 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Local vs. External: A Game-Theoretic Framework for Trustworthy Knowledge Acquisition
Apr 25, 2026Cloud-hosted Large Language Models (LLMs) offer unmatched reasoning capabilities and dynamic knowledge, yet submitting raw queries to these external services risks exposing sensitive user intent. Conversely, relying exclusively on trusted local models preserves privacy but often compromises answer quality due to limited parameter scale and knowledge. To resolve this dilemma, we propose Game-theoretic Trustworthy Knowledge Acquisition (GTKA), a framework that formulates the trade-off between knowledge utility and privacy as a strategic game. GTKA consists of three components: (i) a privacy-aware sub-query generator that decomposes sensitive intent into generalized, low-risk fragments; (ii) an adversarial reconstruction attacker that attempts to infer the original query from these fragments, providing adaptive leakage signals; and (iii) a trusted local integrator that synthesizes external responses within a secure boundary. By training the generator and attacker in an alternating adversarial manner, GTKA optimizes the sub-query generation policy to maximize knowledge acquisition accuracy while minimizing the reconstructability of the original sensitive intent. To validate our approach, we construct two sensitive-domain benchmarks in the biomedical and legal fields. Extensive experiments demonstrate that GTKA significantly reduces intent leakage compared to state-of-the-art baselines while maintaining high-fidelity answer quality.
Teaching According to Students' Aptitude: Personalized Mathematics Tutoring via Persona-, Memory-, and Forgetting-Aware LLMs
Nov 19, 2025Large Language Models (LLMs) are increasingly integrated into intelligent tutoring systems to provide human-like and adaptive instruction. However, most existing approaches fail to capture how students' knowledge evolves dynamically across their proficiencies, conceptual gaps, and forgetting patterns. This challenge is particularly acute in mathematics tutoring, where effective instruction requires fine-grained scaffolding precisely calibrated to each student's mastery level and cognitive retention. To address this issue, we propose TASA (Teaching According to Students' Aptitude), a student-aware tutoring framework that integrates persona, memory, and forgetting dynamics for personalized mathematics learning. Specifically, TASA maintains a structured student persona capturing proficiency profiles and an event memory recording prior learning interactions. By incorporating a continuous forgetting curve with knowledge tracing, TASA dynamically updates each student's mastery state and generates contextually appropriate, difficulty-calibrated questions and explanations. Empirical results demonstrate that TASA achieves superior learning outcomes and more adaptive tutoring behavior compared to representative baselines, underscoring the importance of modeling temporal forgetting and learner profiles in LLM-based tutoring systems.
Active Domain Knowledge Acquisition with \$100 Budget: Enhancing LLMs via Cost-Efficient, Expert-Involved Interaction in Sensitive Domains
Aug 24, 2025Large Language Models (LLMs) have demonstrated an impressive level of general knowledge. However, they often struggle in highly specialized and cost-sensitive domains such as drug discovery and rare disease research due to the lack of expert knowledge. In this paper, we propose a novel framework (PU-ADKA) designed to efficiently enhance domain-specific LLMs by actively engaging domain experts within a fixed budget. Unlike traditional fine-tuning approaches, PU-ADKA selectively identifies and queries the most appropriate expert from a team, taking into account each expert's availability, knowledge boundaries, and consultation costs. We train PU-ADKA using simulations on PubMed data and validate it through both controlled expert interactions and real-world deployment with a drug development team, demonstrating its effectiveness in enhancing LLM performance in specialized domains under strict budget constraints. In addition to outlining our methodological innovations and experimental results, we introduce a new benchmark dataset, CKAD, for cost-effective LLM domain knowledge acquisition to foster further research in this challenging area.
