 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer by layer, module by module: Choose both for optimal OOD probing of ViT
Mar 05, 2026Recent studies have observed that intermediate layers of foundation models often yield more discriminative representations than the final layer. While initially attributed to autoregressive pretraining, this phenomenon has also been identified in models trained via supervised and discriminative self-supervised objectives. In this paper, we conduct a comprehensive study to analyze the behavior of intermediate layers in pretrained vision transformers. Through extensive linear probing experiments across a diverse set of image classification benchmarks, we find that distribution shift between pretraining and downstream data is the primary cause of performance degradation in deeper layers. Furthermore, we perform a fine-grained analysis at the module level. Our findings reveal that standard probing of transformer block outputs is suboptimal; instead, probing the activation within the feedforward network yields the best performance under significant distribution shift, whereas the normalized output of the multi-head self-attention module is optimal when the shift is weak.
UTICA: Multi-Objective Self-Distllation Foundation Model Pretraining for Time Series Classification
Mar 02, 2026Self-supervised foundation models have achieved remarkable success across domains, including time series. However, the potential of non-contrastive methods, a paradigm that has driven significant advances in computer vision, remains underexplored for time series. In this work, we adapt DINOv2-style self-distillation to pretrain a time series foundation model, building on the Mantis tokenizer and transformer encoder architecture as our backbone. Through a student-teacher framework, our method Utica learns representations that capture both temporal invariance via augmented crops and fine-grained local structure via patch masking. Our approach achieves state-of-the-art classification performance on both UCR and UEA benchmarks. These results suggest that non-contrastive methods are a promising and complementary pretraining strategy for time series foundation models.
Leveraging Generic Time Series Foundation Models for EEG Classification
Oct 31, 2025Foundation models for time series are emerging as powerful general-purpose backbones, yet their potential for domain-specific biomedical signals such as electroencephalography (EEG) remains rather unexplored. In this work, we investigate the applicability a recently proposed time series classification foundation model, to a different EEG tasks such as motor imagery classification and sleep stage prediction. We test two pretraining regimes: (a) pretraining on heterogeneous real-world time series from multiple domains, and (b) pretraining on purely synthetic data. We find that both variants yield strong performance, consistently outperforming EEGNet, a widely used convolutional baseline, and CBraMod, the most recent EEG-specific foundation model. These results suggest that generalist time series foundation models, even when pretrained on data of non-neural origin or on synthetic signals, can transfer effectively to EEG. Our findings highlight the promise of leveraging cross-domain pretrained models for brain signal analysis, suggesting that EEG may benefit from advances in the broader time series literature.
Time Series Representations for Classification Lie Hidden in Pretrained Vision Transformers
Jun 10, 2025Time series classification is a fundamental task in healthcare and industry, yet the development of time series foundation models (TSFMs) remains limited by the scarcity of publicly available time series datasets. In this work, we propose Time Vision Transformer (TiViT), a framework that converts time series into images to leverage the representational power of frozen Vision Transformers (ViTs) pretrained on large-scale image datasets. First, we theoretically motivate our approach by analyzing the 2D patching of ViTs for time series, showing that it can increase the number of label-relevant tokens and reduce the sample complexity. Second, we empirically demonstrate that TiViT achieves state-of-the-art performance on standard time series classification benchmarks by utilizing the hidden representations of large OpenCLIP models. We explore the structure of TiViT representations and find that intermediate layers with high intrinsic dimension are the most effective for time series classification. Finally, we assess the alignment between TiViT and TSFM representation spaces and identify a strong complementarity, with further performance gains achieved by combining their features. Our findings reveal yet another direction for reusing vision representations in a non-visual domain.
Mantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification
Feb 21, 2025In recent years, there has been increasing interest in developing foundation models for time series data that can generalize across diverse downstream tasks. While numerous forecasting-oriented foundation models have been introduced, there is a notable scarcity of models tailored for time series classification. To address this gap, we present Mantis, a new open-source foundation model for time series classification based on the Vision Transformer (ViT) architecture that has been pre-trained using a contrastive learning approach. Our experimental results show that Mantis outperforms existing foundation models both when the backbone is frozen and when fine-tuned, while achieving the lowest calibration error. In addition, we propose several adapters to handle the multivariate setting, reducing memory requirements and modeling channel interdependence.
Measuring Pre-training Data Quality without Labels for Time Series Foundation Models
Dec 09, 2024Recently, there has been a growing interest in time series foundation models that generalize across different downstream tasks. A key to strong foundation models is a diverse pre-training dataset, which is particularly challenging to collect for time series classification. In this work, we explore the performance of a contrastive-learning-based foundation model as a function of the data used for pre-training. We introduce contrastive accuracy, a new measure to evaluate the quality of the representation space learned by the foundation model. Our experiments reveal the positive correlation between the proposed measure and the accuracy of the model on a collection of downstream tasks. This suggests that the contrastive accuracy can serve as a criterion to search for time series datasets that can enhance the pre-training and improve thereby the foundation model's generalization.
