 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEPAMatch: Geometric Representation Shaping for Semi-Supervised Learning
Apr 22, 2026Semi-supervised learning has emerged as a powerful paradigm for leveraging large amounts of unlabeled data to improve the performance of machine learning models when labeled data are scarce. Among existing approaches, methods derived from FixMatch have achieved state-of-the-art results in image classification by combining weak and strong data augmentations with confidence-based pseudo-labeling. Despite their strong empirical performance, these methods typically struggle with two critical bottlenecks: majority classes tend to dominate the learning process, which is amplified by incorrect pseudo-labels, leading to biased models. Furthermore, noisy early pseudo-labels prevent the model from forming clear decision boundaries, requiring prolonged training to learn informative representation. In this paper, we introduce a paradigm shift from conventional logical output threshold base, toward an explicit shaping of geometric representations. Our approach is inspired by the recently proposed Latent-Euclidean Joint-Embedding Predictive Architectures (LeJEPA), a theoretically grounded framework asserting that meaningful representations should exhibit an isotropic Gaussian structure in latent space. Building on this principle, we propose a new training objective that combines the classical semi-supervised loss used in FlexMatch, an adaptive extension of FixMatch, with a latent-space regularization term derived from LeJEPA. Our proposed approach, encourages well-structured representations while preserving the advantages of pseudo-labeling strategies. Through extensive experiments on CIFAR-100, STL-10 and Tiny-ImageNet, we demonstrate that the proposed method consistently outperforms existing baselines. In addition, our method significantly accelerates the convergence, drastically reducing the overall computational cost compared to standard FixMatch-based pipelines.
Stylized Meta-Album: Group-bias injection with style transfer to study robustness against distribution shifts
Dec 10, 2025We introduce Stylized Meta-Album (SMA), a new image classification meta-dataset comprising 24 datasets (12 content datasets, and 12 stylized datasets), designed to advance studies on out-of-distribution (OOD) generalization and related topics. Created using style transfer techniques from 12 subject classification datasets, SMA provides a diverse and extensive set of 4800 groups, combining various subjects (objects, plants, animals, human actions, textures) with multiple styles. SMA enables flexible control over groups and classes, allowing us to configure datasets to reflect diverse benchmark scenarios. While ideally, data collection would capture extensive group diversity, practical constraints often make this infeasible. SMA addresses this by enabling large and configurable group structures through flexible control over styles, subject classes, and domains-allowing datasets to reflect a wide range of real-world benchmark scenarios. This design not only expands group and class diversity, but also opens new methodological directions for evaluating model performance across diverse group and domain configurations-including scenarios with many minority groups, varying group imbalance, and complex domain shifts-and for studying fairness, robustness, and adaptation under a broader range of realistic conditions. To demonstrate SMA's effectiveness, we implemented two benchmarks: (1) a novel OOD generalization and group fairness benchmark leveraging SMA's domain, class, and group diversity to evaluate existing benchmarks. Our findings reveal that while simple balancing and algorithms utilizing group information remain competitive as claimed in previous benchmarks, increasing group diversity significantly impacts fairness, altering the superiority and relative rankings of algorithms. We also propose to use \textit{Top-M worst group accuracy} as a new hyperparameter tuning metric, demonstrating broader fairness during optimization and delivering better final worst-group accuracy for larger group diversity. (2) An unsupervised domain adaptation (UDA) benchmark utilizing SMA's group diversity to evaluate UDA algorithms across more scenarios, offering a more comprehensive benchmark with lower error bars (reduced by 73\% and 28\% in closed-set setting and UniDA setting, respectively) compared to existing efforts. These use cases highlight SMA's potential to significantly impact the outcomes of conventional benchmarks.
AI Agentic Vulnerability Injection And Transformation with Optimized Reasoning
Aug 28, 2025The increasing complexity of software systems and the sophistication of cyber-attacks have underscored the critical need for effective automated vulnerability detection and repair systems. Traditional methods, such as static program analysis, face significant challenges related to scalability, adaptability, and high false-positive and false-negative rates. AI-driven approaches, particularly those using machine learning and deep learning models, show promise but are heavily reliant on the quality and quantity of training data. This paper introduces a novel framework designed to automatically introduce realistic, category-specific vulnerabilities into secure C/C++ codebases to generate datasets. The proposed approach coordinates multiple AI agents that simulate expert reasoning, along with function agents and traditional code analysis tools. It leverages Retrieval-Augmented Generation for contextual grounding and employs Low-Rank approximation of weights for efficient model fine-tuning. Our experimental study on 116 code samples from three different benchmarks suggests that our approach outperforms other techniques with regard to dataset accuracy, achieving between 89\% and 95\% success rates in injecting vulnerabilities at function level.
Multi-Label Contrastive Learning : A Comprehensive Study
Nov 27, 2024



