 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2S: Probabilistic Process Supervision for General-Domain Reasoning Question Answering
Jan 28, 2026While reinforcement learning with verifiable rewards (RLVR) has advanced LLM reasoning in structured domains like mathematics and programming, its application to general-domain reasoning tasks remains challenging due to the absence of verifiable reward signals. To this end, methods like Reinforcement Learning with Reference Probability Reward (RLPR) have emerged, leveraging the probability of generating the final answer as a reward signal. However, these outcome-focused approaches neglect crucial step-by-step supervision of the reasoning process itself. To address this gap, we introduce Probabilistic Process Supervision (P2S), a novel self-supervision framework that provides fine-grained process rewards without requiring a separate reward model or human-annotated reasoning steps. During reinforcement learning, P2S synthesizes and filters a high-quality reference reasoning chain (gold-CoT). The core of our method is to calculate a Path Faithfulness Reward (PFR) for each reasoning step, which is derived from the conditional probability of generating the gold-CoT's suffix, given the model's current reasoning prefix. Crucially, this PFR can be flexibly integrated with any outcome-based reward, directly tackling the reward sparsity problem by providing dense guidance. Extensive experiments on reading comprehension and medical Question Answering benchmarks show that P2S significantly outperforms strong baselines.
AppealCase: A Dataset and Benchmark for Civil Case Appeal Scenarios
May 22, 2025



Recent advances in LegalAI have primarily focused on individual case judgment analysis, often overlooking the critical appellate process within the judicial system. Appeals serve as a core mechanism for error correction and ensuring fair trials, making them highly significant both in practice and in research. To address this gap, we present the AppealCase dataset, consisting of 10,000 pairs of real-world, matched first-instance and second-instance documents across 91 categories of civil cases. The dataset also includes detailed annotations along five dimensions central to appellate review: judgment reversals, reversal reasons, cited legal provisions, claim-level decisions, and whether there is new information in the second instance. Based on these annotations, we propose five novel LegalAI tasks and conduct a comprehensive evaluation across 20 mainstream models. Experimental results reveal that all current models achieve less than 50% F1 scores on the judgment reversal prediction task, highlighting the complexity and challenge of the appeal scenario. We hope that the AppealCase dataset will spur further research in LegalAI for appellate case analysis and contribute to improving consistency in judicial decision-making.
Intelligent Legal Assistant: An Interactive Clarification System for Legal Question Answering
Feb 11, 2025



The rise of large language models has opened new avenues for users seeking legal advice. However, users often lack professional legal knowledge, which can lead to questions that omit critical information. This deficiency makes it challenging for traditional legal question-answering systems to accurately identify users' actual needs, often resulting in imprecise or generalized advice. In this work, we develop a legal question-answering system called Intelligent Legal Assistant, which interacts with users to precisely capture their needs. When a user poses a question, the system requests that the user select their geographical location to pinpoint the applicable laws. It then generates clarifying questions and options based on the key information missing from the user's initial question. This allows the user to select and provide the necessary details. Once all necessary information is provided, the system produces an in-depth legal analysis encompassing three aspects: overall conclusion, jurisprudential analysis, and resolution suggestions.
LangGFM: A Large Language Model Alone Can be a Powerful Graph Foundation Model
Oct 19, 2024
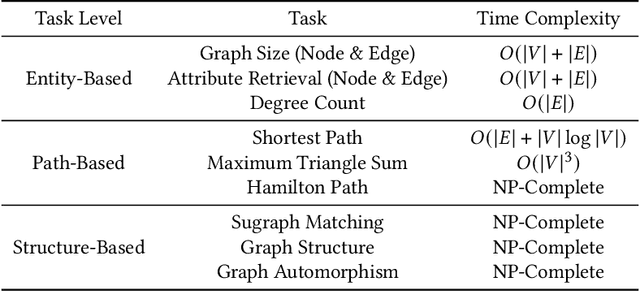

