 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Former ODE: Fast Probabilistic Forecasting of Irregular Time Series
Feb 12, 2026Probabilistic forecasting of irregularly sampled time series is crucial in domains such as healthcare and finance, yet it remains a formidable challenge. Existing Neural Controlled Differential Equation (Neural CDE) approaches, while effective at modelling continuous dynamics, suffer from slow, inherently sequential computation, which restricts scalability and limits access to global context. We introduce UFO (U-Former ODE), a novel architecture that seamlessly integrates the parallelizable, multiscale feature extraction of U-Nets, the powerful global modelling of Transformers, and the continuous-time dynamics of Neural CDEs. By constructing a fully causal, parallelizable model, UFO achieves a global receptive field while retaining strong sensitivity to local temporal dynamics. Extensive experiments on five standard benchmarks -- covering both regularly and irregularly sampled time series -- demonstrate that UFO consistently outperforms ten state-of-the-art neural baselines in predictive accuracy. Moreover, UFO delivers up to 15$\times$ faster inference compared to conventional Neural CDEs, with consistently strong performance on long and highly multivariate sequences.
A theoretical framework for self-supervised contrastive learning for continuous dependent data
Jun 11, 2025Self-supervised learning (SSL) has emerged as a powerful approach to learning representations, particularly in the field of computer vision. However, its application to dependent data, such as temporal and spatio-temporal domains, remains underexplored. Besides, traditional contrastive SSL methods often assume \emph{semantic independence between samples}, which does not hold for dependent data exhibiting complex correlations. We propose a novel theoretical framework for contrastive SSL tailored to \emph{continuous dependent data}, which allows the nearest samples to be semantically close to each other. In particular, we propose two possible \textit{ground truth similarity measures} between objects -- \emph{hard} and \emph{soft} closeness. Under it, we derive an analytical form for the \textit{estimated similarity matrix} that accommodates both types of closeness between samples, thereby introducing dependency-aware loss functions. We validate our approach, \emph{Dependent TS2Vec}, on temporal and spatio-temporal downstream problems. Given the dependency patterns presented in the data, our approach surpasses modern ones for dependent data, highlighting the effectiveness of our theoretically grounded loss functions for SSL in capturing spatio-temporal dependencies. Specifically, we outperform TS2Vec on the standard UEA and UCR benchmarks, with accuracy improvements of $4.17$\% and $2.08$\%, respectively. Furthermore, on the drought classification task, which involves complex spatio-temporal patterns, our method achieves a $7$\% higher ROC-AUC score.
Long-term drought prediction using deep neural networks based on geospatial weather data
Sep 19, 2023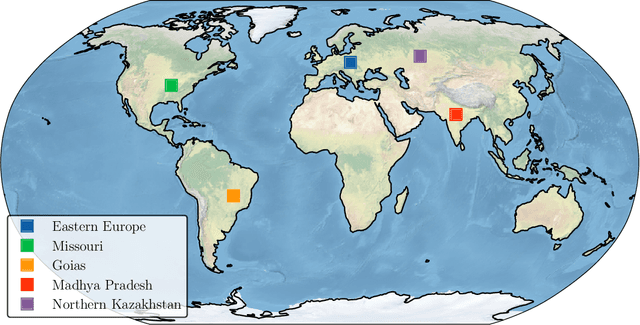
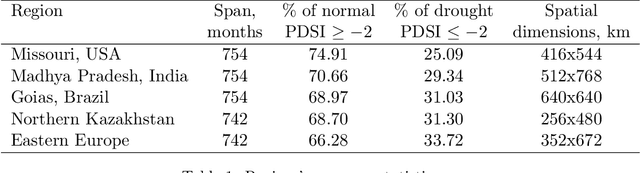
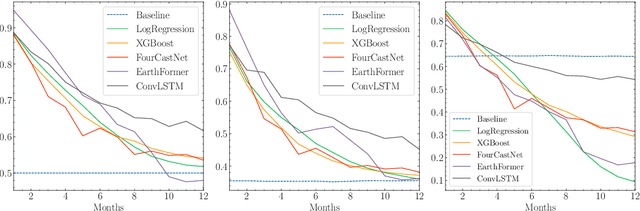
The accurate prediction of drought probability in specific regions is crucial for informed decision-making in agricultural practices. It is important to make predictions one year in advance, particularly for long-term decisions. However, forecasting this probability presents challenges due to the complex interplay of various factors within the region of interest and neighboring areas. In this study, we propose an end-to-end solution to address this issue based on various spatiotemporal neural networks. The models considered focus on predicting the drought intensity based on the Palmer Drought Severity Index (PDSI) for subregions of interest, leveraging intrinsic factors and insights from climate models to enhance drought predictions. Comparative evaluations demonstrate the superior accuracy of Convolutional LSTM (ConvLSTM) and transformer models compared to baseline gradient boosting and logistic regression solutions. The two former models achieved impressive ROC AUC scores from 0.90 to 0.70 for forecast horizons from one to six months, outperforming baseline models. The transformer showed superiority for shorter horizons, while ConvLSTM did so for longer horizons. Thus, we recommend selecting the models accordingly for long-term drought forecasting. To ensure the broad applicability of the considered models, we conduct extensive validation across regions worldwide, considering different environmental conditions. We also run several ablation and sensitivity studies to challenge our findings and provide additional information on how to solve the problem.
Non-contrastive approaches to similarity learning: positive examples are all you need
Sep 28, 2022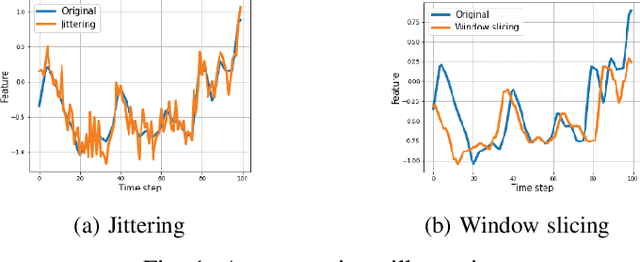



The similarity learning problem in the oil \& gas industry aims to construct a model that estimates similarity between interval measurements for logging data. Previous attempts are mostly based on empirical rules, so our goal is to automate this process and exclude expensive and time-consuming expert labelling. One of the approaches for similarity learning is self-supervised learning (SSL). In contrast to the supervised paradigm, this one requires little or no labels for the data. Thus, we can learn such models even if the data labelling is absent or scarce. Nowadays, most SSL approaches are contrastive and non-contrastive. However, due to possible wrong labelling of positive and negative samples, contrastive methods don't scale well with the number of objects. Non-contrastive methods don't rely on negative samples. Such approaches are actively used in the computer vision. We introduce non-contrastive SSL for time series data. In particular, we build on top of BYOL and Barlow Twins methods that avoid using negative pairs and focus only on matching positive pairs. The crucial part of these methods is an augmentation strategy. Different augmentations of time series exist, while their effect on the performance can be both positive and negative. Our augmentation strategies and adaption for BYOL and Barlow Twins together allow us to achieve a higher quality (ARI $= 0.49$) than other self-supervised methods (ARI $= 0.34$ only), proving usefulness of the proposed non-contrastive self-supervised approach for the interval similarity problem and time series representation learning in general.