 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIER: Generative Legal Inference and Evidence Ranking for Legal Case Retrieval
Apr 26, 2026The semantic gap between colloquial user queries and professional legal documents presents a fundamental challenge in Legal Case Retrieval (LCR). Existing dense retrieval methods typically treat LCR as a black-box semantic matching process, neglecting the explicit juridical logic that underpins legal relevance. To address this, we propose GLIER (Generative Legal Inference and Evidence Ranking), a framework that reformulates retrieval as an inference process over latent legal variables. GLIER decomposes the task into two interpretability-driven stages. First, a Joint Generative Inference module translates raw queries into latent legal indicators, including charges and legal elements, using a unified sequence-to-sequence strategy that jointly generates charges and elements to enforce logical consistency. Second, a Multi-View Evidence Fusion mechanism aggregates generative confidence with structural and lexical signals for precise ranking. Extensive experiments on LeCaRD and LeCaRDv2 demonstrate that GLIER outperforms strong baselines such as SAILER and KELLER. Notably, GLIER exhibits strong data efficiency, maintaining robust performance even when trained with only 10% of the data.
S2G-RAG: Structured Sufficiency and Gap Judging for Iterative Retrieval-Augmented QA
Apr 26, 2026Retrieval-Augmented Generation (RAG) grounds language models in external evidence, but multi-hop question answering remains difficult because iterative pipelines must control what to retrieve next and when the available evidence is adequate. In practice, systems may answer from incomplete evidence chains, or they may accumulate redundant or distractor-heavy text that interferes with later retrieval and reasoning. We propose S2G-RAG (Structured Sufficiency and Gap-judging RAG), an iterative framework with an explicit controller, S2G-Judge. At each turn, S2G-Judge predicts whether the current evidence memory supports answering and, if not, outputs structured gap items that describe the missing information. These gap items are then mapped into the next retrieval query, producing stable multi-turn retrieval trajectories. To reduce noise accumulation, S2G-RAG maintains a sentence-level Evidence Context by extracting a compact set of relevant sentences from retrieved documents. Experiments on TriviaQA, HotpotQA, and 2WikiMultiHopQA show that S2G-RAG improves multi-hop QA performance and robustness under multi-turn retrieval. Furthermore, S2G-RAG can be integrated into existing RAG pipelines as a lightweight component, without modifying the search engine or retraining the generator.
GenState-AI: State-Aware Dataset for Text-to-Video Retrieval on AI-Generated Videos
Mar 15, 2026Existing text-to-video retrieval benchmarks are dominated by real-world footage where much of the semantics can be inferred from a single frame, leaving temporal reasoning and explicit end-state grounding under-evaluated. We introduce GenState-AI, an AI-generated benchmark centered on controlled state transitions, where each query is paired with a main video, a temporal hard negative that differs only in the decisive end-state, and a semantic hard negative with content substitution, enabling fine-grained diagnosis of temporal vs. semantic confusions beyond appearance matching. Using Wan2.2-TI2V-5B, we generate short clips whose meaning depends on precise changes in position, quantity, and object relations, providing controllable evaluation conditions for state-aware retrieval. We evaluate two representative MLLM-based baselines, and observe consistent and interpretable failure patterns: both frequently confuse the main video with the temporal hard negative and over-prefer temporally plausible but end-state-incorrect clips, indicating insufficient grounding to decisive end-state evidence, while being comparatively less sensitive to semantic substitutions. We further introduce triplet-based diagnostic analyses, including relative-order statistics and breakdowns across transition categories, to make temporal vs. semantic failure sources explicit. GenState-AI provides a focused testbed for state-aware, temporally and semantically sensitive text-to-video retrieval, and will be released on huggingface.co.
Retrieval-Feedback-Driven Distillation and Preference Alignment for Efficient LLM-based Query Expansion
Mar 14, 2026Large language models have recently enabled a generative paradigm for query expansion, but their high inference cost makes direct deployment difficult in practical retrieval systems. To address this issue, a retrieval-feedback-driven distillation and preference-alignment framework is proposed to transfer retrieval-friendly expansion behavior from a strong teacher model to a compact student model. Rather than relying on few-shot exemplars at inference time, the framework first leverages two complementary types of teacher-generated expansions, produced under zero-shot and few-shot prompting conditions, as supervision signals for distillation and as candidate pools for preference construction. A retrieval-metric-driven strategy is then introduced to automatically form chosen/rejected expansion pairs according to nDCG@10 differences, and Direct Preference Optimization is applied to explicitly align generation preferences with retrieval objectives. Experiments on TREC DL19/20/21 and MIRACL-zh show that the proposed approach preserves strong retrieval effectiveness while substantially reducing inference cost. In particular, the distilled Qwen3-4B model reaches about 97% of the teacher (DeepSeek-685B) model's nDCG@10 performance on DL19, and remains effective on the Chinese MIRACL-zh benchmark, demonstrating strong practicality across both English and Chinese retrieval settings.