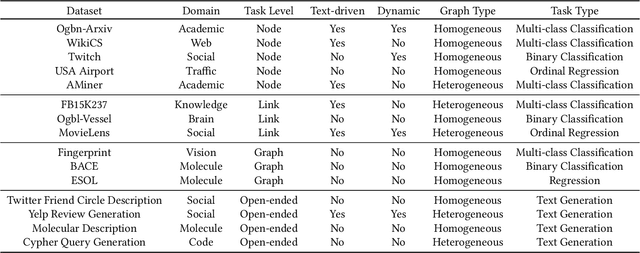
Graph foundation models (GFMs) have recently gained significant attention. However, the unique data processing and evaluation setups employed by different studies hinder a deeper understanding of their progress. Additionally, current research tends to focus on specific subsets of graph learning tasks, such as structural tasks, node-level tasks, or classification tasks. As a result, they often incorporate specialized modules tailored to particular task types, losing their applicability to other graph learning tasks and contradicting the original intent of foundation models to be universal. Therefore, to enhance consistency, coverage, and diversity across domains, tasks, and research interests within the graph learning community in the evaluation of GFMs, we propose GFMBench-a systematic and comprehensive benchmark comprising 26 datasets. Moreover, we introduce LangGFM, a novel GFM that relies entirely on large language models. By revisiting and exploring the effective graph textualization principles, as well as repurposing successful techniques from graph augmentation and graph self-supervised learning within the language space, LangGFM achieves performance on par with or exceeding the state of the art across GFMBench, which can offer us new perspectives, experiences, and baselines to drive forward the evolution of GFMs.
A Speaker Turn-Aware Multi-Task Adversarial Network for Joint User Satisfaction Estimation and Sentiment Analysis
Oct 12, 2024



User Satisfaction Estimation is an important task and increasingly being applied in goal-oriented dialogue systems to estimate whether the user is satisfied with the service. It is observed that whether the user's needs are met often triggers various sentiments, which can be pertinent to the successful estimation of user satisfaction, and vice versa. Thus, User Satisfaction Estimation (USE) and Sentiment Analysis (SA) should be treated as a joint, collaborative effort, considering the strong connections between the sentiment states of speakers and the user satisfaction. Existing joint learning frameworks mainly unify the two highly pertinent tasks over cascade or shared-bottom implementations, however they fail to distinguish task-specific and common features, which will produce sub-optimal utterance representations for downstream tasks. In this paper, we propose a novel Speaker Turn-Aware Multi-Task Adversarial Network (STMAN) for dialogue-level USE and utterance-level SA. Specifically, we first introduce a multi-task adversarial strategy which trains a task discriminator to make utterance representation more task-specific, and then utilize a speaker-turn aware multi-task interaction strategy to extract the common features which are complementary to each task. Extensive experiments conducted on two real-world service dialogue datasets show that our model outperforms several state-of-the-art methods.
Can Large Language Models Grasp Legal Theories? Enhance Legal Reasoning with Insights from Multi-Agent Collaboration
Oct 03, 2024
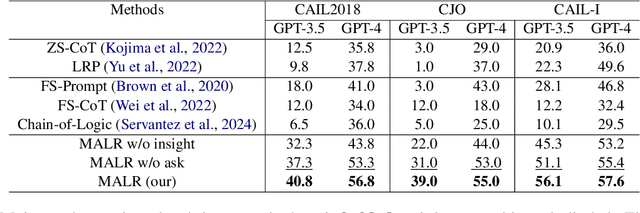

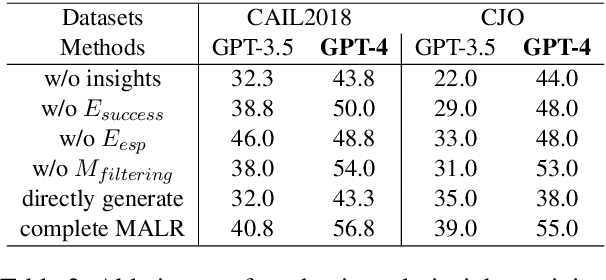
Large Language Models (LLMs) could struggle to fully understand legal theories and perform complex legal reasoning tasks. In this study, we introduce a challenging task (confusing charge prediction) to better evaluate LLMs' understanding of legal theories and reasoning capabilities. We also propose a novel framework: Multi-Agent framework for improving complex Legal Reasoning capability (MALR). MALR employs non-parametric learning, encouraging LLMs to automatically decompose complex legal tasks and mimic human learning process to extract insights from legal rules, helping LLMs better understand legal theories and enhance their legal reasoning abilities. Extensive experiments on multiple real-world datasets demonstrate that the proposed framework effectively addresses complex reasoning issues in practical scenarios, paving the way for more reliable applications in the legal domain.
Gold Panning in Vocabulary: An Adaptive Method for Vocabulary Expansion of Domain-Specific LLMs
Oct 02, 2024



