 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Ripple Effects in Knowledge Editing through Pressure-Aware Joint Neighborhood Optimization
Jun 01, 2026Single-edit updates in large language models can trigger ripple effects across local knowledge neighborhoods: desirable propagation to related facts and unintended perturbation of preserved ones. Existing methods address these two effects separately, without explicitly modeling their coupling. We challenge this separation through an analysis of ripple responses across typical baselines, identifying two coupled design pressures: editable-side coordination and preserved-side leakage. We propose Joint Neighborhood Optimization (JNO), a new knowledge-editing framework to formalize and jointly address both pressures at the target-planning stage. JNO instantiates this principle through Pressure-Aware Coordination (PAC), which jointly optimizes neighborhood target representations under coupled constraints, and a semantic pre-execution gate that rejects high-risk target plans before parameter execution. Experiments on RippleEdits show JNO improves propagation and preservation metrics by at least 7.0% while preserving cross-backbone editing stability.
AlphaToken: Decoupling Adaptation and Stability for Path-Aware Response Token Valuation in LLM Post-Training
Jun 01, 2026Token selection is pivotal for effective LLM post-training. However, existing methods mostly rely on local heuristics and rarely formulate token selection as a principled valuation of individual response tokens. We introduce $\textbf{AlphaToken}$, a response token valuation framework that decouples valuation into $\textbf{adaptation}$ (promoting target-task learning) and $\textbf{stability}$ (preserving pre-trained capabilities), and makes each objective $\textbf{path-aware}$ by combining the direct-path signal from local token gradients with the downstream causal-path signal in autoregressive generation. Since retention data are typically unavailable, AlphaToken approximates stability via a $\textbf{Fisher-drift proxy}$ anchored at the pre-trained reference model. For efficient computation, we extend Ghost Dot-Product to token-level valuation. AlphaToken masks low-value response tokens during fine-tuning and preference optimization, concentrating training signals on more valuable positions. Experiments show that AlphaToken improves post-training performance and mitigates catastrophic forgetting.
One Algorithm, Two Goals: Dual Scoring for Parameter and Data Selection in LLM Fine-Tuning
May 07, 2026In Large Language Model (LLM) fine-tuning, parameter and data selection are common strategies for reducing fine-tuning cost, yet they are typically driven by separate scoring mechanisms. When a parameter mask and data subset jointly determine restricted fine-tuning, this separation incurs redundant overhead and makes coordinated selection difficult. We cast parameter and data selection as two bilevel selection problems under a common validation objective and derive a shared local response-surrogate scoring rule. Under first- and second-order validation-improvement approximations, parameter importance and data utility emerge as column-wise and row-wise aggregations of a single gradient interaction matrix, yielding a closed-form row-column correspondence for co-extracting both signals. Building on this structure, we propose DualSFT (Dual-Selection Fine-Tuning), a one-shot dual-scoring algorithm that produces a parameter mask and data subset from shared gradient statistics. On 3B-9B LLMs, single-axis DualSFT variants strengthen target-task performance and stability-plasticity trade-offs within their comparison groups, while full DualSFT yields a more favorable joint-constrained trade-off than sequential hybrid baselines under matched budgets.
MetaKE: Meta-learning Aligned Knowledge Editing via Bi-level Optimization
Mar 16, 2026Knowledge editing (KE) aims to precisely rectify specific knowledge in Large Language Models (LLMs) without disrupting general capabilities. State-of-the-art methods suffer from an open-loop control mismatch. We identify a critical "Semantic-Execution Disconnect": the semantic target is derived independently without feedback from the downstream's feasible region. This misalignment often causes valid semantic targets to fall within the prohibited space, resulting in gradient truncation and editing failure. To bridge this gap, we propose MetaKE (Meta-learning Aligned Knowledge Editing), a new framework that reframes KE as a bi-level optimization problem. Departing from static calculation, MetaKE treats the edit target as a learnable meta-parameter: the upper-level optimizer seeks a feasible target to maximize post-edit performance, while the lower-level solver executes the editing. To address the challenge of differentiating through complex solvers, we derive a Structural Gradient Proxy, which explicitly backpropagates editability constraints to the target learning phase. Theoretical analysis demonstrates that MetaKE automatically aligns the edit direction with the model's feasible manifold. Extensive experiments confirm that MetaKE significantly outperforms strong baselines, offering a new perspective on knowledge editing.
