 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifiability in Causal Abstractions: A Hierarchy of Criteria
Jul 08, 2025Identifying the effect of a treatment from observational data typically requires assuming a fully specified causal diagram. However, such diagrams are rarely known in practice, especially in complex or high-dimensional settings. To overcome this limitation, recent works have explored the use of causal abstractions-simplified representations that retain partial causal information. In this paper, we consider causal abstractions formalized as collections of causal diagrams, and focus on the identifiability of causal queries within such collections. We introduce and formalize several identifiability criteria under this setting. Our main contribution is to organize these criteria into a structured hierarchy, highlighting their relationships. This hierarchical view enables a clearer understanding of what can be identified under varying levels of causal knowledge. We illustrate our framework through examples from the literature and provide tools to reason about identifiability when full causal knowledge is unavailable.
Complete Characterization for Adjustment in Summary Causal Graphs of Time Series
Jun 17, 2025The identifiability problem for interventions aims at assessing whether the total causal effect can be written with a do-free formula, and thus be estimated from observational data only. We study this problem, considering multiple interventions, in the context of time series when only an abstraction of the true causal graph, in the form of a summary causal graph, is available. We propose in particular both necessary and sufficient conditions for the adjustment criterion, which we show is complete in this setting, and provide a pseudo-linear algorithm to decide whether the query is identifiable or not.
Identifiability by common backdoor in summary causal graphs of time series
Jun 17, 2025The identifiability problem for interventions aims at assessing whether the total effect of some given interventions can be written with a do-free formula, and thus be computed from observational data only. We study this problem, considering multiple interventions and multiple effects, in the context of time series when only abstractions of the true causal graph in the form of summary causal graphs are available. We focus in this study on identifiability by a common backdoor set, and establish, for time series with and without consistency throughout time, conditions under which such a set exists. We also provide algorithms of limited complexity to decide whether the problem is identifiable or not.
Ensembles of Probabilistic Regression Trees
Jun 20, 2024



Tree-based ensemble methods such as random forests, gradient-boosted trees, and Bayesianadditive regression trees have been successfully used for regression problems in many applicationsand research studies. In this paper, we study ensemble versions of probabilisticregression trees that provide smooth approximations of the objective function by assigningeach observation to each region with respect to a probability distribution. We prove thatthe ensemble versions of probabilistic regression trees considered are consistent, and experimentallystudy their bias-variance trade-off and compare them with the state-of-the-art interms of performance prediction.
Classification Tree-based Active Learning: A Wrapper Approach
Apr 15, 2024Supervised machine learning often requires large training sets to train accurate models, yet obtaining large amounts of labeled data is not always feasible. Hence, it becomes crucial to explore active learning methods for reducing the size of training sets while maintaining high accuracy. The aim is to select the optimal subset of data for labeling from an initial unlabeled set, ensuring precise prediction of outcomes. However, conventional active learning approaches are comparable to classical random sampling. This paper proposes a wrapper active learning method for classification, organizing the sampling process into a tree structure, that improves state-of-the-art algorithms. A classification tree constructed on an initial set of labeled samples is considered to decompose the space into low-entropy regions. Input-space based criteria are used thereafter to sub-sample from these regions, the total number of points to be labeled being decomposed into each region. This adaptation proves to be a significant enhancement over existing active learning methods. Through experiments conducted on various benchmark data sets, the paper demonstrates the efficacy of the proposed framework by being effective in constructing accurate classification models, even when provided with a severely restricted labeled data set.