While Large Language Models (LLMs) demonstrate impressive generation abilities, they frequently struggle when it comes to specialized domains due to their limited domain-specific knowledge. Studies on domain-specific LLMs resort to expanding the vocabulary before fine-tuning on domain-specific corpus, aiming to decrease the sequence length and enhance efficiency during decoding, without thoroughly investigating the results of vocabulary expansion to LLMs over different domains. Our pilot study reveals that expansion with only a subset of the entire vocabulary may lead to superior performance. Guided by the discovery, this paper explores how to identify a vocabulary subset to achieve the optimal results. We introduce VEGAD, an adaptive method that automatically identifies valuable words from a given domain vocabulary. Our method has been validated through experiments on three Chinese datasets, demonstrating its effectiveness. Additionally, we have undertaken comprehensive analyses of the method. The selection of a optimal subset for expansion has shown to enhance performance on both domain-specific tasks and general tasks, showcasing the potential of VEGAD.
RexUniNLU: Recursive Method with Explicit Schema Instructor for Universal NLU
Sep 09, 2024
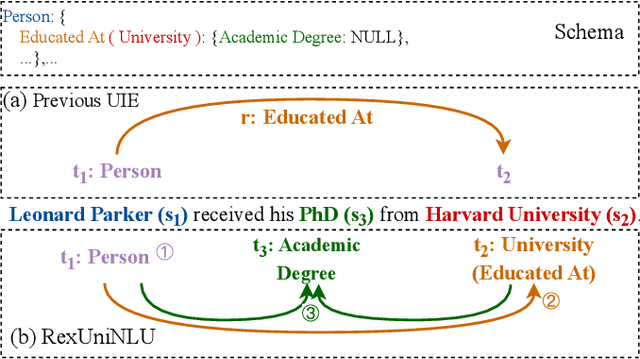
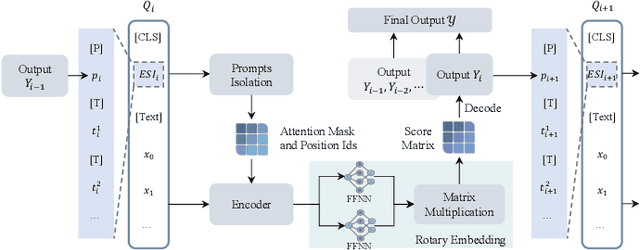
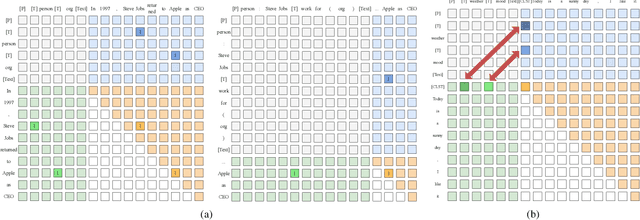
Information Extraction (IE) and Text Classification (CLS) serve as the fundamental pillars of NLU, with both disciplines relying on analyzing input sequences to categorize outputs into pre-established schemas. However, there is no existing encoder-based model that can unify IE and CLS tasks from this perspective. To fully explore the foundation shared within NLU tasks, we have proposed a Recursive Method with Explicit Schema Instructor for Universal NLU. Specifically, we firstly redefine the true universal information extraction (UIE) with a formal formulation that covers almost all extraction schemas, including quadruples and quintuples which remain unsolved for previous UIE models. Then, we expands the formulation to all CLS and multi-modal NLU tasks. Based on that, we introduce RexUniNLU, an universal NLU solution that employs explicit schema constraints for IE and CLS, which encompasses all IE and CLS tasks and prevent incorrect connections between schema and input sequence. To avoid interference between different schemas, we reset the position ids and attention mask matrices. Extensive experiments are conducted on IE, CLS in both English and Chinese, and multi-modality, revealing the effectiveness and superiority. Our codes are publicly released.
More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs
May 28, 2024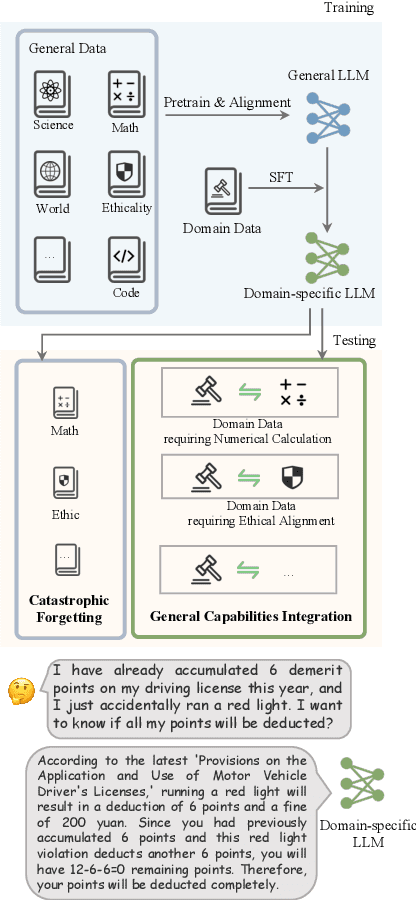