Data Poisoning in Deep Learning: A Survey
Mar 27, 2025



Deep learning has become a cornerstone of modern artificial intelligence, enabling transformative applications across a wide range of domains. As the core element of deep learning, the quality and security of training data critically influence model performance and reliability. However, during the training process, deep learning models face the significant threat of data poisoning, where attackers introduce maliciously manipulated training data to degrade model accuracy or lead to anomalous behavior. While existing surveys provide valuable insights into data poisoning, they generally adopt a broad perspective, encompassing both attacks and defenses, but lack a dedicated, in-depth analysis of poisoning attacks specifically in deep learning. In this survey, we bridge this gap by presenting a comprehensive and targeted review of data poisoning in deep learning. First, this survey categorizes data poisoning attacks across multiple perspectives, providing an in-depth analysis of their characteristics and underlying design princinples. Second, the discussion is extended to the emerging area of data poisoning in large language models(LLMs). Finally, we explore critical open challenges in the field and propose potential research directions to advance the field further. To support further exploration, an up-to-date repository of resources on data poisoning in deep learning is available at https://github.com/Pinlong-Zhao/Data-Poisoning.
Is Data Valuation Learnable and Interpretable?
Jun 03, 2024Measuring the value of individual samples is critical for many data-driven tasks, e.g., the training of a deep learning model. Recent literature witnesses the substantial efforts in developing data valuation methods. The primary data valuation methodology is based on the Shapley value from game theory, and various methods are proposed along this path. {Even though Shapley value-based valuation has solid theoretical basis, it is entirely an experiment-based approach and no valuation model has been constructed so far.} In addition, current data valuation methods ignore the interpretability of the output values, despite an interptable data valuation method is of great helpful for applications such as data pricing. This study aims to answer an important question: is data valuation learnable and interpretable? A learned valuation model have several desirable merits such as fixed number of parameters and knowledge reusability. An intrepretable data valuation model can explain why a sample is valuable or invaluable. To this end, two new data value modeling frameworks are proposed, in which a multi-layer perception~(MLP) and a new regression tree are utilized as specific base models for model training and interpretability, respectively. Extensive experiments are conducted on benchmark datasets. {The experimental results provide a positive answer for the question.} Our study opens up a new technical path for the assessing of data values. Large data valuation models can be built across many different data-driven tasks, which can promote the widespread application of data valuation.
Data Valuation by Leveraging Global and Local Statistical Information
May 23, 2024Data valuation has garnered increasing attention in recent years, given the critical role of high-quality data in various applications, particularly in machine learning tasks. There are diverse technical avenues to quantify the value of data within a corpus. While Shapley value-based methods are among the most widely used techniques in the literature due to their solid theoretical foundation, the accurate calculation of Shapley values is often intractable, leading to the proposal of numerous approximated calculation methods. Despite significant progress, nearly all existing methods overlook the utilization of distribution information of values within a data corpus. In this paper, we demonstrate that both global and local statistical information of value distributions hold significant potential for data valuation within the context of machine learning. Firstly, we explore the characteristics of both global and local value distributions across several simulated and real data corpora. Useful observations and clues are obtained. Secondly, we propose a new data valuation method that estimates Shapley values by incorporating the explored distribution characteristics into an existing method, AME. Thirdly, we present a new path to address the dynamic data valuation problem by formulating an optimization problem that integrates information of both global and local value distributions. Extensive experiments are conducted on Shapley value estimation, value-based data removal/adding, mislabeled data detection, and incremental/decremental data valuation. The results showcase the effectiveness and efficiency of our proposed methodologies, affirming the significant potential of global and local value distributions in data valuation.
