 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIV-EX: Counterfactual Explanations for Driving LLMs
Feb 28, 2026Large language models (LLMs) are increasingly used as reasoning engines in autonomous driving, yet their decision-making remains opaque. We propose to study their decision process through counterfactual explanations, which identify the minimal semantic changes to a scene description required to alter a driving plan. We introduce DRIV-EX, a method that leverages gradient-based optimization on continuous embeddings to identify the input shifts required to flip the model's decision. Crucially, to avoid the incoherent text typical of unconstrained continuous optimization, DRIV-EX uses these optimized embeddings solely as a semantic guide: they are used to bias a controlled decoding process that re-generates the original scene description. This approach effectively steers the generation toward the counterfactual target while guaranteeing the linguistic fluency, domain validity, and proximity to the original input, essential for interpretability. Evaluated using the LC-LLM planner on a textual transcription of the highD dataset, DRIV-EX generates valid, fluent counterfactuals more reliably than existing baselines. It successfully exposes latent biases and provides concrete insights to improve the robustness of LLM-based driving agents.
Identifiability in Causal Abstractions: A Hierarchy of Criteria
Jul 08, 2025Identifying the effect of a treatment from observational data typically requires assuming a fully specified causal diagram. However, such diagrams are rarely known in practice, especially in complex or high-dimensional settings. To overcome this limitation, recent works have explored the use of causal abstractions-simplified representations that retain partial causal information. In this paper, we consider causal abstractions formalized as collections of causal diagrams, and focus on the identifiability of causal queries within such collections. We introduce and formalize several identifiability criteria under this setting. Our main contribution is to organize these criteria into a structured hierarchy, highlighting their relationships. This hierarchical view enables a clearer understanding of what can be identified under varying levels of causal knowledge. We illustrate our framework through examples from the literature and provide tools to reason about identifiability when full causal knowledge is unavailable.
Identifiability by common backdoor in summary causal graphs of time series
Jun 17, 2025The identifiability problem for interventions aims at assessing whether the total effect of some given interventions can be written with a do-free formula, and thus be computed from observational data only. We study this problem, considering multiple interventions and multiple effects, in the context of time series when only abstractions of the true causal graph in the form of summary causal graphs are available. We focus in this study on identifiability by a common backdoor set, and establish, for time series with and without consistency throughout time, conditions under which such a set exists. We also provide algorithms of limited complexity to decide whether the problem is identifiable or not.
Complete Characterization for Adjustment in Summary Causal Graphs of Time Series
Jun 17, 2025The identifiability problem for interventions aims at assessing whether the total causal effect can be written with a do-free formula, and thus be estimated from observational data only. We study this problem, considering multiple interventions, in the context of time series when only an abstraction of the true causal graph, in the form of a summary causal graph, is available. We propose in particular both necessary and sufficient conditions for the adjustment criterion, which we show is complete in this setting, and provide a pseudo-linear algorithm to decide whether the query is identifiable or not.
Enhanced Retrieval of Long Documents: Leveraging Fine-Grained Block Representations with Large Language Models
Jan 28, 2025


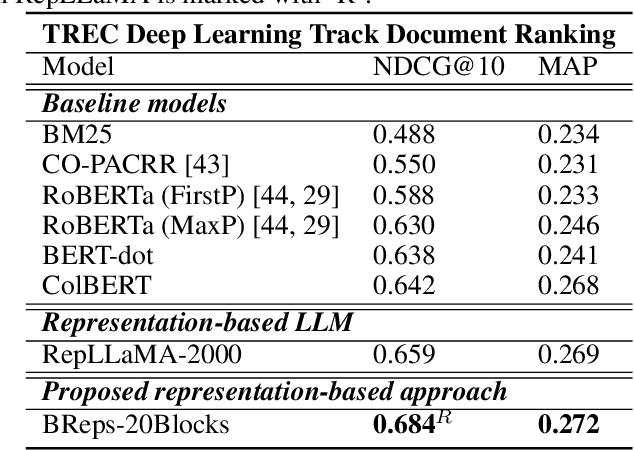
In recent years, large language models (LLMs) have demonstrated exceptional power in various domains, including information retrieval. Most of the previous practices involve leveraging these models to create a single embedding for each query, each passage, or each document individually, a strategy exemplified and used by the Retrieval-Augmented Generation (RAG) framework. While this method has proven effective, we argue that it falls short in fully capturing the nuanced intricacies of document-level texts due to its reliance on a relatively coarse-grained representation. To address this limitation, we introduce a novel, fine-grained approach aimed at enhancing the accuracy of relevance scoring for long documents. Our methodology firstly segments a long document into blocks, each of which is embedded using an LLM, for matching with the query representation. When calculating the relevance score, we aggregate the query-block relevance scores through a weighted sum method, yielding a comprehensive score for the query with the entire document. Despite its apparent simplicity, our experimental findings reveal that this approach outperforms standard representation methods and achieves a significant reduction in embedding generation latency. Moreover, by carefully optimizing pairwise loss functions, superior performances have been achieved.
