Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethod and Dataset Mining in Scientific Papers
Paper and Code
Nov 29, 2019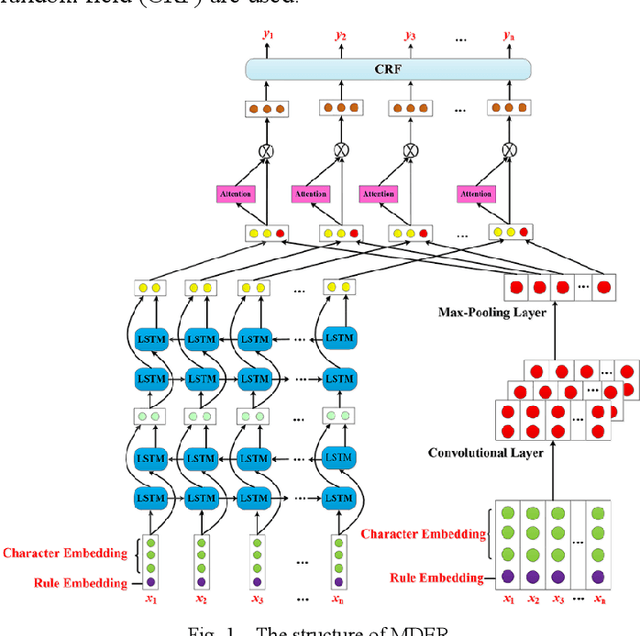
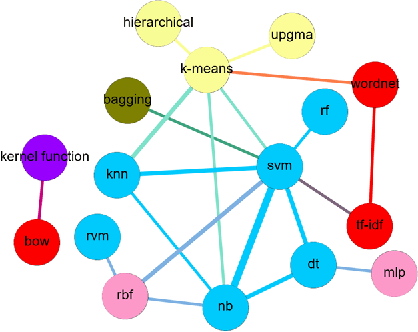
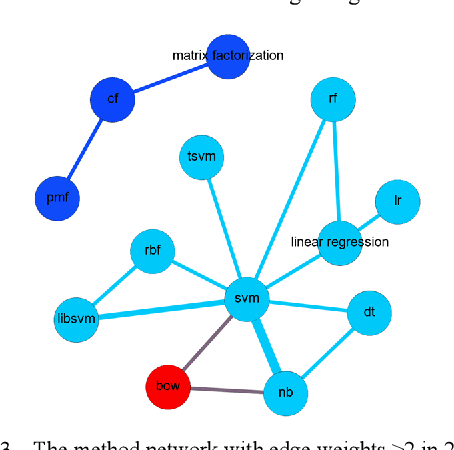
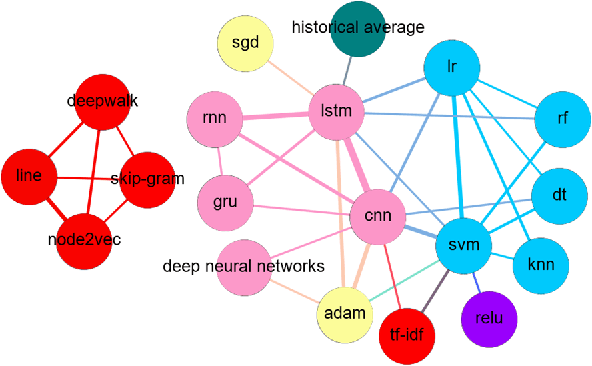
Literature analysis facilitates researchers better understanding the development of science and technology. The conventional literature analysis focuses on the topics, authors, abstracts, keywords, references, etc., and rarely pays attention to the content of papers. In the field of machine learning, the involved methods (M) and datasets (D) are key information in papers. The extraction and mining of M and D are useful for discipline analysis and algorithm recommendation. In this paper, we propose a novel entity recognition model, called MDER, and constructe datasets from the papers of the PAKDD conferences (2009-2019). Some preliminary experiments are conducted to assess the extraction performance and the mining results are visualized.
View paper on