, current logit-based methods are vulnerable to overconfidence issues, leading to prediction bias, especially under the natural shift. In this work, we first study the relationship between logits and generalization performance from the view of low-density separation assumption. Our findings motivate our proposed method MaNo which (1) applies a data-dependent normalization on the logits to reduce prediction bias, and (2) takes the $L_p$ norm of the matrix of normalized logits as the estimation score. Our theoretical analysis highlights the connection between the provided score and the model's uncertainty. We conduct an extensive empirical study on common unsupervised accuracy estimation benchmarks and demonstrate that MaNo achieves state-of-the-art performance across various architectures in the presence of synthetic, natural, or subpopulation shifts.
Characterising Gradients for Unsupervised Accuracy Estimation under Distribution Shift
Jan 17, 2024



Estimating test accuracy without access to the ground-truth test labels under varying test environments is a challenging, yet extremely important problem in the safe deployment of machine learning algorithms. Existing works rely on the information from either the outputs or the extracted features of neural networks to formulate an estimation score correlating with the ground-truth test accuracy. In this paper, we investigate--both empirically and theoretically--how the information provided by the gradients can be predictive of the ground-truth test accuracy even under a distribution shift. Specifically, we use the norm of classification-layer gradients, backpropagated from the cross-entropy loss after only one gradient step over test data. Our key idea is that the model should be adjusted with a higher magnitude of gradients when it does not generalize to the test dataset with a distribution shift. We provide theoretical insights highlighting the main ingredients of such an approach ensuring its empirical success. Extensive experiments conducted on diverse distribution shifts and model structures demonstrate that our method significantly outperforms state-of-the-art algorithms.
On the Importance of Feature Separability in Predicting Out-Of-Distribution Error
Mar 27, 2023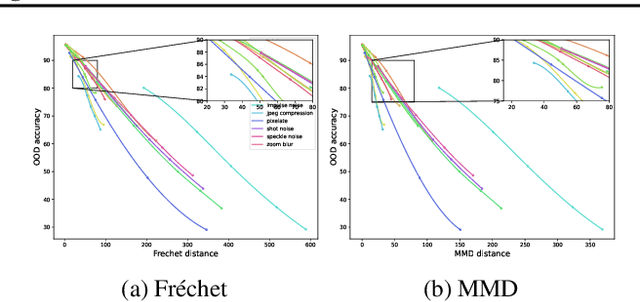


Estimating the generalization performance is practically challenging on out-of-distribution (OOD) data without ground truth labels. While previous methods emphasize the connection between distribution difference and OOD accuracy, we show that a large domain gap not necessarily leads to a low test accuracy. In this paper, we investigate this problem from the perspective of feature separability, and propose a dataset-level score based upon feature dispersion to estimate the test accuracy under distribution shift. Our method is inspired by desirable properties of features in representation learning: high inter-class dispersion and high intra-class compactness. Our analysis shows that inter-class dispersion is strongly correlated with the model accuracy, while intra-class compactness does not reflect the generalization performance on OOD data. Extensive experiments demonstrate the superiority of our method in both prediction performance and computational efficiency.