GIFT: A Framework for Global Interpretable Faithful Textual Explanations of Vision Classifiers
Nov 23, 2024



Understanding deep models is crucial for deploying them in safety-critical applications. We introduce GIFT, a framework for deriving post-hoc, global, interpretable, and faithful textual explanations for vision classifiers. GIFT starts from local faithful visual counterfactual explanations and employs (vision) language models to translate those into global textual explanations. Crucially, GIFT provides a verification stage measuring the causal effect of the proposed explanations on the classifier decision. Through experiments across diverse datasets, including CLEVR, CelebA, and BDD, we demonstrate that GIFT effectively reveals meaningful insights, uncovering tasks, concepts, and biases used by deep vision classifiers. Our code, data, and models are released at https://github.com/valeoai/GIFT.
KeyB2: Selecting Key Blocks is Also Important for Long Document Ranking with Large Language Models
Nov 09, 2024


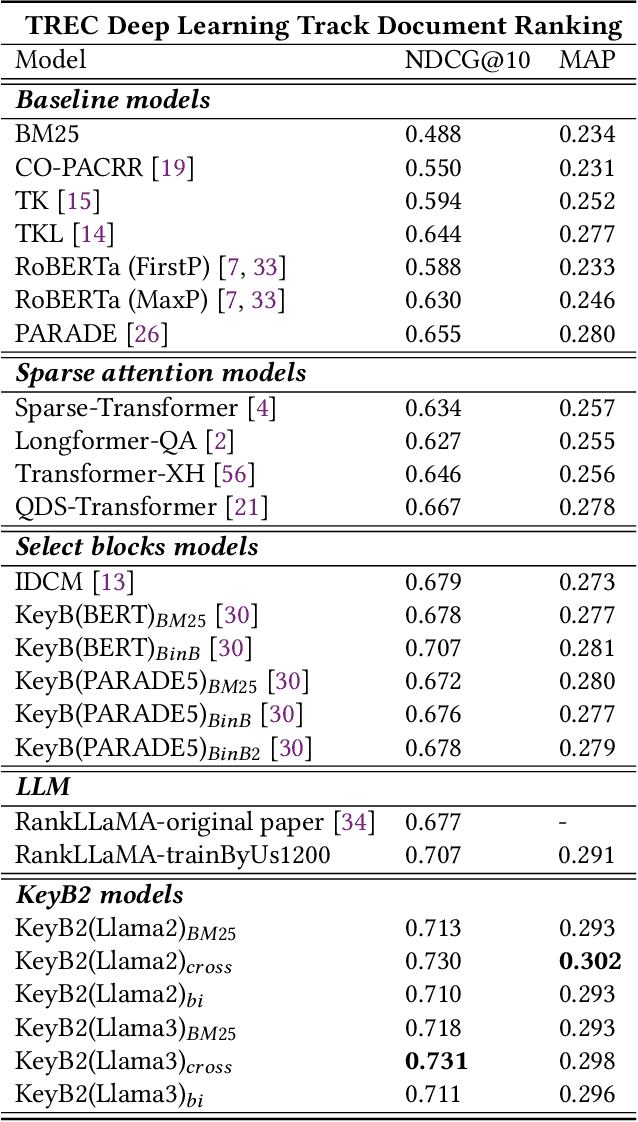
The rapid development of large language models (LLMs) like Llama has significantly advanced information retrieval (IR) systems. However, using LLMs for long documents, as in RankLLaMA, remains challenging due to computational complexity, especially concerning input token length. Furthermore, the internal mechanisms of LLMs during ranking are still not fully understood. In this paper, we first explore the internal workings of LLMs during relevance judgement and identify that specific attention heads play a crucial role in aligning relevant tokens. This observation inspires us to revisit the block pre-ranking strategy used in KeyB, which remains state-of-the-art (SOTA) on the TREC 2019 DL document ranking dataset. Building on these insights, we develop KeyB2, an advanced long document IR approach that integrates block pre-ranking with the performance of LLMs. KeyB2 efficiently identifies and processes the most relevant blocks, reducing computational costs and improving ranking effectiveness. Additionally, we introduce a new bi-encoder block matching strategy for KeyB2. Comprehensive experiments on long-document datasets, including TREC 2019 DL, Robust04, and MLDR-zh, show that KeyB2 outperforms baselines like RankLLaMA and KeyB by reducing reranking time and GPU memory usage while enhancing retrieval performance, achieving new SOTA results on TREC 2019 DL with higher NDCG@10 and MAP scores.
