 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Intrinsic Dimension of Texts: from Academic Abstract to Creative Story
Nov 19, 2025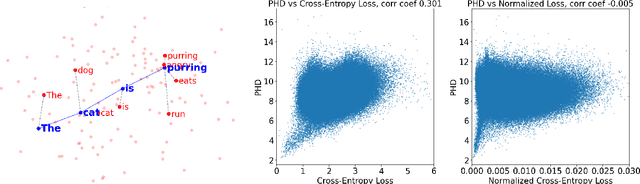
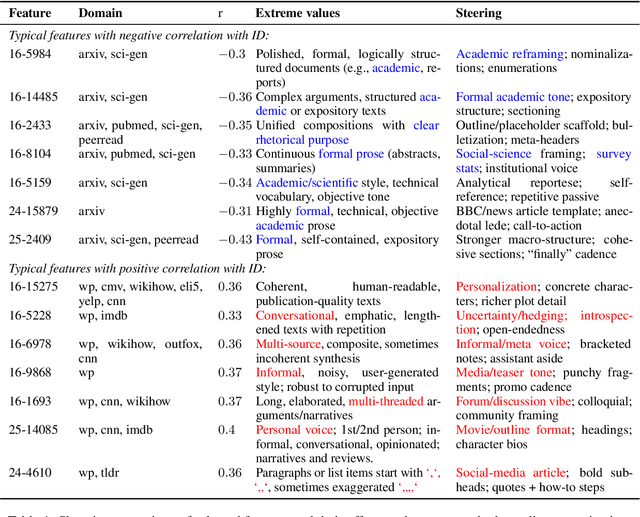
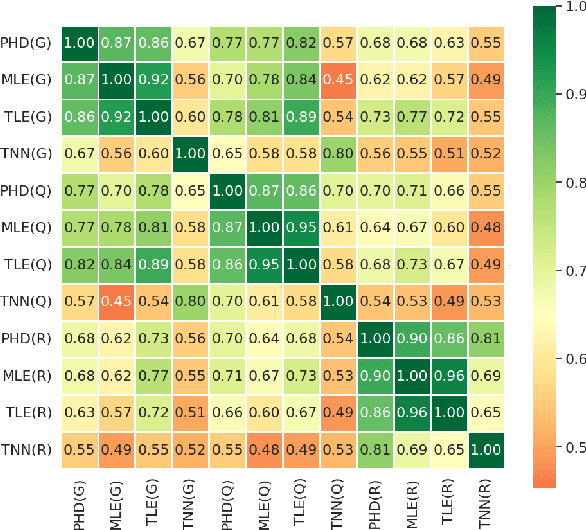

Intrinsic dimension (ID) is an important tool in modern LLM analysis, informing studies of training dynamics, scaling behavior, and dataset structure, yet its textual determinants remain underexplored. We provide the first comprehensive study grounding ID in interpretable text properties through cross-encoder analysis, linguistic features, and sparse autoencoders (SAEs). In this work, we establish three key findings. First, ID is complementary to entropy-based metrics: after controlling for length, the two are uncorrelated, with ID capturing geometric complexity orthogonal to prediction quality. Second, ID exhibits robust genre stratification: scientific prose shows low ID (~8), encyclopedic content medium ID (~9), and creative/opinion writing high ID (~10.5) across all models tested. This reveals that contemporary LLMs find scientific text "representationally simple" while fiction requires additional degrees of freedom. Third, using SAEs, we identify causal features: scientific signals (formal tone, report templates, statistics) reduce ID; humanized signals (personalization, emotion, narrative) increase it. Steering experiments confirm these effects are causal. Thus, for contemporary models, scientific writing appears comparatively "easy", whereas fiction, opinion, and affect add representational degrees of freedom. Our multi-faceted analysis provides practical guidance for the proper use of ID and the sound interpretation of ID-based results.
