 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComment-aided Video-Language Alignment via Contrastive Pre-training for Short-form Video Humor Detection
Feb 14, 2024

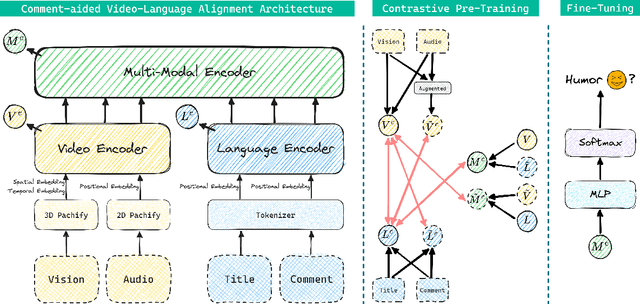

The growing importance of multi-modal humor detection within affective computing correlates with the expanding influence of short-form video sharing on social media platforms. In this paper, we propose a novel two-branch hierarchical model for short-form video humor detection (SVHD), named Comment-aided Video-Language Alignment (CVLA) via data-augmented multi-modal contrastive pre-training. Notably, our CVLA not only operates on raw signals across various modal channels but also yields an appropriate multi-modal representation by aligning the video and language components within a consistent semantic space. The experimental results on two humor detection datasets, including DY11k and UR-FUNNY, demonstrate that CVLA dramatically outperforms state-of-the-art and several competitive baseline approaches. Our dataset, code and model release at https://github.com/yliu-cs/CVLA.
Pre-trained Token-replaced Detection Model as Few-shot Learner
Mar 07, 2022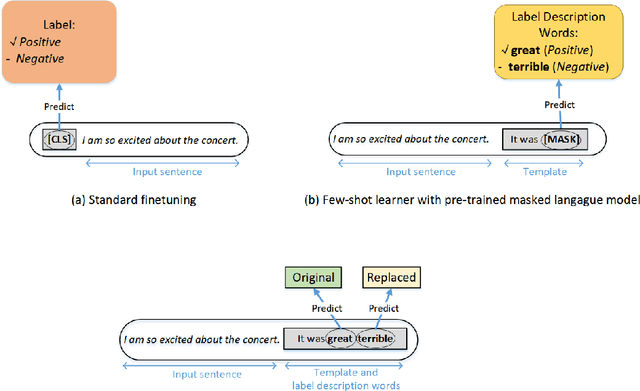
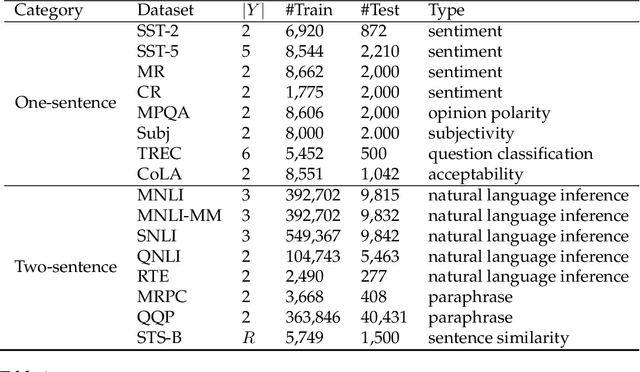
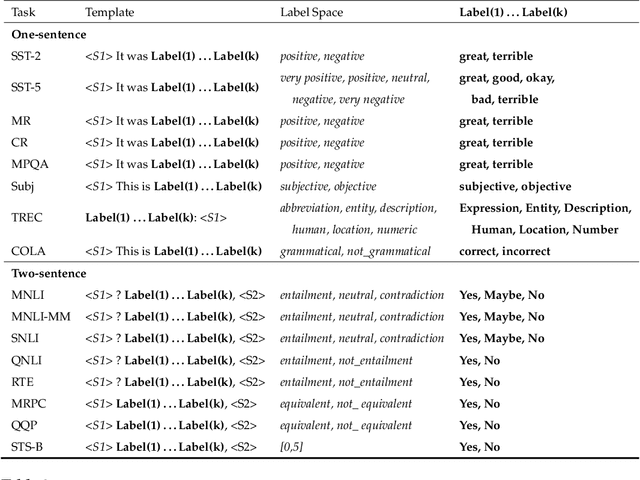