Domain Adaptation for Dense Retrieval and Conversational Dense Retrieval through Self-Supervision by Meticulous Pseudo-Relevance Labeling
Mar 13, 2024
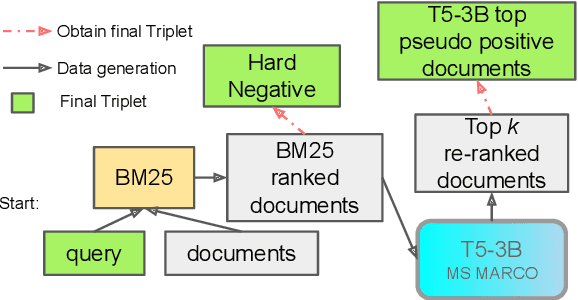
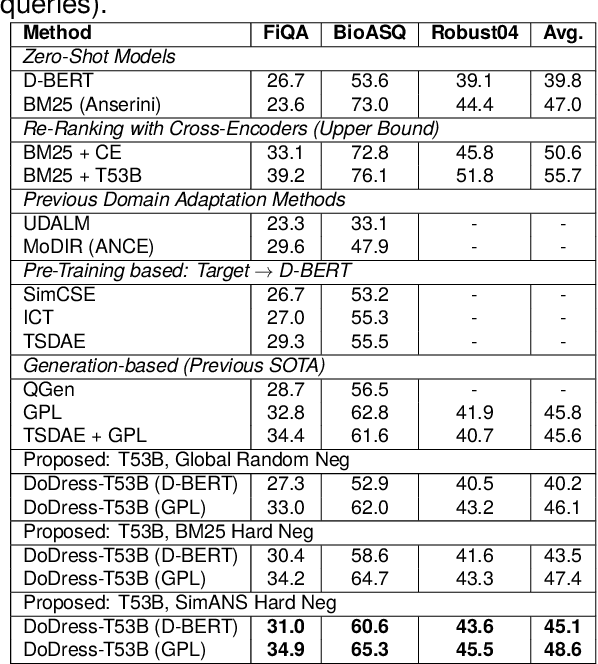
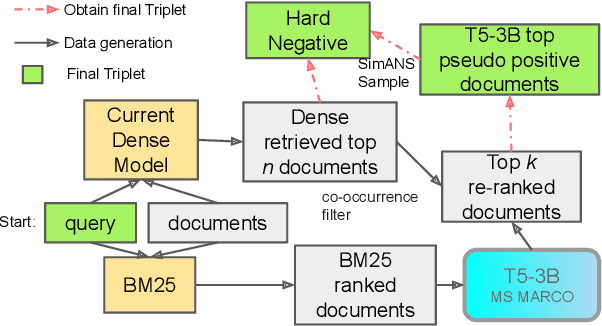
Recent studies have demonstrated that the ability of dense retrieval models to generalize to target domains with different distributions is limited, which contrasts with the results obtained with interaction-based models. Prior attempts to mitigate this challenge involved leveraging adversarial learning and query generation approaches, but both approaches nevertheless resulted in limited improvements. In this paper, we propose to combine the query-generation approach with a self-supervision approach in which pseudo-relevance labels are automatically generated on the target domain. To accomplish this, a T5-3B model is utilized for pseudo-positive labeling, and meticulous hard negatives are chosen. We also apply this strategy on conversational dense retrieval model for conversational search. A similar pseudo-labeling approach is used, but with the addition of a query-rewriting module to rewrite conversational queries for subsequent labeling. This proposed approach enables a model's domain adaptation with real queries and documents from the target dataset. Experiments on standard dense retrieval and conversational dense retrieval models both demonstrate improvements on baseline models when they are fine-tuned on the pseudo-relevance labeled data.