Elevating Legal LLM Responses: Harnessing Trainable Logical Structures and Semantic Knowledge with Legal Reasoning
Feb 11, 2025
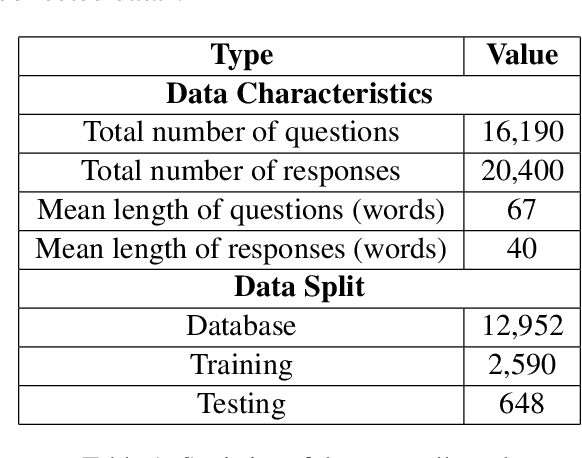
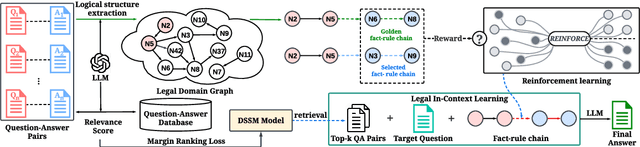
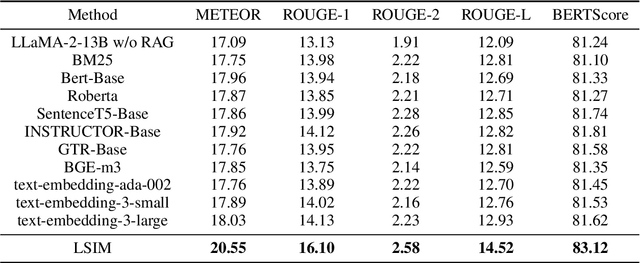
Large Language Models (LLMs) have achieved impressive results across numerous domains, yet they experience notable deficiencies in legal question-answering tasks. LLMs often generate generalized responses that lack the logical specificity required for expert legal advice and are prone to hallucination, providing answers that appear correct but are unreliable. Retrieval-Augmented Generation (RAG) techniques offer partial solutions to address this challenge, but existing approaches typically focus only on semantic similarity, neglecting the logical structure essential to legal reasoning. In this paper, we propose the Logical-Semantic Integration Model (LSIM), a novel supervised framework that bridges semantic and logical coherence. LSIM comprises three components: reinforcement learning predicts a structured fact-rule chain for each question, a trainable Deep Structured Semantic Model (DSSM) retrieves the most relevant candidate questions by integrating semantic and logical features, and in-context learning generates the final answer using the retrieved content. Our experiments on a real-world legal QA dataset-validated through both automated metrics and human evaluation-demonstrate that LSIM significantly enhances accuracy and reliability compared to existing methods.
Intelligent Legal Assistant: An Interactive Clarification System for Legal Question Answering
Feb 11, 2025



The rise of large language models has opened new avenues for users seeking legal advice. However, users often lack professional legal knowledge, which can lead to questions that omit critical information. This deficiency makes it challenging for traditional legal question-answering systems to accurately identify users' actual needs, often resulting in imprecise or generalized advice. In this work, we develop a legal question-answering system called Intelligent Legal Assistant, which interacts with users to precisely capture their needs. When a user poses a question, the system requests that the user select their geographical location to pinpoint the applicable laws. It then generates clarifying questions and options based on the key information missing from the user's initial question. This allows the user to select and provide the necessary details. Once all necessary information is provided, the system produces an in-depth legal analysis encompassing three aspects: overall conclusion, jurisprudential analysis, and resolution suggestions.
Data Optimization in Deep Learning: A Survey
Oct 25, 2023Large-scale, high-quality data are considered an essential factor for the successful application of many deep learning techniques. Meanwhile, numerous real-world deep learning tasks still have to contend with the lack of sufficient amounts of high-quality data. Additionally, issues such as model robustness, fairness, and trustworthiness are also closely related to training data. Consequently, a huge number of studies in the existing literature have focused on the data aspect in deep learning tasks. Some typical data optimization techniques include data augmentation, logit perturbation, sample weighting, and data condensation. These techniques usually come from different deep learning divisions and their theoretical inspirations or heuristic motivations may seem unrelated to each other. This study aims to organize a wide range of existing data optimization methodologies for deep learning from the previous literature, and makes the effort to construct a comprehensive taxonomy for them. The constructed taxonomy considers the diversity of split dimensions, and deep sub-taxonomies are constructed for each dimension. On the basis of the taxonomy, connections among the extensive data optimization methods for deep learning are built in terms of four aspects. We probe into rendering several promising and interesting future directions. The constructed taxonomy and the revealed connections will enlighten the better understanding of existing methods and the design of novel data optimization techniques. Furthermore, our aspiration for this survey is to promote data optimization as an independent subdivision of deep learning. A curated, up-to-date list of resources related to data optimization in deep learning is available at \url{https://github.com/YaoRujing/Data-Optimization}.
