 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComment-aided Video-Language Alignment via Contrastive Pre-training for Short-form Video Humor Detection
Feb 14, 2024

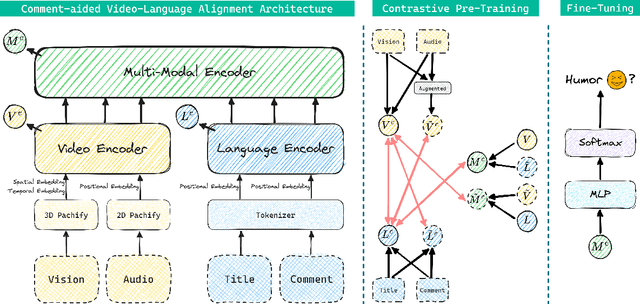

The growing importance of multi-modal humor detection within affective computing correlates with the expanding influence of short-form video sharing on social media platforms. In this paper, we propose a novel two-branch hierarchical model for short-form video humor detection (SVHD), named Comment-aided Video-Language Alignment (CVLA) via data-augmented multi-modal contrastive pre-training. Notably, our CVLA not only operates on raw signals across various modal channels but also yields an appropriate multi-modal representation by aligning the video and language components within a consistent semantic space. The experimental results on two humor detection datasets, including DY11k and UR-FUNNY, demonstrate that CVLA dramatically outperforms state-of-the-art and several competitive baseline approaches. Our dataset, code and model release at https://github.com/yliu-cs/CVLA.