Cascading Blackout Severity Prediction with Statistically-Augmented Graph Neural Networks
Mar 22, 2024

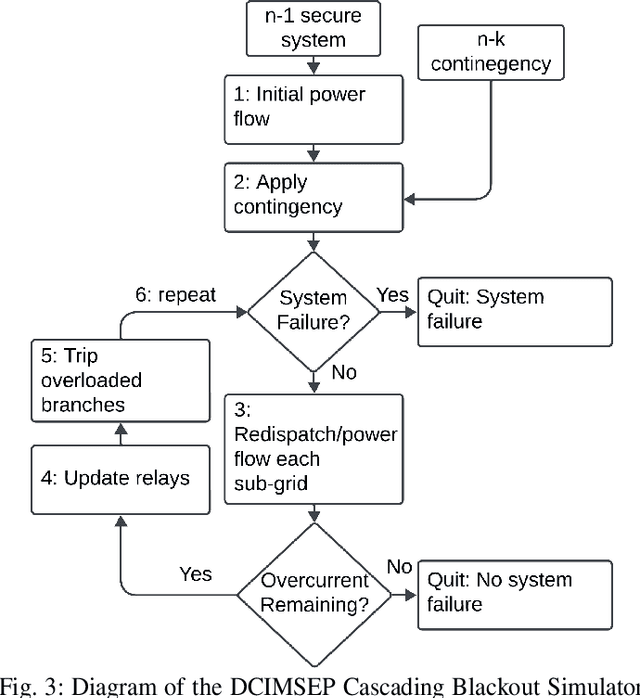

Higher variability in grid conditions, resulting from growing renewable penetration and increased incidence of extreme weather events, has increased the difficulty of screening for scenarios that may lead to catastrophic cascading failures. Traditional power-flow-based tools for assessing cascading blackout risk are too slow to properly explore the space of possible failures and load/generation patterns. We add to the growing literature of faster graph-neural-network (GNN)-based techniques, developing two novel techniques for the estimation of blackout magnitude from initial grid conditions. First we propose several methods for employing an initial classification step to filter out safe "non blackout" scenarios prior to magnitude estimation. Second, using insights from the statistical properties of cascading blackouts, we propose a method for facilitating non-local message passing in our GNN models. We validate these two approaches on a large simulated dataset, and show the potential of both to increase blackout size estimation performance.
Climate Change Impact on Agricultural Land Suitability: An Interpretable Machine Learning-Based Eurasia Case Study
Oct 24, 2023The United Nations has identified improving food security and reducing hunger as essential components of its sustainable development goals. As of 2021, approximately 828 million people worldwide are experiencing hunger and malnutrition, with numerous fatalities reported. Climate change significantly impacts agricultural land suitability, potentially leading to severe food shortages and subsequent social and political conflicts. To address this pressing issue, we have developed a machine learning-based approach to predict the risk of substantial land suitability degradation and changes in irrigation patterns. Our study focuses on Central Eurasia, a region burdened with economic and social challenges. This study represents a pioneering effort in utilizing machine learning methods to assess the impact of climate change on agricultural land suitability under various carbon emissions scenarios. Through comprehensive feature importance analysis, we unveil specific climate and terrain characteristics that exert influence on land suitability. Our approach achieves remarkable accuracy, offering policymakers invaluable insights to facilitate informed decisions aimed at averting a humanitarian crisis, including strategies such as the provision of additional water and fertilizers. This research underscores the tremendous potential of machine learning in addressing global challenges, with a particular emphasis on mitigating hunger and malnutrition.
CMIP X-MOS: Improving Climate Models with Extreme Model Output Statistics
Oct 24, 2023Climate models are essential for assessing the impact of greenhouse gas emissions on our changing climate and the resulting increase in the frequency and severity of natural disasters. Despite the widespread acceptance of climate models produced by the Coupled Model Intercomparison Project (CMIP), they still face challenges in accurately predicting climate extremes, which pose most significant threats to both people and the environment. To address this limitation and improve predictions of natural disaster risks, we introduce Extreme Model Output Statistics (X-MOS). This approach utilizes deep regression techniques to precisely map CMIP model outputs to real measurements obtained from weather stations, which results in a more accurate analysis of the XXI climate extremes. In contrast to previous research, our study places a strong emphasis on enhancing the estimation of the tails of future climate parameter distributions. The latter supports decision-makers, enabling them to better assess climate-related risks across the globe.