Compensation Learning
Jul 26, 2021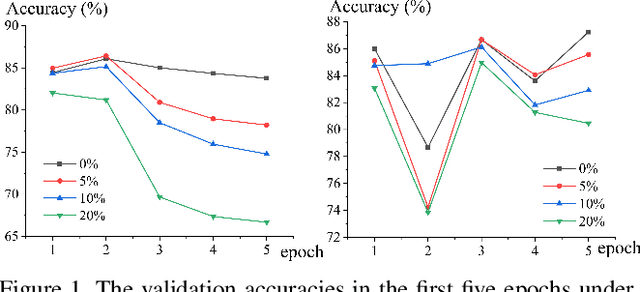
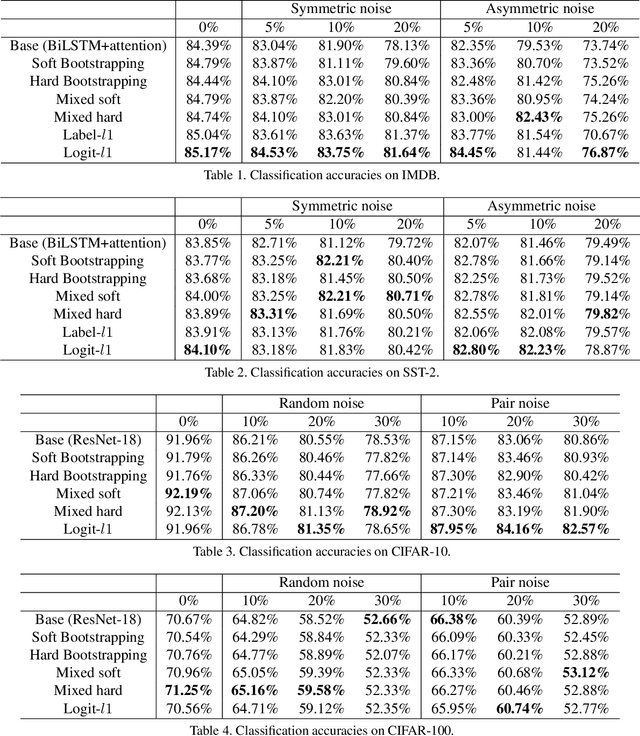
Weighting strategy prevails in machine learning. For example, a common approach in robust machine learning is to exert lower weights on samples which are likely to be noisy or hard. This study reveals another undiscovered strategy, namely, compensating, that has also been widely used in machine learning. Learning with compensating is called compensation learning and a systematic taxonomy is constructed for it in this study. In our taxonomy, compensation learning is divided on the basis of the compensation targets, inference manners, and granularity levels. Many existing learning algorithms including some classical ones can be seen as a special case of compensation learning or partially leveraging compensating. Furthermore, a family of new learning algorithms can be obtained by plugging the compensation learning into existing learning algorithms. Specifically, three concrete new learning algorithms are proposed for robust machine learning. Extensive experiments on text sentiment analysis, image classification, and graph classification verify the effectiveness of the three new algorithms. Compensation learning can also be used in various learning scenarios, such as imbalance learning, clustering, regression, and so on.
AI Marker-based Large-scale AI Literature Mining
Nov 03, 2020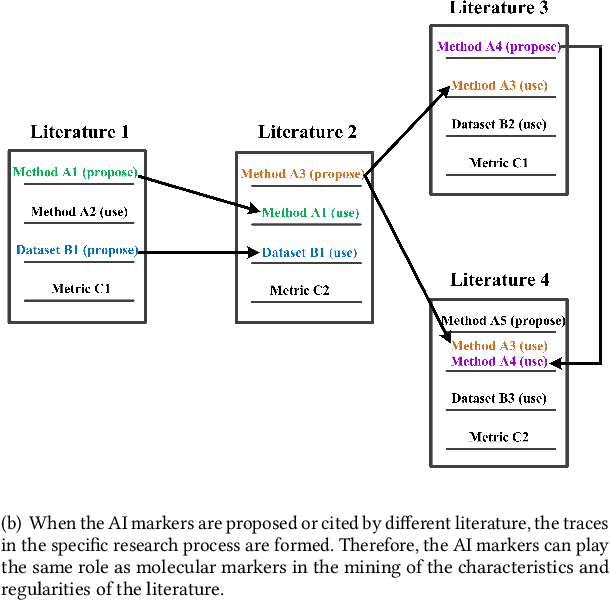

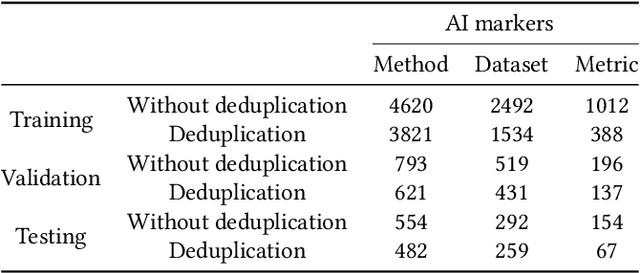
The knowledge contained in academic literature is interesting to mine. Inspired by the idea of molecular markers tracing in the field of biochemistry, three named entities, namely, methods, datasets and metrics are used as AI markers for AI literature. These entities can be used to trace the research process described in the bodies of papers, which opens up new perspectives for seeking and mining more valuable academic information. Firstly, the entity extraction model is used in this study to extract AI markers from large-scale AI literature. Secondly, original papers are traced for AI markers. Statistical and propagation analysis are performed based on tracing results. Finally, the co-occurrences of AI markers are used to achieve clustering. The evolution within method clusters and the influencing relationships amongst different research scene clusters are explored. The above-mentioned mining based on AI markers yields many meaningful discoveries. For example, the propagation of effective methods on the datasets is rapidly increasing with the development of time; effective methods proposed by China in recent years have increasing influence on other countries, whilst France is the opposite. Saliency detection, a classic computer vision research scene, is the least likely to be affected by other research scenes.
