 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGMP:Heterogeneous Graph Multi-Task Prompt Learning
Jul 10, 2025
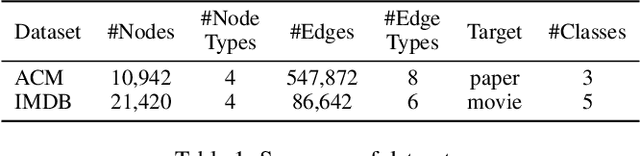


The pre-training and fine-tuning methods have gained widespread attention in the field of heterogeneous graph neural networks due to their ability to leverage large amounts of unlabeled data during the pre-training phase, allowing the model to learn rich structural features. However, these methods face the issue of a mismatch between the pre-trained model and downstream tasks, leading to suboptimal performance in certain application scenarios. Prompt learning methods have emerged as a new direction in heterogeneous graph tasks, as they allow flexible adaptation of task representations to address target inconsistency. Building on this idea, this paper proposes a novel multi-task prompt framework for the heterogeneous graph domain, named HGMP. First, to bridge the gap between the pre-trained model and downstream tasks, we reformulate all downstream tasks into a unified graph-level task format. Next, we address the limitations of existing graph prompt learning methods, which struggle to integrate contrastive pre-training strategies in the heterogeneous graph domain. We design a graph-level contrastive pre-training strategy to better leverage heterogeneous information and enhance performance in multi-task scenarios. Finally, we introduce heterogeneous feature prompts, which enhance model performance by refining the representation of input graph features. Experimental results on public datasets show that our proposed method adapts well to various tasks and significantly outperforms baseline methods.
HeTa: Relation-wise Heterogeneous Graph Foundation Attack Model
Jun 09, 2025Heterogeneous Graph Neural Networks (HGNNs) are vulnerable, highlighting the need for tailored attacks to assess their robustness and ensure security. However, existing HGNN attacks often require complex retraining of parameters to generate specific perturbations for new scenarios. Recently, foundation models have opened new horizons for the generalization of graph neural networks by capturing shared semantics across various graph distributions. This leads us to ask:Can we design a foundation attack model for HGNNs that enables generalizable perturbations across different HGNNs, and quickly adapts to new heterogeneous graphs (HGs)? Empirical findings reveal that, despite significant differences in model design and parameter space, different HGNNs surprisingly share common vulnerability patterns from a relation-aware perspective. Therefore, we explore how to design foundation HGNN attack criteria by mining shared attack units. In this paper, we propose a novel relation-wise heterogeneous graph foundation attack model, HeTa. We introduce a foundation surrogate model to align heterogeneity and identify the importance of shared relation-aware attack units. Building on this, we implement a serialized relation-by-relation attack based on the identified relational weights. In this way, the perturbation can be transferred to various target HGNNs and easily fine-tuned for new HGs. Extensive experiments exhibit powerful attack performances and generalizability of our method.
A Survey on Temporal Interaction Graph Representation Learning: Progress, Challenges, and Opportunities
May 07, 2025Temporal interaction graphs (TIGs), defined by sequences of timestamped interaction events, have become ubiquitous in real-world applications due to their capability to model complex dynamic system behaviors. As a result, temporal interaction graph representation learning (TIGRL) has garnered significant attention in recent years. TIGRL aims to embed nodes in TIGs into low-dimensional representations that effectively preserve both structural and temporal information, thereby enhancing the performance of downstream tasks such as classification, prediction, and clustering within constantly evolving data environments. In this paper, we begin by introducing the foundational concepts of TIGs and emphasize the critical role of temporal dependencies. We then propose a comprehensive taxonomy of state-of-the-art TIGRL methods, systematically categorizing them based on the types of information utilized during the learning process to address the unique challenges inherent to TIGs. To facilitate further research and practical applications, we curate the source of datasets and benchmarks, providing valuable resources for empirical investigations. Finally, we examine key open challenges and explore promising research directions in TIGRL, laying the groundwork for future advancements that have the potential to shape the evolution of this field.