Logit Clipping for Robust Learning against Label Noise
Dec 08, 2022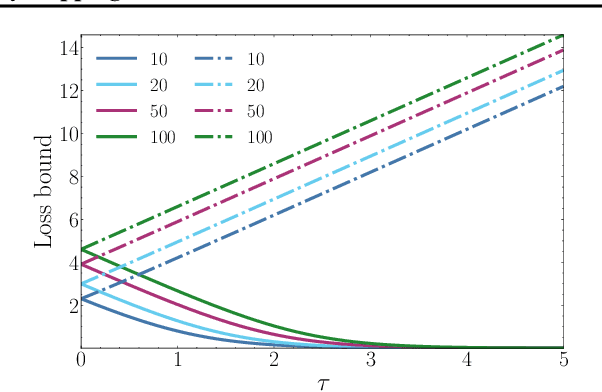

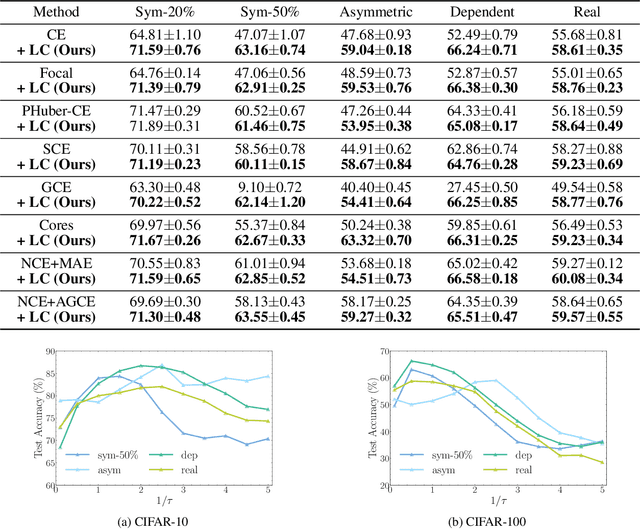

In the presence of noisy labels, designing robust loss functions is critical for securing the generalization performance of deep neural networks. Cross Entropy (CE) loss has been shown to be not robust to noisy labels due to its unboundedness. To alleviate this issue, existing works typically design specialized robust losses with the symmetric condition, which usually lead to the underfitting issue. In this paper, our key idea is to induce a loss bound at the logit level, thus universally enhancing the noise robustness of existing losses. Specifically, we propose logit clipping (LogitClip), which clamps the norm of the logit vector to ensure that it is upper bounded by a constant. In this manner, CE loss equipped with our LogitClip method is effectively bounded, mitigating the overfitting to examples with noisy labels. Moreover, we present theoretical analyses to certify the noise-tolerant ability of LogitClip. Extensive experiments show that LogitClip not only significantly improves the noise robustness of CE loss, but also broadly enhances the generalization performance of popular robust losses.
Open-Sampling: Exploring Out-of-Distribution data for Re-balancing Long-tailed datasets
Jun 24, 2022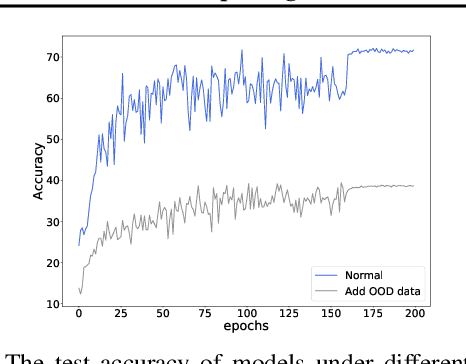
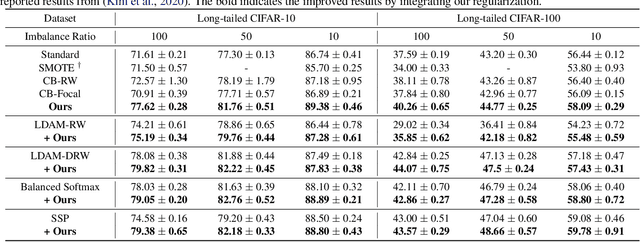
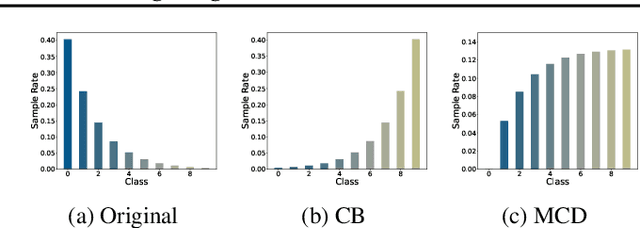
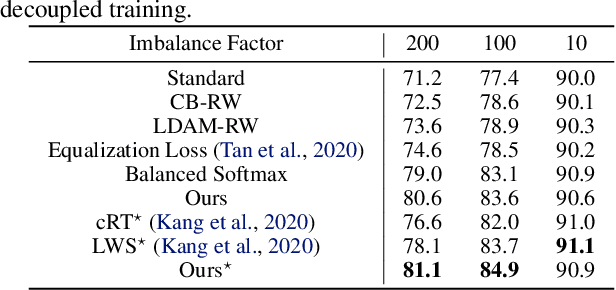
Deep neural networks usually perform poorly when the training dataset suffers from extreme class imbalance. Recent studies found that directly training with out-of-distribution data (i.e., open-set samples) in a semi-supervised manner would harm the generalization performance. In this work, we theoretically show that out-of-distribution data can still be leveraged to augment the minority classes from a Bayesian perspective. Based on this motivation, we propose a novel method called Open-sampling, which utilizes open-set noisy labels to re-balance the class priors of the training dataset. For each open-set instance, the label is sampled from our pre-defined distribution that is complementary to the distribution of original class priors. We empirically show that Open-sampling not only re-balances the class priors but also encourages the neural network to learn separable representations. Extensive experiments demonstrate that our proposed method significantly outperforms existing data re-balancing methods and can boost the performance of existing state-of-the-art methods.