Method and Dataset Entity Mining in Scientific Literature: A CNN + Bi-LSTM Model with Self-attention
Oct 26, 2020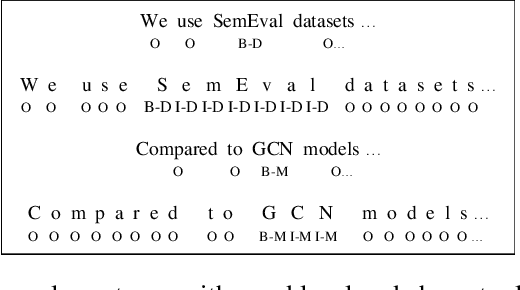
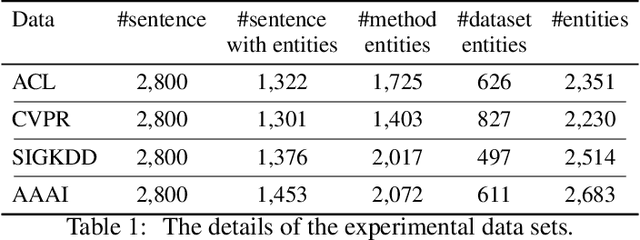
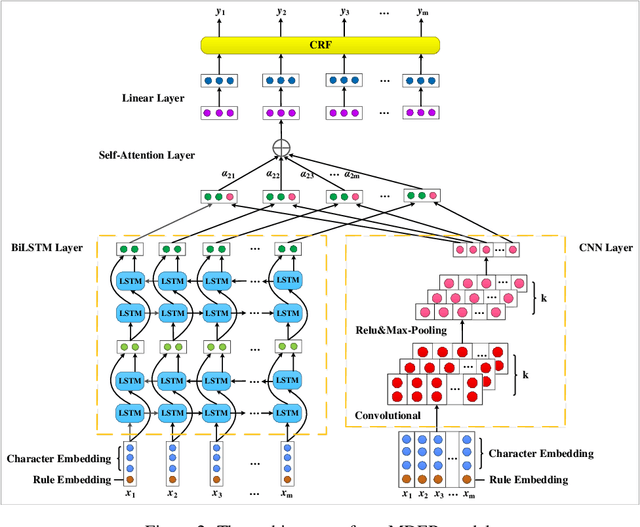
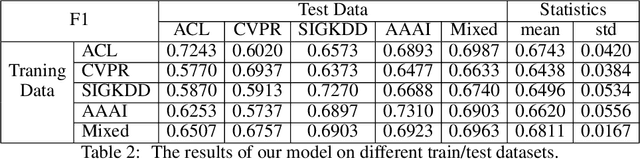
Literature analysis facilitates researchers to acquire a good understanding of the development of science and technology. The traditional literature analysis focuses largely on the literature metadata such as topics, authors, abstracts, keywords, references, etc., and little attention was paid to the main content of papers. In many scientific domains such as science, computing, engineering, etc., the methods and datasets involved in the scientific papers published in those domains carry important information and are quite useful for domain analysis as well as algorithm and dataset recommendation. In this paper, we propose a novel entity recognition model, called MDER, which is able to effectively extract the method and dataset entities from the main textual content of scientific papers. The model utilizes rule embedding and adopts a parallel structure of CNN and Bi-LSTM with the self-attention mechanism. We evaluate the proposed model on datasets which are constructed from the published papers of four research areas in computer science, i.e., NLP, CV, Data Mining and AI. The experimental results demonstrate that our model performs well in all the four areas and it features a good learning capacity for cross-area learning and recognition. We also conduct experiments to evaluate the effectiveness of different building modules within our model which indicate that the importance of different building modules in collectively contributing to the good entity recognition performance as a whole. The data augmentation experiments on our model demonstrated that data augmentation positively contributes to model training, making our model much more robust in dealing with the scenarios where only small number of training samples are available. We finally apply our model on PAKDD papers published from 2009-2019 to mine insightful results from scientific papers published in a longer time span.