Data Poisoning in Deep Learning: A Survey
Mar 27, 2025Deep learning has become a cornerstone of modern artificial intelligence, enabling transformative applications across a wide range of domains. As the core element of deep learning, the quality and security of training data critically influence model performance and reliability. However, during the training process, deep learning models face the significant threat of data poisoning, where attackers introduce maliciously manipulated training data to degrade model accuracy or lead to anomalous behavior. While existing surveys provide valuable insights into data poisoning, they generally adopt a broad perspective, encompassing both attacks and defenses, but lack a dedicated, in-depth analysis of poisoning attacks specifically in deep learning. In this survey, we bridge this gap by presenting a comprehensive and targeted review of data poisoning in deep learning. First, this survey categorizes data poisoning attacks across multiple perspectives, providing an in-depth analysis of their characteristics and underlying design princinples. Second, the discussion is extended to the emerging area of data poisoning in large language models(LLMs). Finally, we explore critical open challenges in the field and propose potential research directions to advance the field further. To support further exploration, an up-to-date repository of resources on data poisoning in deep learning is available at https://github.com/Pinlong-Zhao/Data-Poisoning.
MSE-Nets: Multi-annotated Semi-supervised Ensemble Networks for Improving Segmentation of Medical Image with Ambiguous Boundaries
Nov 17, 2023



Medical image segmentation annotations exhibit variations among experts due to the ambiguous boundaries of segmented objects and backgrounds in medical images. Although using multiple annotations for each image in the fully-supervised has been extensively studied for training deep models, obtaining a large amount of multi-annotated data is challenging due to the substantial time and manpower costs required for segmentation annotations, resulting in most images lacking any annotations. To address this, we propose Multi-annotated Semi-supervised Ensemble Networks (MSE-Nets) for learning segmentation from limited multi-annotated and abundant unannotated data. Specifically, we introduce the Network Pairwise Consistency Enhancement (NPCE) module and Multi-Network Pseudo Supervised (MNPS) module to enhance MSE-Nets for the segmentation task by considering two major factors: (1) to optimize the utilization of all accessible multi-annotated data, the NPCE separates (dis)agreement annotations of multi-annotated data at the pixel level and handles agreement and disagreement annotations in different ways, (2) to mitigate the introduction of imprecise pseudo-labels, the MNPS extends the training data by leveraging consistent pseudo-labels from unannotated data. Finally, we improve confidence calibration by averaging the predictions of base networks. Experiments on the ISIC dataset show that we reduced the demand for multi-annotated data by 97.75\% and narrowed the gap with the best fully-supervised baseline to just a Jaccard index of 4\%. Furthermore, compared to other semi-supervised methods that rely only on a single annotation or a combined fusion approach, the comprehensive experimental results on ISIC and RIGA datasets demonstrate the superior performance of our proposed method in medical image segmentation with ambiguous boundaries.
Temporal Graph Representation Learning with Adaptive Augmentation Contrastive
Nov 07, 2023Temporal graph representation learning aims to generate low-dimensional dynamic node embeddings to capture temporal information as well as structural and property information. Current representation learning methods for temporal networks often focus on capturing fine-grained information, which may lead to the model capturing random noise instead of essential semantic information. While graph contrastive learning has shown promise in dealing with noise, it only applies to static graphs or snapshots and may not be suitable for handling time-dependent noise. To alleviate the above challenge, we propose a novel Temporal Graph representation learning with Adaptive augmentation Contrastive (TGAC) model. The adaptive augmentation on the temporal graph is made by combining prior knowledge with temporal information, and the contrastive objective function is constructed by defining the augmented inter-view contrast and intra-view contrast. To complement TGAC, we propose three adaptive augmentation strategies that modify topological features to reduce noise from the network. Our extensive experiments on various real networks demonstrate that the proposed model outperforms other temporal graph representation learning methods.
