 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Sequential Learning for Recommender and Engineering Systems
May 13, 2022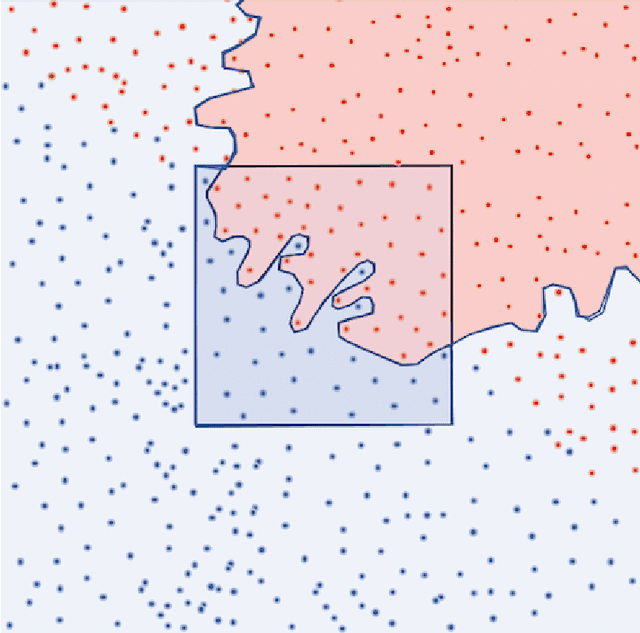
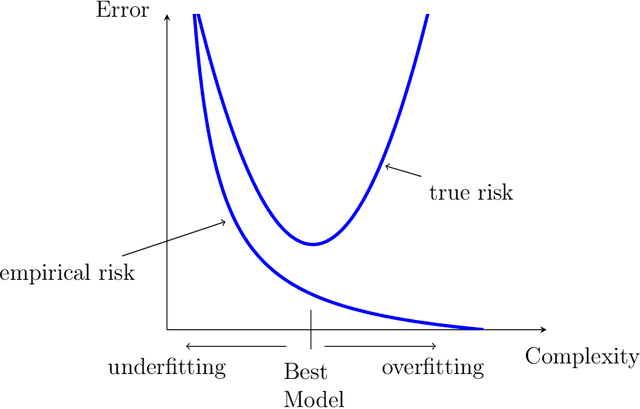
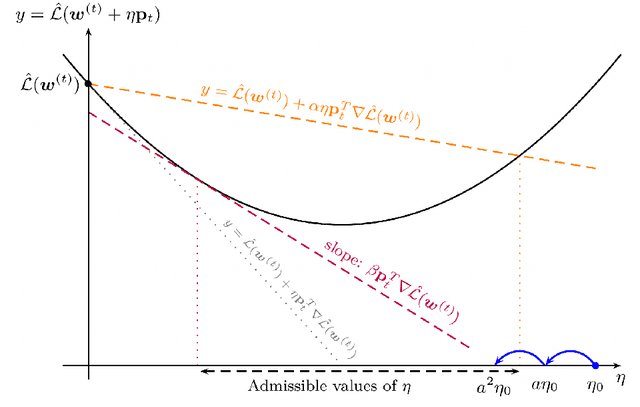
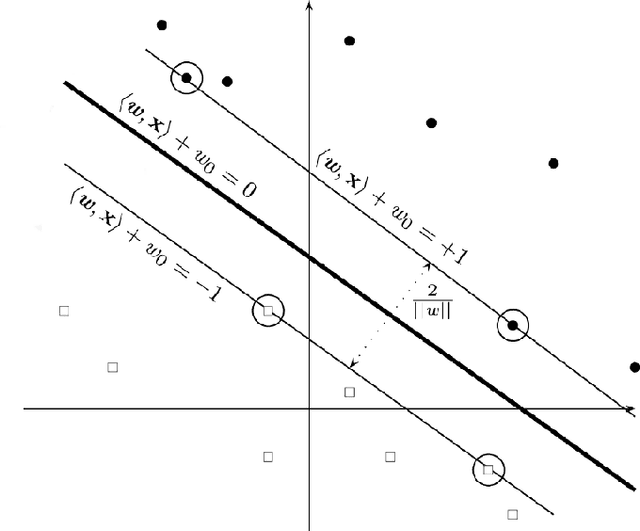
In this thesis, we focus on the design of an automatic algorithms that provide personalized ranking by adapting to the current conditions. To demonstrate the empirical efficiency of the proposed approaches we investigate their applications for decision making in recommender systems and energy systems domains. For the former, we propose novel algorithm called SAROS that take into account both kinds of feedback for learning over the sequence of interactions. The proposed approach consists in minimizing pairwise ranking loss over blocks constituted by a sequence of non-clicked items followed by the clicked one for each user. We also explore the influence of long memory on the accurateness of predictions. SAROS shows highly competitive and promising results based on quality metrics and also it turn out faster in terms of loss convergence than stochastic gradient descent and batch classical approaches. Regarding power systems, we propose an algorithm for faulted lines detection based on focusing of misclassifications in lines close to the true event location. The proposed idea of taking into account the neighbour lines shows statistically significant results in comparison with the initial approach based on convolutional neural networks for faults detection in power grid.