Automatic In-Domain Exemplar Construction and LLM-Based Refinement of Multi-LLM Expansions for Query Expansion
Feb 09, 2026Query expansion with large language models is promising but often relies on hand-crafted prompts, manually chosen exemplars, or a single LLM, making it non-scalable and sensitive to domain shift. We present an automated, domain-adaptive QE framework that builds in-domain exemplar pools by harvesting pseudo-relevant passages using a BM25-MonoT5 pipeline. A training-free cluster-based strategy selects diverse demonstrations, yielding strong and stable in-context QE without supervision. To further exploit model complementarity, we introduce a two-LLM ensemble in which two heterogeneous LLMs independently generate expansions and a refinement LLM consolidates them into one coherent expansion. Across TREC DL20, DBPedia, and SciFact, the refined ensemble delivers consistent and statistically significant gains over BM25, Rocchio, zero-shot, and fixed few-shot baselines. The framework offers a reproducible testbed for exemplar selection and multi-LLM generation, and a practical, label-free solution for real-world QE.
PCoKG: Personality-aware Commonsense Reasoning with Debate
Jan 09, 2026Most commonsense reasoning models overlook the influence of personality traits, limiting their effectiveness in personalized systems such as dialogue generation. To address this limitation, we introduce the Personality-aware Commonsense Knowledge Graph (PCoKG), a structured dataset comprising 521,316 quadruples. We begin by employing three evaluators to score and filter events from the ATOMIC dataset, selecting those that are likely to elicit diverse reasoning patterns across different personality types. For knowledge graph construction, we leverage the role-playing capabilities of large language models (LLMs) to perform reasoning tasks. To enhance the quality of the generated knowledge, we incorporate a debate mechanism consisting of a proponent, an opponent, and a judge, which iteratively refines the outputs through feedback loops. We evaluate the dataset from multiple perspectives and conduct fine-tuning and ablation experiments using multiple LLM backbones to assess PCoKG's robustness and the effectiveness of its construction pipeline. Our LoRA-based fine-tuning results indicate a positive correlation between model performance and the parameter scale of the base models. Finally, we apply PCoKG to persona-based dialogue generation, where it demonstrates improved consistency between generated responses and reference outputs. This work bridges the gap between commonsense reasoning and individual cognitive differences, enabling the development of more personalized and context-aware AI systems.
Towards Closed-Loop Embodied Empathy Evolution: Probing LLM-Centric Lifelong Empathic Motion Generation in Unseen Scenarios
Dec 22, 2025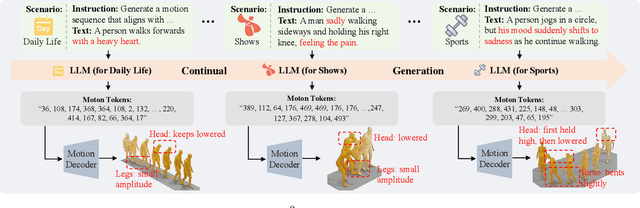

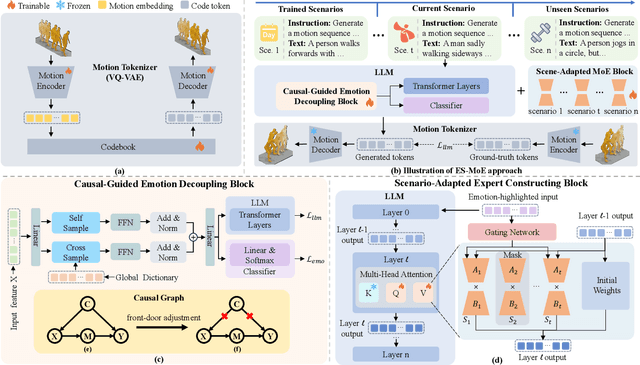
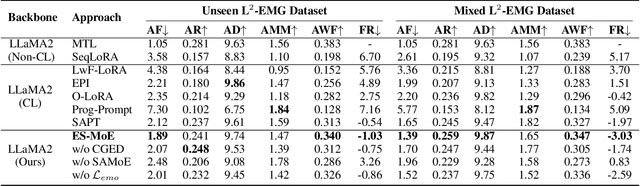
In the literature, existing human-centric emotional motion generation methods primarily focus on boosting performance within a single scale-fixed dataset, largely neglecting the flexible and scale-increasing motion scenarios (e.g., sports, dance), whereas effectively learning these newly emerging scenarios can significantly enhance the model's real-world generalization ability. Inspired by this, this paper proposes a new LLM-Centric Lifelong Empathic Motion Generation (L^2-EMG) task, which aims to equip LLMs with the capability to continually acquire emotional motion generation knowledge across different unseen scenarios, potentially contributing to building a closed-loop and self-evolving embodied agent equipped with both empathy and intelligence. Further, this paper poses two key challenges in the L^2-EMG task, i.e., the emotion decoupling challenge and the scenario adapting challenge. To this end, this paper proposes an Emotion-Transferable and Scenario-Adapted Mixture of Experts (ES-MoE) approach which designs a causal-guided emotion decoupling block and a scenario-adapted expert constructing block to address the two challenges, respectively. Especially, this paper constructs multiple L^2-EMG datasets to validate the effectiveness of the ES-MoE approach. Extensive evaluations show that ES-MoE outperforms advanced baselines.