ACIL: Analytic Class-Incremental Learning with Absolute Memorization and Privacy Protection
May 30, 2022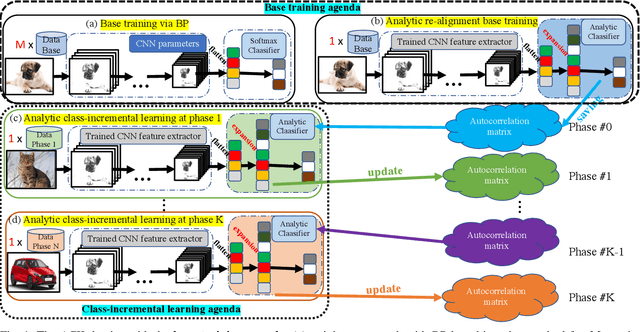
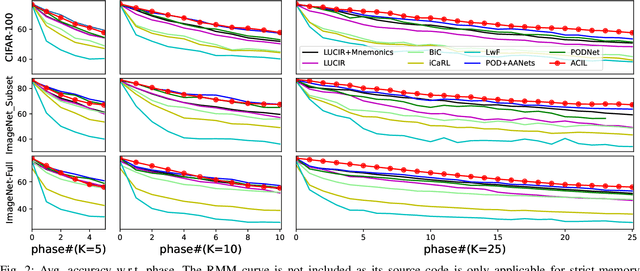
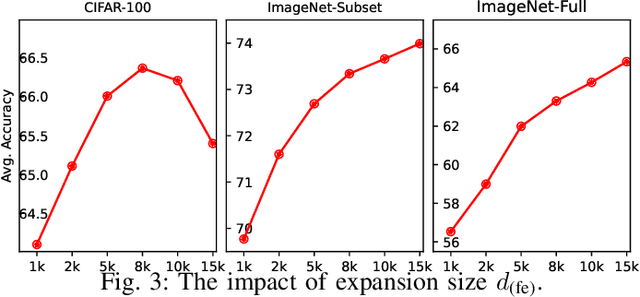
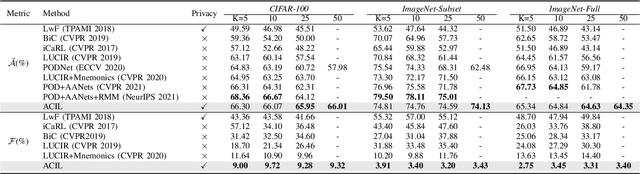
Class-incremental learning (CIL) learns a classification model with training data of different classes arising progressively. Existing CIL either suffers from serious accuracy loss due to catastrophic forgetting, or invades data privacy by revisiting used exemplars. Inspired by linear learning formulations, we propose an analytic class-incremental learning (ACIL) with absolute memorization of past knowledge while avoiding breaching of data privacy (i.e., without storing historical data). The absolute memorization is demonstrated in the sense that class-incremental learning using ACIL given present data would give identical results to that from its joint-learning counterpart which consumes both present and historical samples. This equality is theoretically validated. Data privacy is ensured since no historical data are involved during the learning process. Empirical validations demonstrate ACIL's competitive accuracy performance with near-identical results for various incremental task settings (e.g., 5-50 phases). This also allows ACIL to outperform the state-of-the-art methods for large-phase scenarios (e.g., 25 and 50 phases).