Pre-trained masked language models have demonstrated remarkable ability as few-shot learners. In this paper, as an alternative, we propose a novel approach to few-shot learning with pre-trained token-replaced detection models like ELECTRA. In this approach, we reformulate a classification or a regression task as a token-replaced detection problem. Specifically, we first define a template and label description words for each task and put them into the input to form a natural language prompt. Then, we employ the pre-trained token-replaced detection model to predict which label description word is the most original (i.e., least replaced) among all label description words in the prompt. A systematic evaluation on 16 datasets demonstrates that our approach outperforms few-shot learners with pre-trained masked language models in both one-sentence and two-sentence learning tasks.
Human-Like Decision Making: Document-level Aspect Sentiment Classification via Hierarchical Reinforcement Learning
Oct 21, 2019



Recently, neural networks have shown promising results on Document-level Aspect Sentiment Classification (DASC). However, these approaches often offer little transparency w.r.t. their inner working mechanisms and lack interpretability. In this paper, to simulating the steps of analyzing aspect sentiment in a document by human beings, we propose a new Hierarchical Reinforcement Learning (HRL) approach to DASC. This approach incorporates clause selection and word selection strategies to tackle the data noise problem in the task of DASC. First, a high-level policy is proposed to select aspect-relevant clauses and discard noisy clauses. Then, a low-level policy is proposed to select sentiment-relevant words and discard noisy words inside the selected clauses. Finally, a sentiment rating predictor is designed to provide reward signals to guide both clause and word selection. Experimental results demonstrate the impressive effectiveness of the proposed approach to DASC over the state-of-the-art baselines.
Emotion Detection with Neural Personal Discrimination
Aug 28, 2019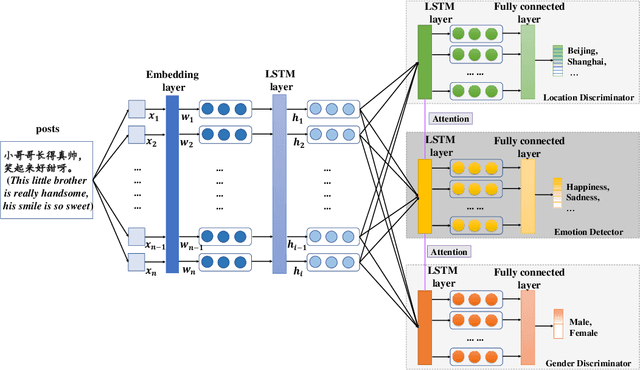
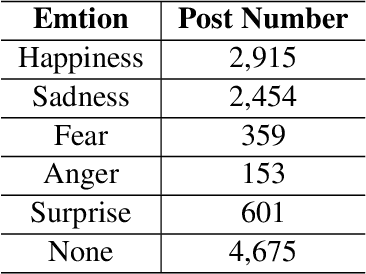
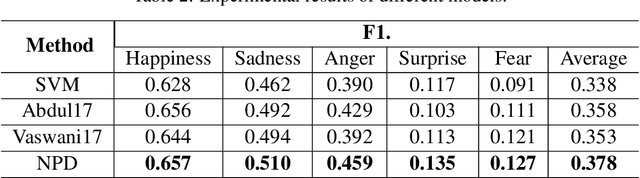
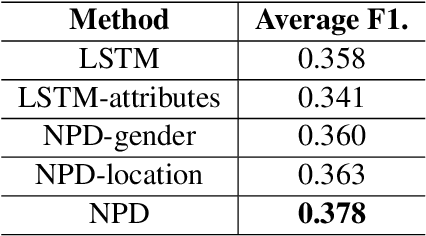
There have been a recent line of works to automatically predict the emotions of posts in social media. Existing approaches consider the posts individually and predict their emotions independently. Different from previous researches, we explore the dependence among relevant posts via the authors' backgrounds, since the authors with similar backgrounds, e.g., gender, location, tend to express similar emotions. However, such personal attributes are not easy to obtain in most social media websites, and it is hard to capture attributes-aware words to connect similar people. Accordingly, we propose a Neural Personal Discrimination (NPD) approach to address above challenges by determining personal attributes from posts, and connecting relevant posts with similar attributes to jointly learn their emotions. In particular, we employ adversarial discriminators to determine the personal attributes, with attention mechanisms to aggregate attributes-aware words. In this way, social correlationship among different posts can be better addressed. Experimental results show the usefulness of personal attributes, and the effectiveness of our proposed NPD approach in capturing such personal attributes with significant gains over the state-of-the-art models.