On the Fly Detection of Root Causes from Observed Data with Application to IT Systems
Feb 09, 2024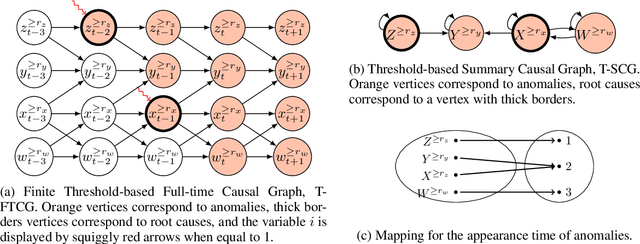
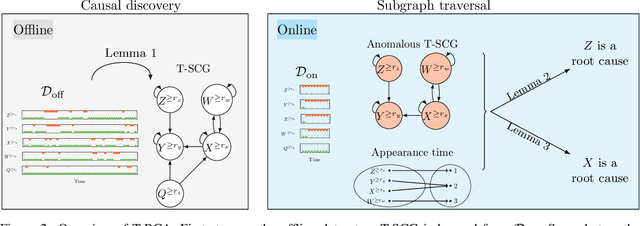
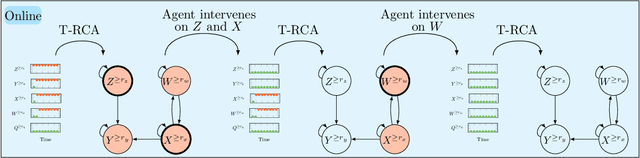
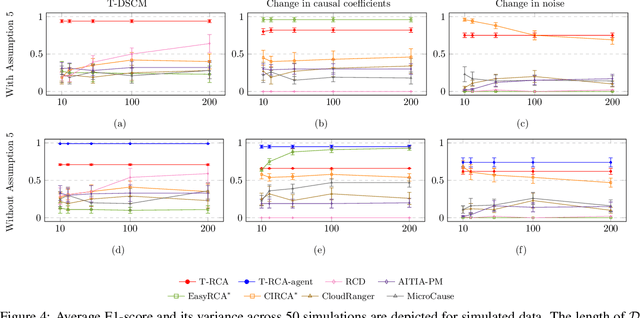
This paper introduces a new structural causal model tailored for representing threshold-based IT systems and presents a new algorithm designed to rapidly detect root causes of anomalies in such systems. When root causes are not causally related, the method is proven to be correct; while an extension is proposed based on the intervention of an agent to relax this assumption. Our algorithm and its agent-based extension leverage causal discovery from offline data and engage in subgraph traversal when encountering new anomalies in online data. Our extensive experiments demonstrate the superior performance of our methods, even when applied to data generated from alternative structural causal models or real IT monitoring data.
Identifiability of total effects from abstractions of time series causal graphs
Nov 02, 2023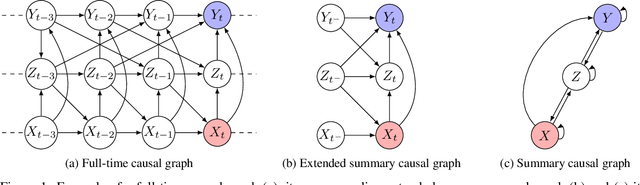
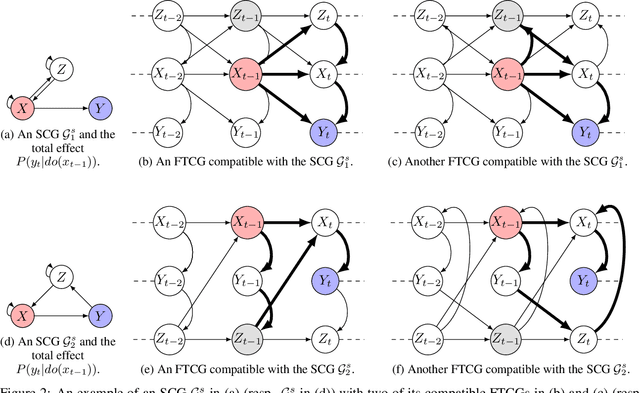
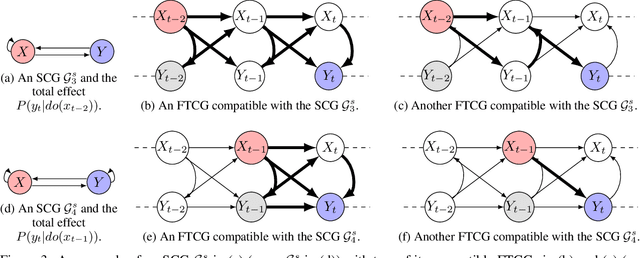

We study the problem of identifiability of the total effect of an intervention from observational time series only given an abstraction of the causal graph of the system. Specifically, we consider two types of abstractions: the extended summary causal graph which conflates all lagged causal relations but distinguishes between lagged and instantaneous relations; and the summary causal graph which does not give any indication about the lag between causal relations. We show that the total effect is always identifiable in extended summary causal graphs and we provide necessary and sufficient graphical conditions for identifiability in summary causal graphs. Furthermore, we provide adjustment sets allowing to estimate the total effect whenever it is identifiable.