Long-term drought prediction using deep neural networks based on geospatial weather data
Sep 19, 2023
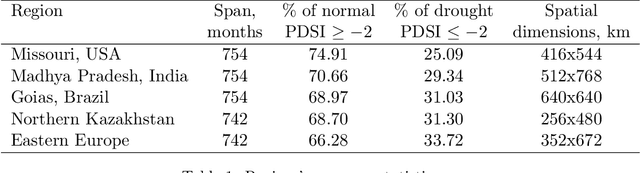
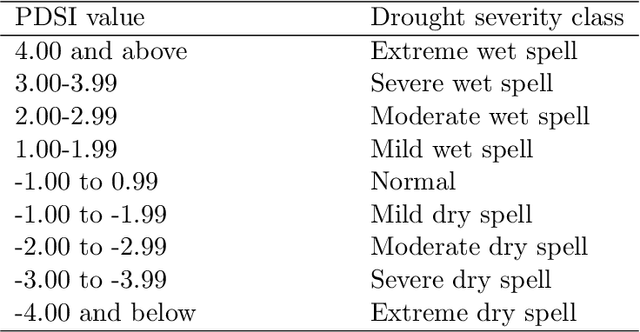
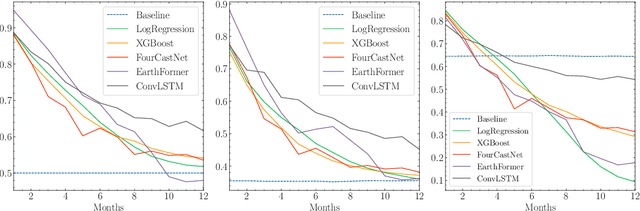
The accurate prediction of drought probability in specific regions is crucial for informed decision-making in agricultural practices. It is important to make predictions one year in advance, particularly for long-term decisions. However, forecasting this probability presents challenges due to the complex interplay of various factors within the region of interest and neighboring areas. In this study, we propose an end-to-end solution to address this issue based on various spatiotemporal neural networks. The models considered focus on predicting the drought intensity based on the Palmer Drought Severity Index (PDSI) for subregions of interest, leveraging intrinsic factors and insights from climate models to enhance drought predictions. Comparative evaluations demonstrate the superior accuracy of Convolutional LSTM (ConvLSTM) and transformer models compared to baseline gradient boosting and logistic regression solutions. The two former models achieved impressive ROC AUC scores from 0.90 to 0.70 for forecast horizons from one to six months, outperforming baseline models. The transformer showed superiority for shorter horizons, while ConvLSTM did so for longer horizons. Thus, we recommend selecting the models accordingly for long-term drought forecasting. To ensure the broad applicability of the considered models, we conduct extensive validation across regions worldwide, considering different environmental conditions. We also run several ablation and sensitivity studies to challenge our findings and provide additional information on how to solve the problem.
GP CC-OPF: Gaussian Process based optimization tool for Chance-Constrained Optimal Power Flow
Feb 16, 2023The Gaussian Process (GP) based Chance-Constrained Optimal Power Flow (CC-OPF) is an open-source Python code developed for solving economic dispatch (ED) problem in modern power grids. In recent years, integrating a significant amount of renewables into a power grid causes high fluctuations and thus brings a lot of uncertainty to power grid operations. This fact makes the conventional model-based CC-OPF problem non-convex and computationally complex to solve. The developed tool presents a novel data-driven approach based on the GP regression model for solving the CC-OPF problem with a trade-off between complexity and accuracy. The proposed approach and developed software can help system operators to effectively perform ED optimization in the presence of large uncertainties in the power grid.
Data-Driven Chance Constrained AC-OPF using Hybrid Sparse Gaussian Processes
Aug 30, 2022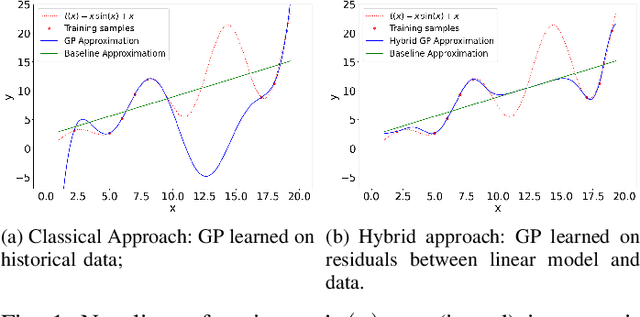
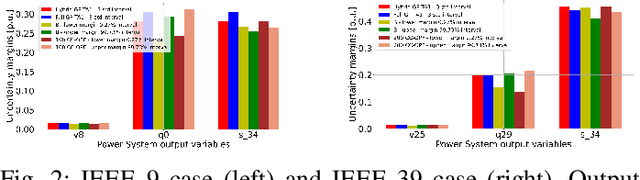
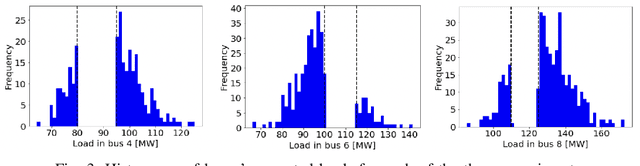
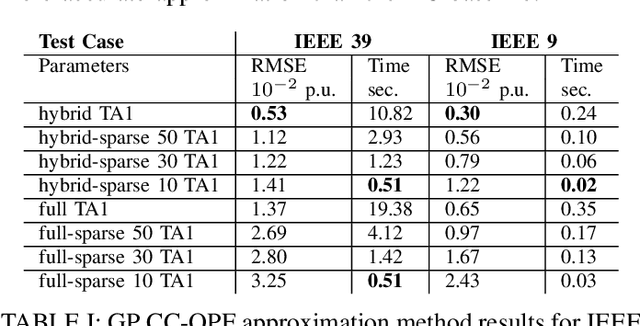
The alternating current (AC) chance-constrained optimal power flow (CC-OPF) problem addresses the economic efficiency of electricity generation and delivery under generation uncertainty. The latter is intrinsic to modern power grids because of the high amount of renewables. Despite its academic success, the AC CC-OPF problem is highly nonlinear and computationally demanding, which limits its practical impact. For improving the AC-OPF problem complexity/accuracy trade-off, the paper proposes a fast data-driven setup that uses the sparse and hybrid Gaussian processes (GP) framework to model the power flow equations with input uncertainty. We advocate the efficiency of the proposed approach by a numerical study over multiple IEEE test cases showing up to two times faster and more accurate solutions compared to the state-of-the-art methods.