Analysing Multi-Task Regression via Random Matrix Theory with Application to Time Series Forecasting
Jun 14, 2024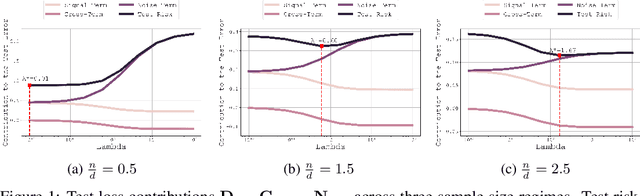
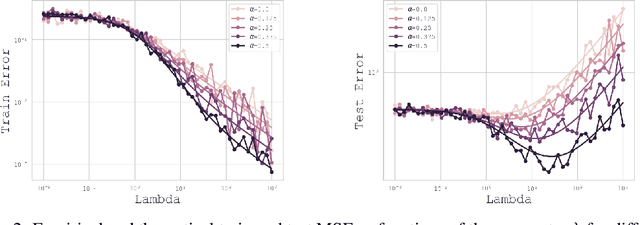
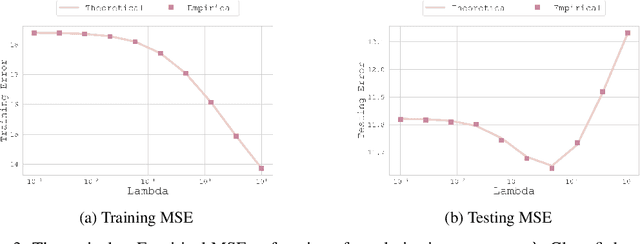
In this paper, we introduce a novel theoretical framework for multi-task regression, applying random matrix theory to provide precise performance estimations, under high-dimensional, non-Gaussian data distributions. We formulate a multi-task optimization problem as a regularization technique to enable single-task models to leverage multi-task learning information. We derive a closed-form solution for multi-task optimization in the context of linear models. Our analysis provides valuable insights by linking the multi-task learning performance to various model statistics such as raw data covariances, signal-generating hyperplanes, noise levels, as well as the size and number of datasets. We finally propose a consistent estimation of training and testing errors, thereby offering a robust foundation for hyperparameter optimization in multi-task regression scenarios. Experimental validations on both synthetic and real-world datasets in regression and multivariate time series forecasting demonstrate improvements on univariate models, incorporating our method into the training loss and thus leveraging multivariate information.
MANO: Exploiting Matrix Norm for Unsupervised Accuracy Estimation Under Distribution Shifts
May 29, 2024



Leveraging the models' outputs, specifically the logits, is a common approach to estimating the test accuracy of a pre-trained neural network on out-of-distribution (OOD) samples without requiring access to the corresponding ground truth labels. Despite their ease of implementation and computational efficiency, current logit-based methods are vulnerable to overconfidence issues, leading to prediction bias, especially under the natural shift. In this work, we first study the relationship between logits and generalization performance from the view of low-density separation assumption. Our findings motivate our proposed method MaNo which (1) applies a data-dependent normalization on the logits to reduce prediction bias, and (2) takes the $L_p$ norm of the matrix of normalized logits as the estimation score. Our theoretical analysis highlights the connection between the provided score and the model's uncertainty. We conduct an extensive empirical study on common unsupervised accuracy estimation benchmarks and demonstrate that MaNo achieves state-of-the-art performance across various architectures in the presence of synthetic, natural, or subpopulation shifts.