Learning over No-Preferred and Preferred Sequence of Items for Robust Recommendation (Extended Abstract)
Feb 26, 2022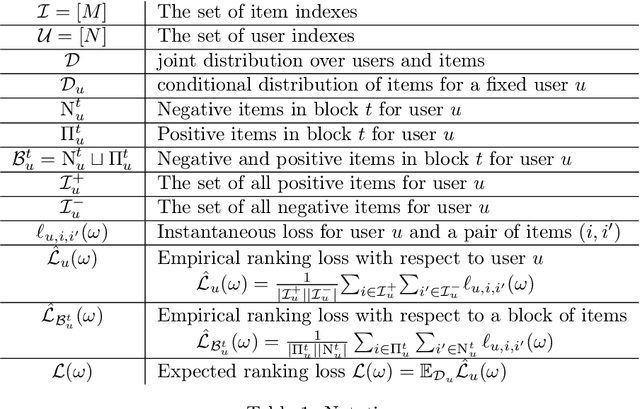
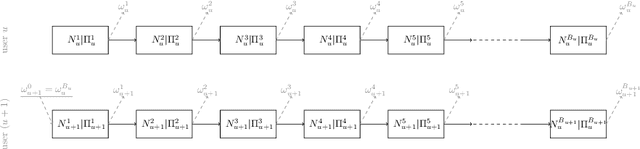
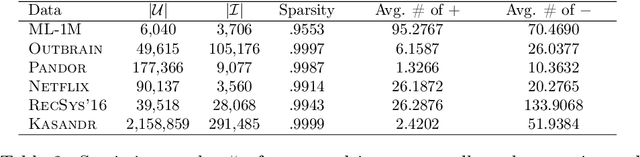
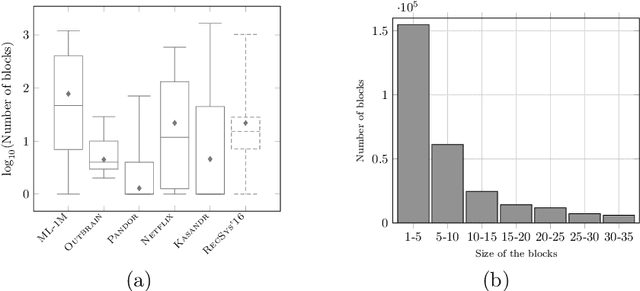
This paper is an extended version of [Burashnikova et al., 2021, arXiv: 2012.06910], where we proposed a theoretically supported sequential strategy for training a large-scale Recommender System (RS) over implicit feedback, mainly in the form of clicks. The proposed approach consists in minimizing pairwise ranking loss over blocks of consecutive items constituted by a sequence of non-clicked items followed by a clicked one for each user. We present two variants of this strategy where model parameters are updated using either the momentum method or a gradient-based approach. To prevent updating the parameters for an abnormally high number of clicks over some targeted items (mainly due to bots), we introduce an upper and a lower threshold on the number of updates for each user. These thresholds are estimated over the distribution of the number of blocks in the training set. They affect the decision of RS by shifting the distribution of items that are shown to the users. Furthermore, we provide a convergence analysis of both algorithms and demonstrate their practical efficiency over six large-scale collections with respect to various ranking measures.
Recommender systems: when memory matters
Dec 04, 2021


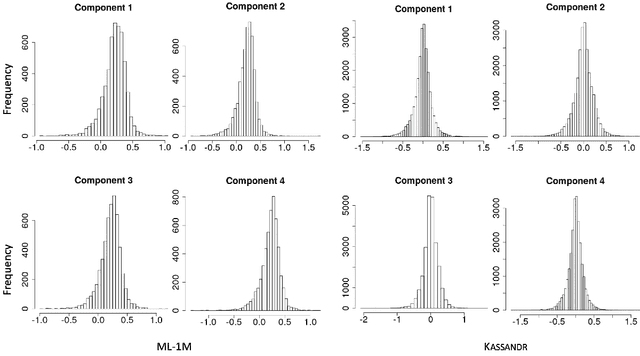
In this paper, we study the effect of long memory in the learnability of a sequential recommender system including users' implicit feedback. We propose an online algorithm, where model parameters are updated user per user over blocks of items constituted by a sequence of unclicked items followed by a clicked one. We illustrate through thorough empirical evaluations that filtering users with respect to the degree of long memory contained in their interactions with the system allows to substantially gain in performance with respect to MAP and NDCG, especially in the context of training large-scale Recommender Systems.
Learning over no-Preferred and Preferred Sequence of items for Robust Recommendation
Dec 12, 2020In this paper, we propose a theoretically founded sequential strategy for training large-scale Recommender Systems (RS) over implicit feedback, mainly in the form of clicks. The proposed approach consists in minimizing pairwise ranking loss over blocks of consecutive items constituted by a sequence of non-clicked items followed by a clicked one for each user. We present two variants of this strategy where model parameters are updated using either the momentum method or a gradient-based approach. To prevent from updating the parameters for an abnormally high number of clicks over some targeted items (mainly due to bots), we introduce an upper and a lower threshold on the number of updates for each user. These thresholds are estimated over the distribution of the number of blocks in the training set. The thresholds affect the decision of RS and imply a shift over the distribution of items that are shown to the users. Furthermore, we provide a convergence analysis of both algorithms and demonstrate their practical efficiency over six large-scale collections, both regarding different ranking measures and computational time.