On the Fly Detection of Root Causes from Observed Data with Application to IT Systems
Feb 09, 2024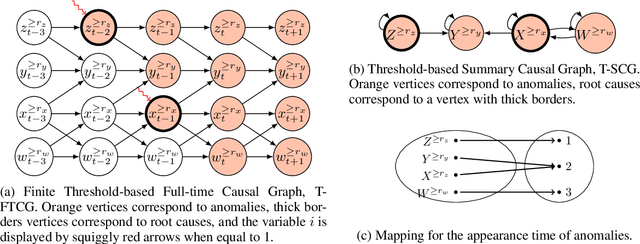
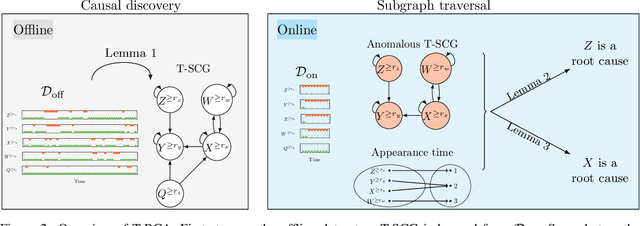
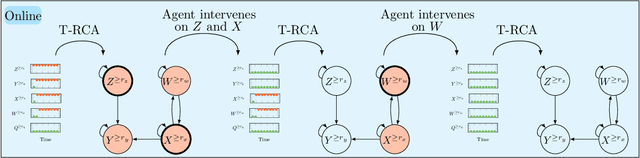
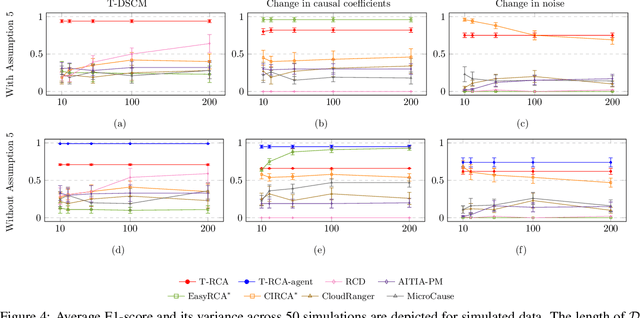
This paper introduces a new structural causal model tailored for representing threshold-based IT systems and presents a new algorithm designed to rapidly detect root causes of anomalies in such systems. When root causes are not causally related, the method is proven to be correct; while an extension is proposed based on the intervention of an agent to relax this assumption. Our algorithm and its agent-based extension leverage causal discovery from offline data and engage in subgraph traversal when encountering new anomalies in online data. Our extensive experiments demonstrate the superior performance of our methods, even when applied to data generated from alternative structural causal models or real IT monitoring data.
Identifiability of total effects from abstractions of time series causal graphs
Nov 02, 2023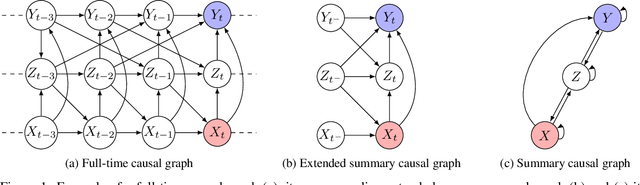
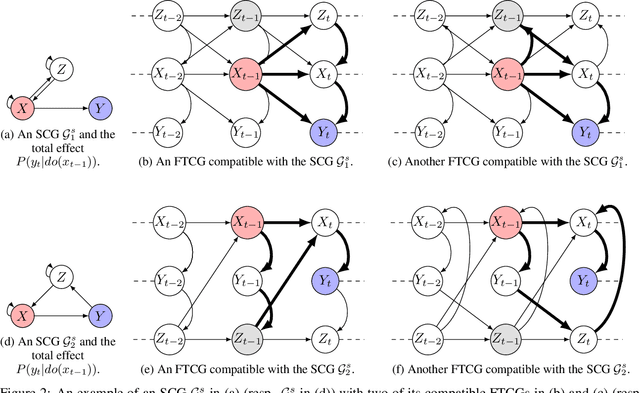
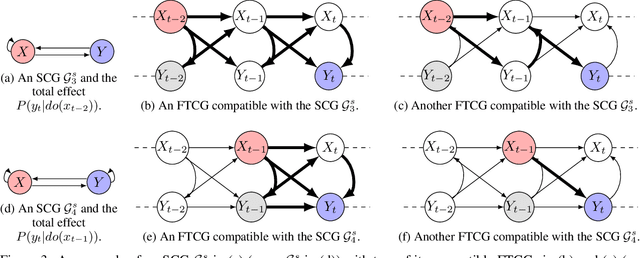

We study the problem of identifiability of the total effect of an intervention from observational time series only given an abstraction of the causal graph of the system. Specifically, we consider two types of abstractions: the extended summary causal graph which conflates all lagged causal relations but distinguishes between lagged and instantaneous relations; and the summary causal graph which does not give any indication about the lag between causal relations. We show that the total effect is always identifiable in extended summary causal graphs and we provide necessary and sufficient graphical conditions for identifiability in summary causal graphs. Furthermore, we provide adjustment sets allowing to estimate the total effect whenever it is identifiable.
Pool-Based Active Learning with Proper Topological Regions
Oct 02, 2023Machine learning methods usually rely on large sample size to have good performance, while it is difficult to provide labeled set in many applications. Pool-based active learning methods are there to detect, among a set of unlabeled data, the ones that are the most relevant for the training. We propose in this paper a meta-approach for pool-based active learning strategies in the context of multi-class classification tasks based on Proper Topological Regions. PTR, based on topological data analysis (TDA), are relevant regions used to sample cold-start points or within the active learning scheme. The proposed method is illustrated empirically on various benchmark datasets, being competitive to the classical methods from the literature.