Method and Dataset Mining in Scientific Papers
Nov 29, 2019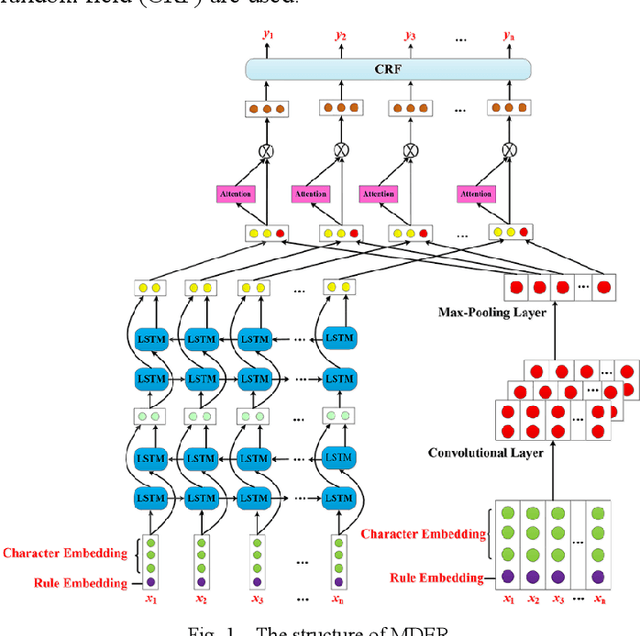
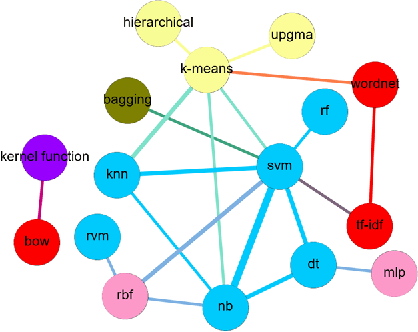
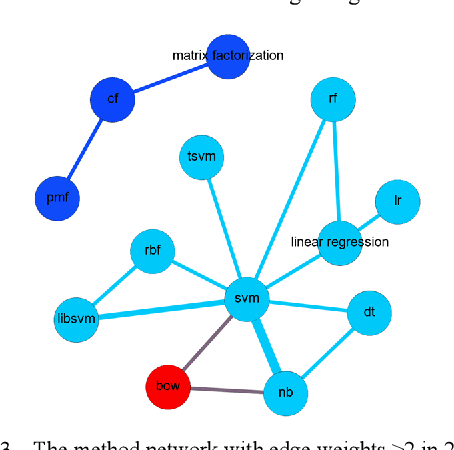
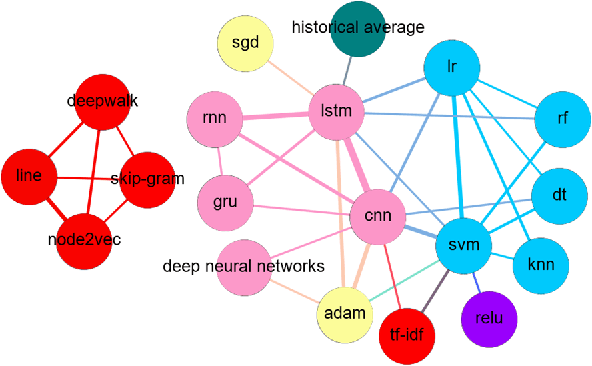
Literature analysis facilitates researchers better understanding the development of science and technology. The conventional literature analysis focuses on the topics, authors, abstracts, keywords, references, etc., and rarely pays attention to the content of papers. In the field of machine learning, the involved methods (M) and datasets (D) are key information in papers. The extraction and mining of M and D are useful for discipline analysis and algorithm recommendation. In this paper, we propose a novel entity recognition model, called MDER, and constructe datasets from the papers of the PAKDD conferences (2009-2019). Some preliminary experiments are conducted to assess the extraction performance and the mining results are visualized.