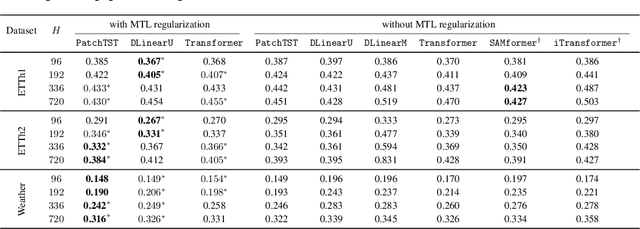
Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention
Feb 19, 2024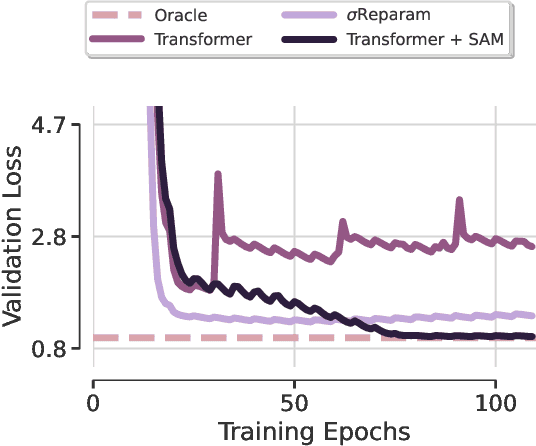
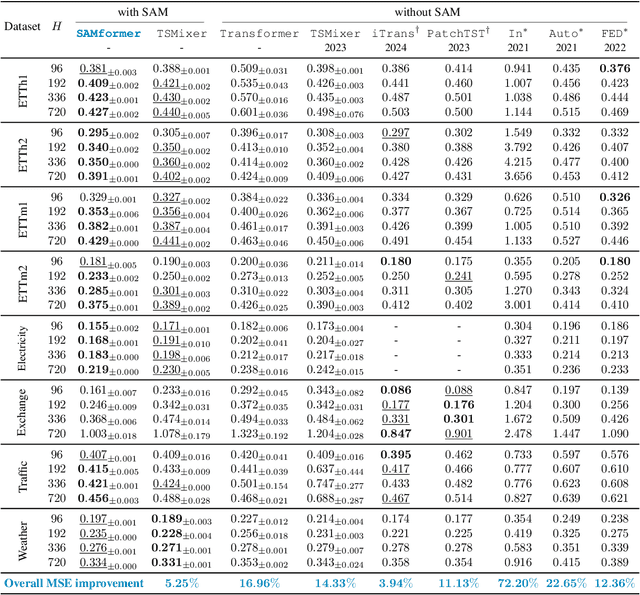
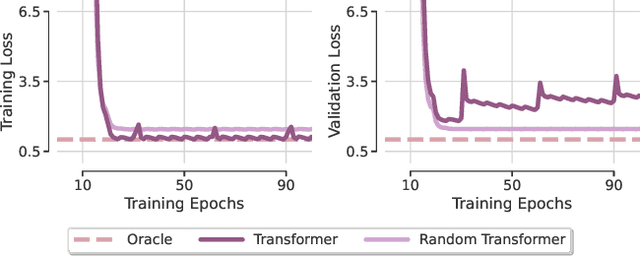
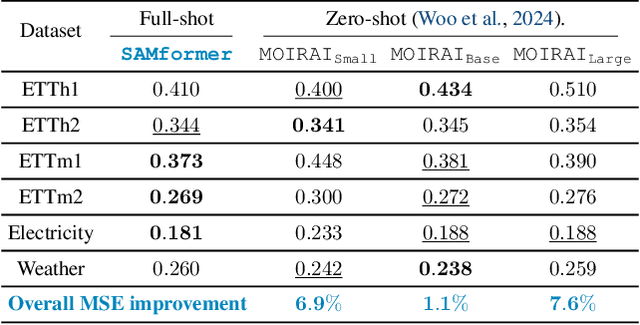
Transformer-based architectures achieved breakthrough performance in natural language processing and computer vision, yet they remain inferior to simpler linear baselines in multivariate long-term forecasting. To better understand this phenomenon, we start by studying a toy linear forecasting problem for which we show that transformers are incapable of converging to their true solution despite their high expressive power. We further identify the attention of transformers as being responsible for this low generalization capacity. Building upon this insight, we propose a shallow lightweight transformer model that successfully escapes bad local minima when optimized with sharpness-aware optimization. We empirically demonstrate that this result extends to all commonly used real-world multivariate time series datasets. In particular, SAMformer surpasses the current state-of-the-art model TSMixer by 14.33% on average, while having ~4 times fewer parameters. The code is available at https://github.com/romilbert/samformer.
Characterising Gradients for Unsupervised Accuracy Estimation under Distribution Shift
Jan 17, 2024



Estimating test accuracy without access to the ground-truth test labels under varying test environments is a challenging, yet extremely important problem in the safe deployment of machine learning algorithms. Existing works rely on the information from either the outputs or the extracted features of neural networks to formulate an estimation score correlating with the ground-truth test accuracy. In this paper, we investigate--both empirically and theoretically--how the information provided by the gradients can be predictive of the ground-truth test accuracy even under a distribution shift. Specifically, we use the norm of classification-layer gradients, backpropagated from the cross-entropy loss after only one gradient step over test data. Our key idea is that the model should be adjusted with a higher magnitude of gradients when it does not generalize to the test dataset with a distribution shift. We provide theoretical insights highlighting the main ingredients of such an approach ensuring its empirical success. Extensive experiments conducted on diverse distribution shifts and model structures demonstrate that our method significantly outperforms state-of-the-art algorithms.