 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training: A Survey
Feb 24, 2022
In recent years, semi-supervised algorithms have received a lot of interest in both academia and industry. Among the existing techniques, self-training methods have arguably received more attention in the last few years. These models are designed to search the decision boundary on low density regions without making extra assumptions on the data distribution, and use the unsigned output score of a learned classifier, or its margin, as an indicator of confidence. The working principle of self-training algorithms is to learn a classifier iteratively by assigning pseudo-labels to the set of unlabeled training samples with a margin greater than a certain threshold. The pseudo-labeled examples are then used to enrich the labeled training data and train a new classifier in conjunction with the labeled training set. We present self-training methods for binary and multiclass classification and their variants which were recently developed using Neural Networks. Finally, we discuss our ideas for future research in self-training. To the best of our knowledge, this is the first thorough and complete survey on this subject.
Self-Learning for Received Signal Strength Map Reconstruction with Neural Architecture Search
May 17, 2021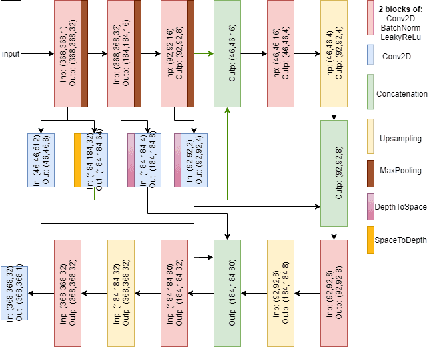
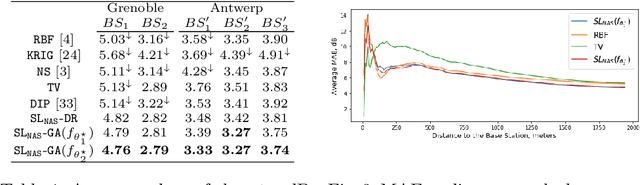
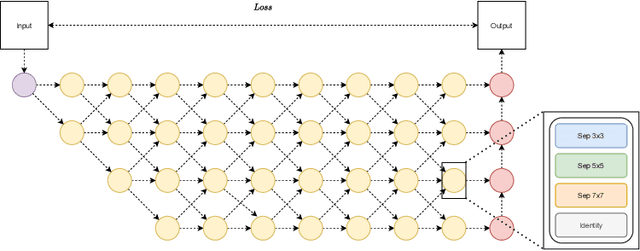
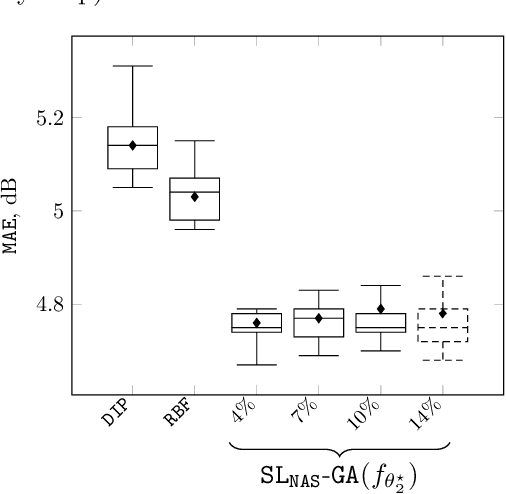
In this paper, we present a Neural Network (NN) model based on Neural Architecture Search (NAS) and self-learning for received signal strength (RSS) map reconstruction out of sparse single-snapshot input measurements, in the case where data-augmentation by side deterministic simulations cannot be performed. The approach first finds an optimal NN architecture and simultaneously train the deduced model over some ground-truth measurements of a given (RSS) map. These ground-truth measurements along with the predictions of the model over a set of randomly chosen points are then used to train a second NN model having the same architecture. Experimental results show that signal predictions of this second model outperforms non-learning based interpolation state-of-the-art techniques and NN models with no architecture search on five large-scale maps of RSS measurements.