Multi-label classification, which involves assigning multiple labels to a single input, has emerged as a key area in both research and industry due to its wide-ranging applications. Designing effective loss functions is crucial for optimizing deep neural networks for this task, as they significantly influence model performance and efficiency. Traditional loss functions, which often maximize likelihood under the assumption of label independence, may struggle to capture complex label relationships. Recent research has turned to supervised contrastive learning, a method that aims to create a structured representation space by bringing similar instances closer together and pushing dissimilar ones apart. Although contrastive learning offers a promising approach, applying it to multi-label classification presents unique challenges, particularly in managing label interactions and data structure. In this paper, we conduct an in-depth study of contrastive learning loss for multi-label classification across diverse settings. These include datasets with both small and large numbers of labels, datasets with varying amounts of training data, and applications in both computer vision and natural language processing. Our empirical results indicate that the promising outcomes of contrastive learning are attributable not only to the consideration of label interactions but also to the robust optimization scheme of the contrastive loss. Furthermore, while the supervised contrastive loss function faces challenges with datasets containing a small number of labels and ranking-based metrics, it demonstrates excellent performance, particularly in terms of Macro-F1, on datasets with a large number of labels.
A Unified Contrastive Loss for Self-Training
Sep 11, 2024Self-training methods have proven to be effective in exploiting abundant unlabeled data in semi-supervised learning, particularly when labeled data is scarce. While many of these approaches rely on a cross-entropy loss function (CE), recent advances have shown that the supervised contrastive loss function (SupCon) can be more effective. Additionally, unsupervised contrastive learning approaches have also been shown to capture high quality data representations in the unsupervised setting. To benefit from these advantages in a semi-supervised setting, we propose a general framework to enhance self-training methods, which replaces all instances of CE losses with a unique contrastive loss. By using class prototypes, which are a set of class-wise trainable parameters, we recover the probability distributions of the CE setting and show a theoretical equivalence with it. Our framework, when applied to popular self-training methods, results in significant performance improvements across three different datasets with a limited number of labeled data. Additionally, we demonstrate further improvements in convergence speed, transfer ability, and hyperparameter stability. The code is available at \url{https://github.com/AurelienGauffre/semisupcon/}.
Unified Framework for Neural Network Compression via Decomposition and Optimal Rank Selection
Sep 05, 2024



Despite their high accuracy, complex neural networks demand significant computational resources, posing challenges for deployment on resource-constrained devices such as mobile phones and embedded systems. Compression algorithms have been developed to address these challenges by reducing model size and computational demands while maintaining accuracy. Among these approaches, factorization methods based on tensor decomposition are theoretically sound and effective. However, they face difficulties in selecting the appropriate rank for decomposition. This paper tackles this issue by presenting a unified framework that simultaneously applies decomposition and optimal rank selection, employing a composite compression loss within defined rank constraints. Our approach includes an automatic rank search in a continuous space, efficiently identifying optimal rank configurations without the use of training data, making it computationally efficient. Combined with a subsequent fine-tuning step, our approach maintains the performance of highly compressed models on par with their original counterparts. Using various benchmark datasets, we demonstrate the efficacy of our method through a comprehensive analysis.
Classification Tree-based Active Learning: A Wrapper Approach
Apr 15, 2024Supervised machine learning often requires large training sets to train accurate models, yet obtaining large amounts of labeled data is not always feasible. Hence, it becomes crucial to explore active learning methods for reducing the size of training sets while maintaining high accuracy. The aim is to select the optimal subset of data for labeling from an initial unlabeled set, ensuring precise prediction of outcomes. However, conventional active learning approaches are comparable to classical random sampling. This paper proposes a wrapper active learning method for classification, organizing the sampling process into a tree structure, that improves state-of-the-art algorithms. A classification tree constructed on an initial set of labeled samples is considered to decompose the space into low-entropy regions. Input-space based criteria are used thereafter to sub-sample from these regions, the total number of points to be labeled being decomposed into each region. This adaptation proves to be a significant enhancement over existing active learning methods. Through experiments conducted on various benchmark data sets, the paper demonstrates the efficacy of the proposed framework by being effective in constructing accurate classification models, even when provided with a severely restricted labeled data set.
Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
Apr 12, 2024Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the "lack of positives" and the "attraction-repulsion imbalance". Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
Pool-Based Active Learning with Proper Topological Regions
Oct 02, 2023
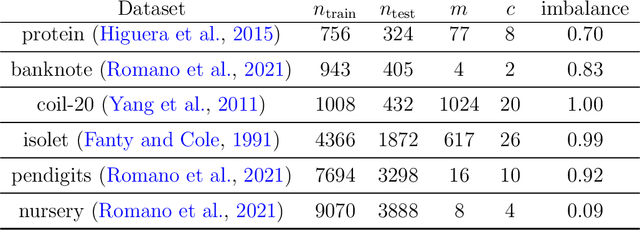


Machine learning methods usually rely on large sample size to have good performance, while it is difficult to provide labeled set in many applications. Pool-based active learning methods are there to detect, among a set of unlabeled data, the ones that are the most relevant for the training. We propose in this paper a meta-approach for pool-based active learning strategies in the context of multi-class classification tasks based on Proper Topological Regions. PTR, based on topological data analysis (TDA), are relevant regions used to sample cold-start points or within the active learning scheme. The proposed method is illustrated empirically on various benchmark datasets, being competitive to the classical methods from the literature.
Deep Learning with Partially Labeled Data for Radio Map Reconstruction
Jun 07, 2023



In this paper, we address the problem of Received Signal Strength map reconstruction based on location-dependent radio measurements and utilizing side knowledge about the local region; for example, city plan, terrain height, gateway position. Depending on the quantity of such prior side information, we employ Neural Architecture Search to find an optimized Neural Network model with the best architecture for each of the supposed settings. We demonstrate that using additional side information enhances the final accuracy of the Received Signal Strength map reconstruction on three datasets that correspond to three major cities, particularly in sub-areas near the gateways where larger variations of the average received signal power are typically observed.