RFKG-CoT: Relation-Driven Adaptive Hop-count Selection and Few-Shot Path Guidance for Knowledge-Aware QA
Dec 17, 2025Large language models (LLMs) often generate hallucinations in knowledge-intensive QA due to parametric knowledge limitations. While existing methods like KG-CoT improve reliability by integrating knowledge graph (KG) paths, they suffer from rigid hop-count selection (solely question-driven) and underutilization of reasoning paths (lack of guidance). To address this, we propose RFKG-CoT: First, it replaces the rigid hop-count selector with a relation-driven adaptive hop-count selector that dynamically adjusts reasoning steps by activating KG relations (e.g., 1-hop for direct "brother" relations, 2-hop for indirect "father-son" chains), formalized via a relation mask. Second, it introduces a few-shot in-context learning path guidance mechanism with CoT (think) that constructs examples in a "question-paths-answer" format to enhance LLMs' ability to understand reasoning paths. Experiments on four KGQA benchmarks show RFKG-CoT improves accuracy by up to 14.7 pp (Llama2-7B on WebQSP) over KG-CoT. Ablations confirm the hop-count selector and the path prompt are complementary, jointly transforming KG evidence into more faithful answers.
Query Expansion in the Age of Pre-trained and Large Language Models: A Comprehensive Survey
Sep 09, 2025Modern information retrieval (IR) must bridge short, ambiguous queries and ever more diverse, rapidly evolving corpora. Query Expansion (QE) remains a key mechanism for mitigating vocabulary mismatch, but the design space has shifted markedly with pre-trained language models (PLMs) and large language models (LLMs). This survey synthesizes the field from three angles: (i) a four-dimensional framework of query expansion - from the point of injection (explicit vs. implicit QE), through grounding and interaction (knowledge bases, model-internal capabilities, multi-turn retrieval) and learning alignment, to knowledge graph-based argumentation; (ii) a model-centric taxonomy spanning encoder-only, encoder-decoder, decoder-only, instruction-tuned, and domain/multilingual variants, highlighting their characteristic affordances for QE (contextual disambiguation, controllable generation, zero-/few-shot reasoning); and (iii) practice-oriented guidance on where and how neural QE helps in first-stage retrieval, multi-query fusion, re-ranking, and retrieval-augmented generation (RAG). We compare traditional query expansion with PLM/LLM-based methods across seven key aspects, and we map applications across web search, biomedicine, e-commerce, open-domain QA/RAG, conversational and code search, and cross-lingual settings. The review distills design grounding and interaction, alignment/distillation (SFT/PEFT/DPO), and KG constraints - as robust remedies to topic drift and hallucination. We conclude with an agenda on quality control, cost-aware invocation, domain/temporal adaptation, evaluation beyond end-task metrics, and fairness/privacy. Collectively, these insights provide a principled blueprint for selecting and combining QE techniques under real-world constraints.
A Survey of Long-Document Retrieval in the PLM and LLM Era
Sep 09, 2025



The proliferation of long-form documents presents a fundamental challenge to information retrieval (IR), as their length, dispersed evidence, and complex structures demand specialized methods beyond standard passage-level techniques. This survey provides the first comprehensive treatment of long-document retrieval (LDR), consolidating methods, challenges, and applications across three major eras. We systematize the evolution from classical lexical and early neural models to modern pre-trained (PLM) and large language models (LLMs), covering key paradigms like passage aggregation, hierarchical encoding, efficient attention, and the latest LLM-driven re-ranking and retrieval techniques. Beyond the models, we review domain-specific applications, specialized evaluation resources, and outline critical open challenges such as efficiency trade-offs, multimodal alignment, and faithfulness. This survey aims to provide both a consolidated reference and a forward-looking agenda for advancing long-document retrieval in the era of foundation models.