Mitigating Neural Network Overconfidence with Logit Normalization
May 19, 2022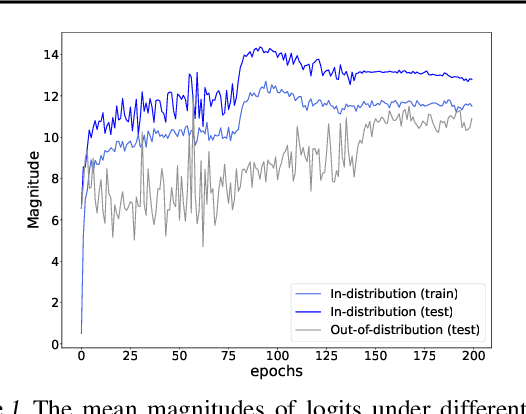
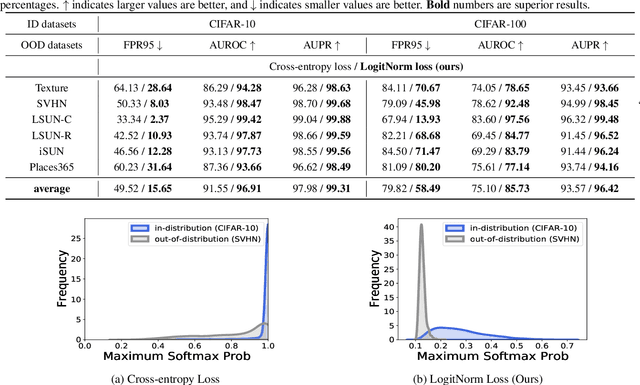
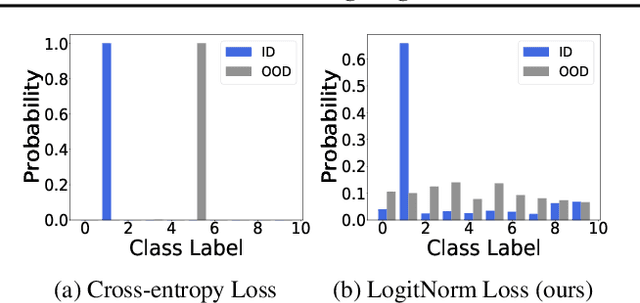
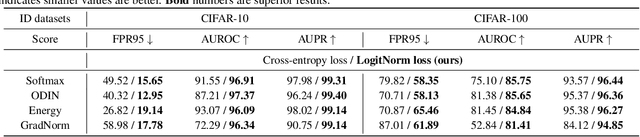
Detecting out-of-distribution inputs is critical for safe deployment of machine learning models in the real world. However, neural networks are known to suffer from the overconfidence issue, where they produce abnormally high confidence for both in- and out-of-distribution inputs. In this work, we show that this issue can be mitigated through Logit Normalization (LogitNorm) -- a simple fix to the cross-entropy loss -- by enforcing a constant vector norm on the logits in training. Our method is motivated by the analysis that the norm of the logit keeps increasing during training, leading to overconfident output. Our key idea behind LogitNorm is thus to decouple the influence of output's norm during network optimization. Trained with LogitNorm, neural networks produce highly distinguishable confidence scores between in- and out-of-distribution data. Extensive experiments demonstrate the superiority of LogitNorm, reducing the average FPR95 by up to 42.30% on common benchmarks.