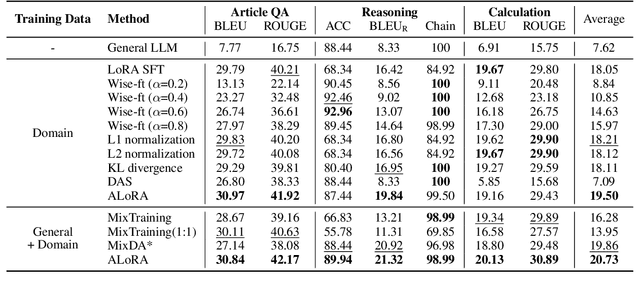
The performance on general tasks decreases after Large Language Models (LLMs) are fine-tuned on domain-specific tasks, the phenomenon is known as Catastrophic Forgetting (CF). However, this paper presents a further challenge for real application of domain-specific LLMs beyond CF, called General Capabilities Integration (GCI), which necessitates the integration of both the general capabilities and domain knowledge within a single instance. The objective of GCI is not merely to retain previously acquired general capabilities alongside new domain knowledge, but to harmonize and utilize both sets of skills in a cohesive manner to enhance performance on domain-specific tasks. Taking legal domain as an example, we carefully design three groups of training and testing tasks without lacking practicability, and construct the corresponding datasets. To better incorporate general capabilities across domain-specific scenarios, we introduce ALoRA, which utilizes a multi-head attention module upon LoRA, facilitating direct information transfer from preceding tokens to the current one. This enhancement permits the representation to dynamically switch between domain-specific knowledge and general competencies according to the attention. Extensive experiments are conducted on the proposed tasks. The results exhibit the significance of our setting, and the effectiveness of our method.
Enhance Robustness of Language Models Against Variation Attack through Graph Integration
Apr 18, 2024



The widespread use of pre-trained language models (PLMs) in natural language processing (NLP) has greatly improved performance outcomes. However, these models' vulnerability to adversarial attacks (e.g., camouflaged hints from drug dealers), particularly in the Chinese language with its rich character diversity/variation and complex structures, hatches vital apprehension. In this study, we propose a novel method, CHinese vAriatioN Graph Enhancement (CHANGE), to increase the robustness of PLMs against character variation attacks in Chinese content. CHANGE presents a novel approach for incorporating a Chinese character variation graph into the PLMs. Through designing different supplementary tasks utilizing the graph structure, CHANGE essentially enhances PLMs' interpretation of adversarially manipulated text. Experiments conducted in a multitude of NLP tasks show that CHANGE outperforms current language models in combating against adversarial attacks and serves as a valuable contribution to robust language model research. These findings contribute to the groundwork on robust language models and highlight the substantial potential of graph-guided pre-training strategies for real-world applications.