Data-Driven Stochastic AC-OPF using Gaussian Processes
Jul 21, 2022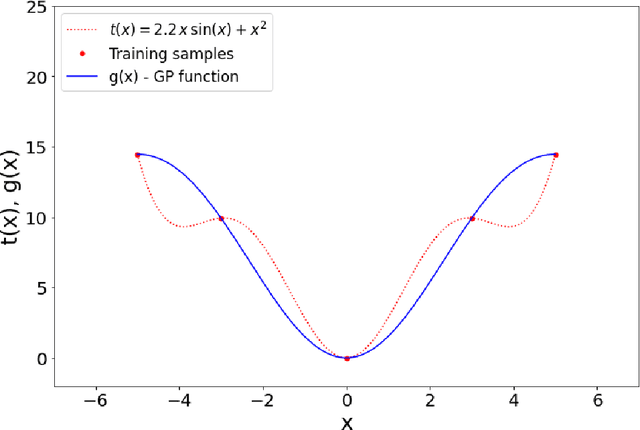
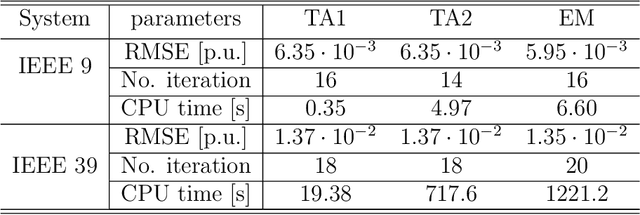
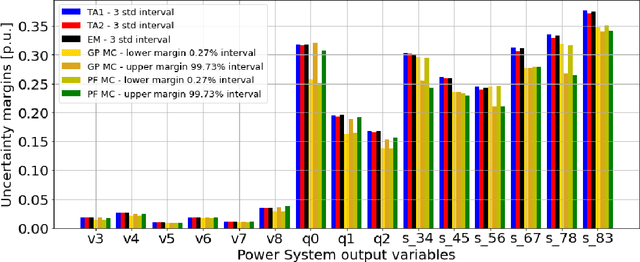
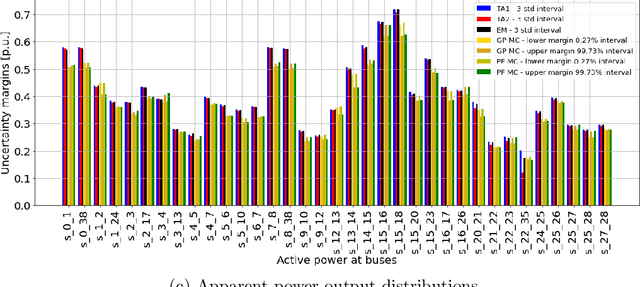
In recent years, electricity generation has been responsible for more than a quarter of the greenhouse gas emissions in the US. Integrating a significant amount of renewables into a power grid is probably the most accessible way to reduce carbon emissions from power grids and slow down climate change. Unfortunately, the most accessible renewable power sources, such as wind and solar, are highly fluctuating and thus bring a lot of uncertainty to power grid operations and challenge existing optimization and control policies. The chance-constrained alternating current (AC) optimal power flow (OPF) framework finds the minimum cost generation dispatch maintaining the power grid operations within security limits with a prescribed probability. Unfortunately, the AC-OPF problem's chance-constrained extension is non-convex, computationally challenging, and requires knowledge of system parameters and additional assumptions on the behavior of renewable distribution. Known linear and convex approximations to the above problems, though tractable, are too conservative for operational practice and do not consider uncertainty in system parameters. This paper presents an alternative data-driven approach based on Gaussian process (GP) regression to close this gap. The GP approach learns a simple yet non-convex data-driven approximation to the AC power flow equations that can incorporate uncertainty inputs. The latter is then used to determine the solution of CC-OPF efficiently, by accounting for both input and parameter uncertainty. The practical efficiency of the proposed approach using different approximations for GP-uncertainty propagation is illustrated over numerous IEEE test cases.