GearNet: Stepwise Dual Learning for Weakly Supervised Domain Adaptation
Jan 25, 2022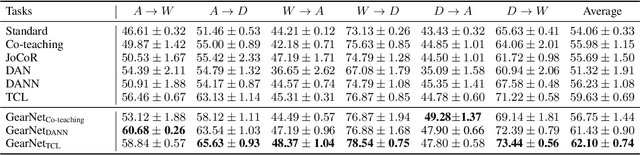
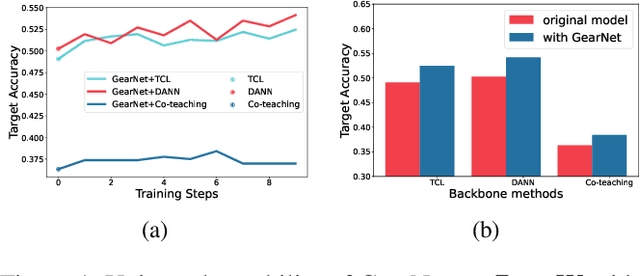
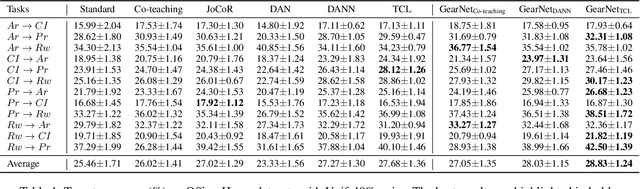

This paper studies weakly supervised domain adaptation(WSDA) problem, where we only have access to the source domain with noisy labels, from which we need to transfer useful information to the unlabeled target domain. Although there have been a few studies on this problem, most of them only exploit unidirectional relationships from the source domain to the target domain. In this paper, we propose a universal paradigm called GearNet to exploit bilateral relationships between the two domains. Specifically, we take the two domains as different inputs to train two models alternately, and asymmetrical Kullback-Leibler loss is used for selectively matching the predictions of the two models in the same domain. This interactive learning schema enables implicit label noise canceling and exploits correlations between the source and target domains. Therefore, our GearNet has the great potential to boost the performance of a wide range of existing WSDL methods. Comprehensive experimental results show that the performance of existing methods can be significantly improved by equipping with our GearNet.
Automatic Online Multi-Source Domain Adaptation
Sep 12, 2021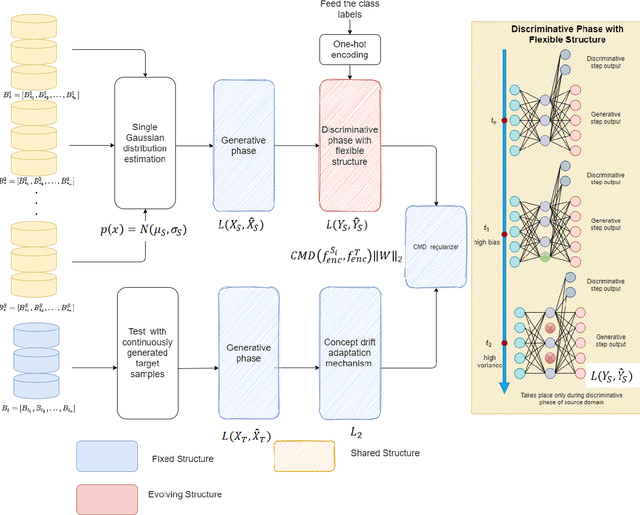
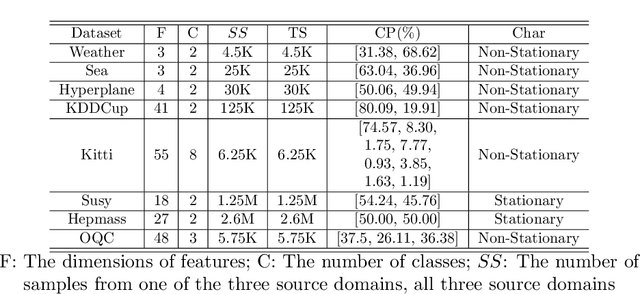
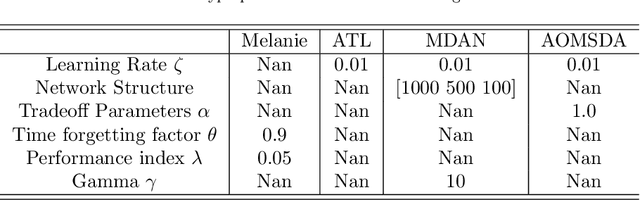
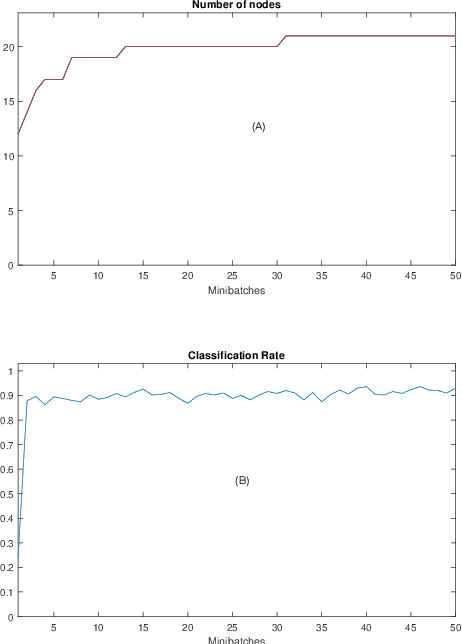
Knowledge transfer across several streaming processes remain challenging problem not only because of different distributions of each stream but also because of rapidly changing and never-ending environments of data streams. Albeit growing research achievements in this area, most of existing works are developed for a single source domain which limits its resilience to exploit multi-source domains being beneficial to recover from concept drifts quickly and to avoid the negative transfer problem. An online domain adaptation technique under multisource streaming processes, namely automatic online multi-source domain adaptation (AOMSDA), is proposed in this paper. The online domain adaptation strategy of AOMSDA is formulated under a coupled