Case Studies of Causal Discovery from IT Monitoring Time Series
Jul 28, 2023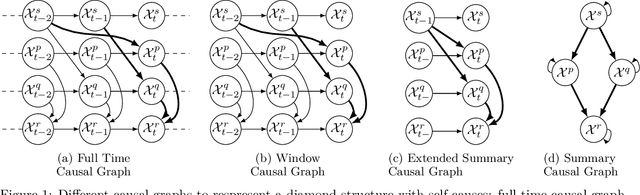
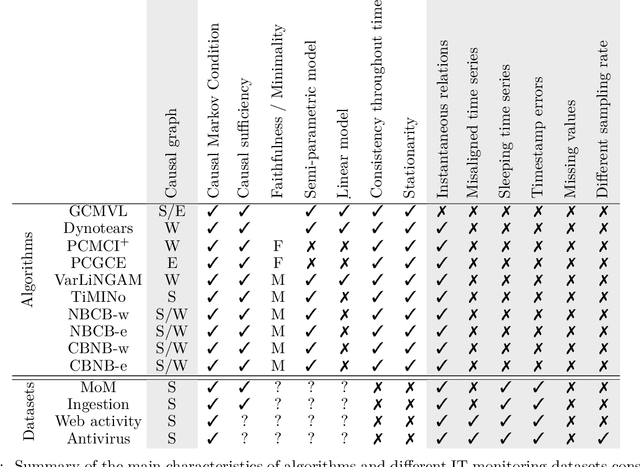
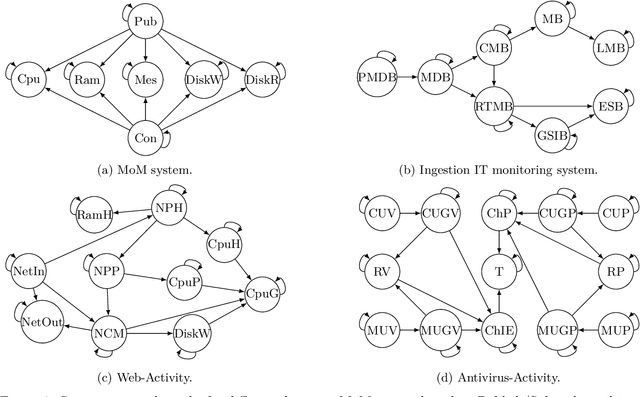
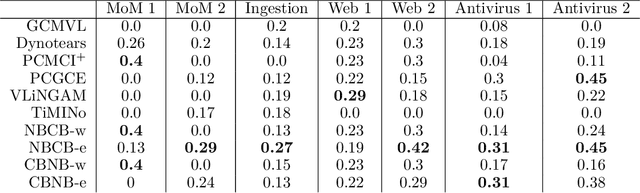
Information technology (IT) systems are vital for modern businesses, handling data storage, communication, and process automation. Monitoring these systems is crucial for their proper functioning and efficiency, as it allows collecting extensive observational time series data for analysis. The interest in causal discovery is growing in IT monitoring systems as knowing causal relations between different components of the IT system helps in reducing downtime, enhancing system performance and identifying root causes of anomalies and incidents. It also allows proactive prediction of future issues through historical data analysis. Despite its potential benefits, applying causal discovery algorithms on IT monitoring data poses challenges, due to the complexity of the data. For instance, IT monitoring data often contains misaligned time series, sleeping time series, timestamp errors and missing values. This paper presents case studies on applying causal discovery algorithms to different IT monitoring datasets, highlighting benefits and ongoing challenges.
Hybrids of Constraint-based and Noise-based Algorithms for Causal Discovery from Time Series
Jun 14, 2023



Constraint-based and noise-based methods have been proposed to discover summary causal graphs from observational time series under strong assumptions which can be violated or impossible to verify in real applications. Recently, a hybrid method (Assaad et al, 2021) that combines these two approaches, proved to be robust to assumption violation. However, this method assumes that the summary causal graph is acyclic, but cycles are common in many applications. For example, in ecological communities, there may be cyclic relationships between predator and prey populations, creating feedback loops. Therefore, this paper presents two new frameworks for hybrids of constraint-based and noise-based methods that can discover summary causal graphs that may or may not contain cycles. For each framework, we provide two hybrid algorithms which are experimentally tested on simulated data, realistic ecological data, and real data from various applications. Experiments show that our hybrid approaches are robust and yield good results over most datasets.