Data Optimization in Deep Learning: A Survey
Oct 25, 2023Large-scale, high-quality data are considered an essential factor for the successful application of many deep learning techniques. Meanwhile, numerous real-world deep learning tasks still have to contend with the lack of sufficient amounts of high-quality data. Additionally, issues such as model robustness, fairness, and trustworthiness are also closely related to training data. Consequently, a huge number of studies in the existing literature have focused on the data aspect in deep learning tasks. Some typical data optimization techniques include data augmentation, logit perturbation, sample weighting, and data condensation. These techniques usually come from different deep learning divisions and their theoretical inspirations or heuristic motivations may seem unrelated to each other. This study aims to organize a wide range of existing data optimization methodologies for deep learning from the previous literature, and makes the effort to construct a comprehensive taxonomy for them. The constructed taxonomy considers the diversity of split dimensions, and deep sub-taxonomies are constructed for each dimension. On the basis of the taxonomy, connections among the extensive data optimization methods for deep learning are built in terms of four aspects. We probe into rendering several promising and interesting future directions. The constructed taxonomy and the revealed connections will enlighten the better understanding of existing methods and the design of novel data optimization techniques. Furthermore, our aspiration for this survey is to promote data optimization as an independent subdivision of deep learning. A curated, up-to-date list of resources related to data optimization in deep learning is available at \url{https://github.com/YaoRujing/Data-Optimization}.
Rethinking Class Imbalance in Machine Learning
May 06, 2023Imbalance learning is a subfield of machine learning that focuses on learning tasks in the presence of class imbalance. Nearly all existing studies refer to class imbalance as a proportion imbalance, where the proportion of training samples in each class is not balanced. The ignorance of the proportion imbalance will result in unfairness between/among classes and poor generalization capability. Previous literature has presented numerous methods for either theoretical/empirical analysis or new methods for imbalance learning. This study presents a new taxonomy of class imbalance in machine learning with a broader scope. Four other types of imbalance, namely, variance, distance, neighborhood, and quality imbalances between/among classes, which may exist in machine learning tasks, are summarized. Two different levels of imbalance including global and local are also presented. Theoretical analysis is used to illustrate the significant impact of the new imbalance types on learning fairness. Moreover, our taxonomy and theoretical conclusions are used to analyze the shortcomings of several classical methods. As an example, we propose a new logit perturbation-based imbalance learning loss when proportion, variance, and distance imbalances exist simultaneously. Several classical losses become the special case of our proposed method. Meta learning is utilized to infer the hyper-parameters related to the three types of imbalance. Experimental results on several benchmark corpora validate the effectiveness of the proposed method.
Implicit Counterfactual Data Augmentation for Deep Neural Networks
Apr 26, 2023


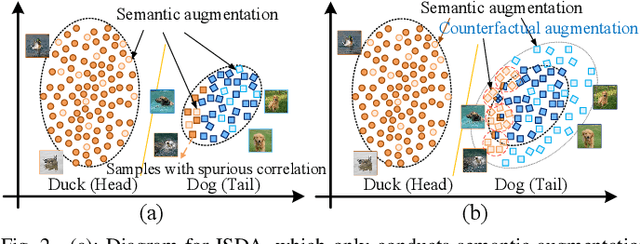
Machine-learning models are prone to capturing the spurious correlations between non-causal attributes and classes, with counterfactual data augmentation being a promising direction for breaking these spurious associations. However, explicitly generating counterfactual data is challenging, with the training efficiency declining. Therefore, this study proposes an implicit counterfactual data augmentation (ICDA) method to remove spurious correlations and make stable predictions. Specifically, first, a novel sample-wise augmentation strategy is developed that generates semantically and counterfactually meaningful deep features with distinct augmentation strength for each sample. Second, we derive an easy-to-compute surrogate loss on the augmented feature set when the number of augmented samples becomes infinite. Third, two concrete schemes are proposed, including direct quantification and meta-learning, to derive the key parameters for the robust loss. In addition, ICDA is explained from a regularization aspect, with extensive experiments indicating that our method consistently improves the generalization performance of popular depth networks on multiple typical learning scenarios that require out-of-distribution generalization.