generative and discriminative approach of denoising autoencoder (DAE) where the central moment discrepancy (CMD)-based regularizer is integrated to handle the existence of multi-source domains thereby taking advantage of complementary information sources. The asynchronous concept drifts taking place at different time periods are addressed by a self-organizing structure and a node re-weighting strategy. Our numerical study demonstrates that AOMSDA is capable of outperforming its counterparts in 5 of 8 study cases while the ablation study depicts the advantage of each learning component. In addition, AOMSDA is general for any number of source streams. The source code of AOMSDA is shared publicly in https://github.com/Renchunzi-Xie/AOMSDA.git.
Open-set Label Noise Can Improve Robustness Against Inherent Label Noise
Jun 21, 2021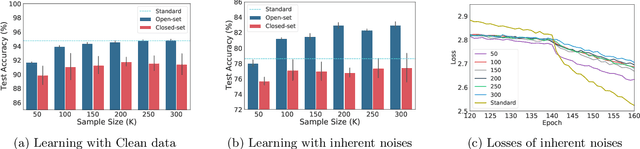
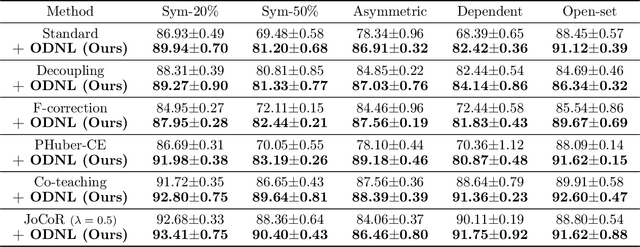
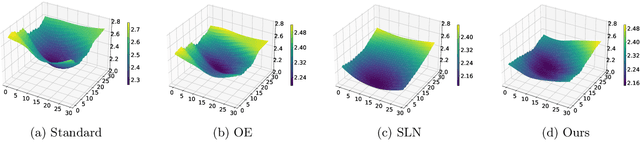
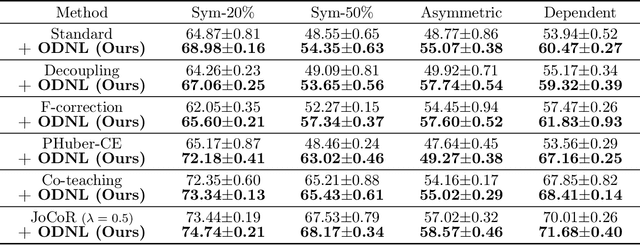
Learning with noisy labels is a practically challenging problem in weakly supervised learning. In the existing literature, open-set noises are always considered to be poisonous for generalization, similar to closed-set noises. In this paper, we empirically show that open-set noisy labels can be non-toxic and even benefit the robustness against inherent noisy labels. Inspired by the observations, we propose a simple yet effective regularization by introducing Open-set samples with Dynamic Noisy Labels (ODNL) into training. With ODNL, the extra capacity of the neural network can be largely consumed in a way that does not interfere with learning patterns from clean data. Through the lens of SGD noise, we show that the noises induced by our method are random-direction, conflict-free and biased, which may help the model converge to a flat minimum with superior stability and enforce the model to produce conservative predictions on Out-of-Distribution instances. Extensive experimental results on benchmark datasets with various types of noisy labels demonstrate that the proposed method not only enhances the performance of many existing robust algorithms but also achieves significant improvement on Out-of-Distribution detection tasks even in the label noise setting.