Learning over No-Preferred and Preferred Sequence of Items for Robust Recommendation (Extended Abstract)
Feb 26, 2022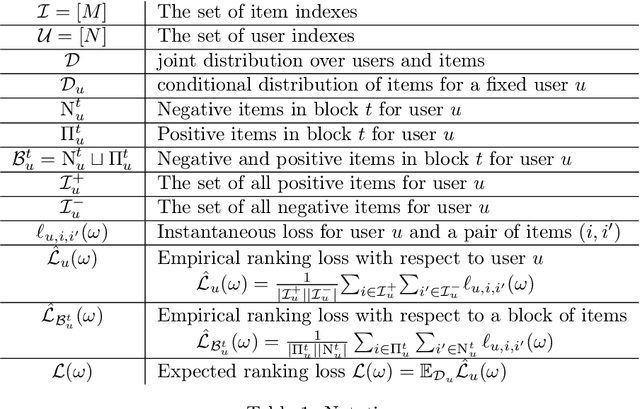
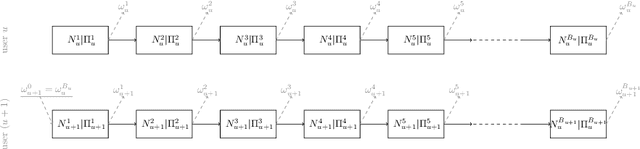
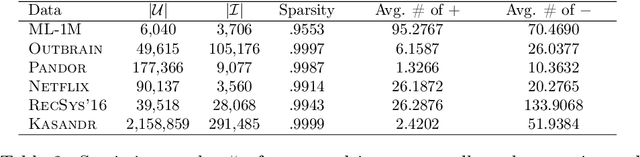
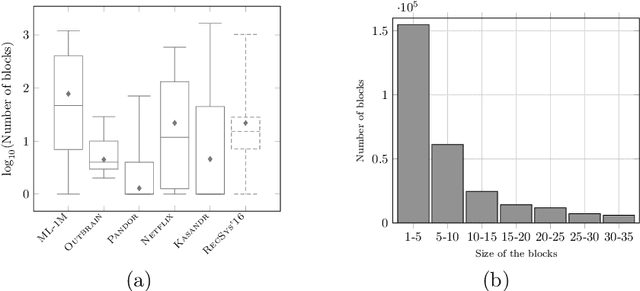
This paper is an extended version of [Burashnikova et al., 2021, arXiv: 2012.06910], where we proposed a theoretically supported sequential strategy for training a large-scale Recommender System (RS) over implicit feedback, mainly in the form of clicks. The proposed approach consists in minimizing pairwise ranking loss over blocks of consecutive items constituted by a sequence of non-clicked items followed by a clicked one for each user. We present two variants of this strategy where model parameters are updated using either the momentum method or a gradient-based approach. To prevent updating the parameters for an abnormally high number of clicks over some targeted items (mainly due to bots), we introduce an upper and a lower threshold on the number of updates for each user. These thresholds are estimated over the distribution of the number of blocks in the training set. They affect the decision of RS by shifting the distribution of items that are shown to the users. Furthermore, we provide a convergence analysis of both algorithms and demonstrate their practical efficiency over six large-scale collections with respect to various ranking measures.
Self-Training: A Survey
Feb 24, 2022
In recent years, semi-supervised algorithms have received a lot of interest in both academia and industry. Among the existing techniques, self-training methods have arguably received more attention in the last few years. These models are designed to search the decision boundary on low density regions without making extra assumptions on the data distribution, and use the unsigned output score of a learned classifier, or its margin, as an indicator of confidence. The working principle of self-training algorithms is to learn a classifier iteratively by assigning pseudo-labels to the set of unlabeled training samples with a margin greater than a certain threshold. The pseudo-labeled examples are then used to enrich the labeled training data and train a new classifier in conjunction with the labeled training set. We present self-training methods for binary and multiclass classification and their variants which were recently developed using Neural Networks. Finally, we discuss our ideas for future research in self-training. To the best of our knowledge, this is the first thorough and complete survey on this subject.