Representation Learning on Heterostructures via Heterogeneous Anonymous Walks
Jan 18, 2022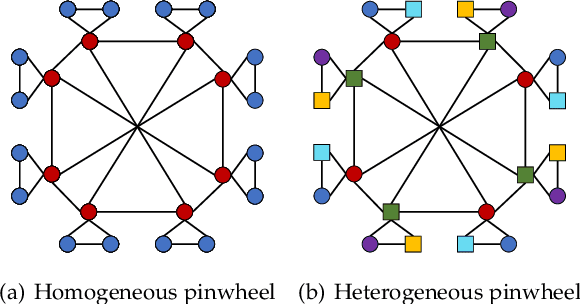
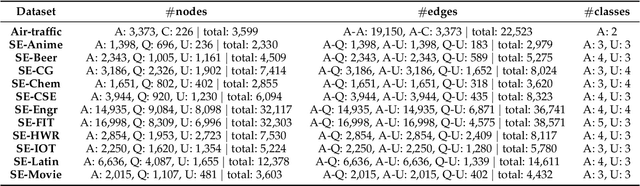
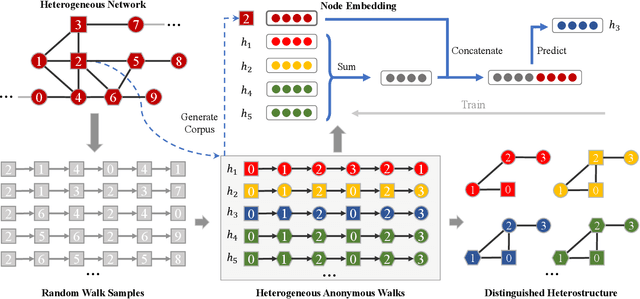
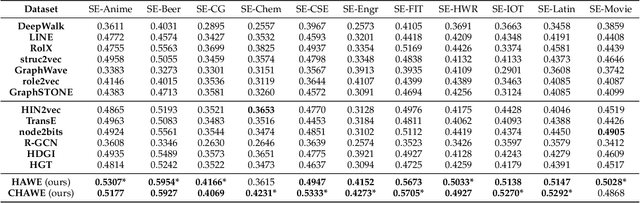
Capturing structural similarity has been a hot topic in the field of network embedding recently due to its great help in understanding the node functions and behaviors. However, existing works have paid very much attention to learning structures on homogeneous networks while the related study on heterogeneous networks is still a void. In this paper, we try to take the first step for representation learning on heterostructures, which is very challenging due to their highly diverse combinations of node types and underlying structures. To effectively distinguish diverse heterostructures, we firstly propose a theoretically guaranteed technique called heterogeneous anonymous walk (HAW) and its variant coarse HAW (CHAW). Then, we devise the heterogeneous anonymous walk embedding (HAWE) and its variant coarse HAWE in a data-driven manner to circumvent using an extremely large number of possible walks and train embeddings by predicting occurring walks in the neighborhood of each node. Finally, we design and apply extensive and illustrative experiments on synthetic and real-world networks to build a benchmark on heterostructure learning and evaluate the effectiveness of our methods. The results demonstrate our methods achieve outstanding performance compared with both homogeneous and heterogeneous classic methods, and can be applied on large-scale networks.
Block Modeling-Guided Graph Convolutional Neural Networks
Dec 28, 2021
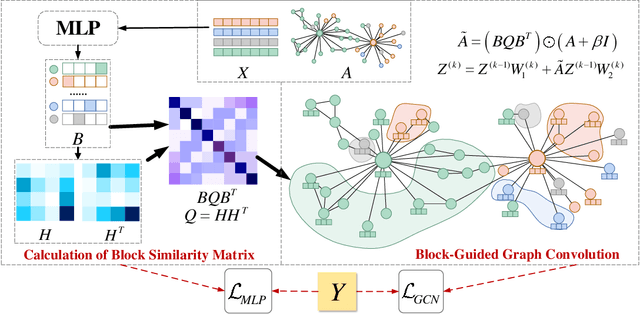
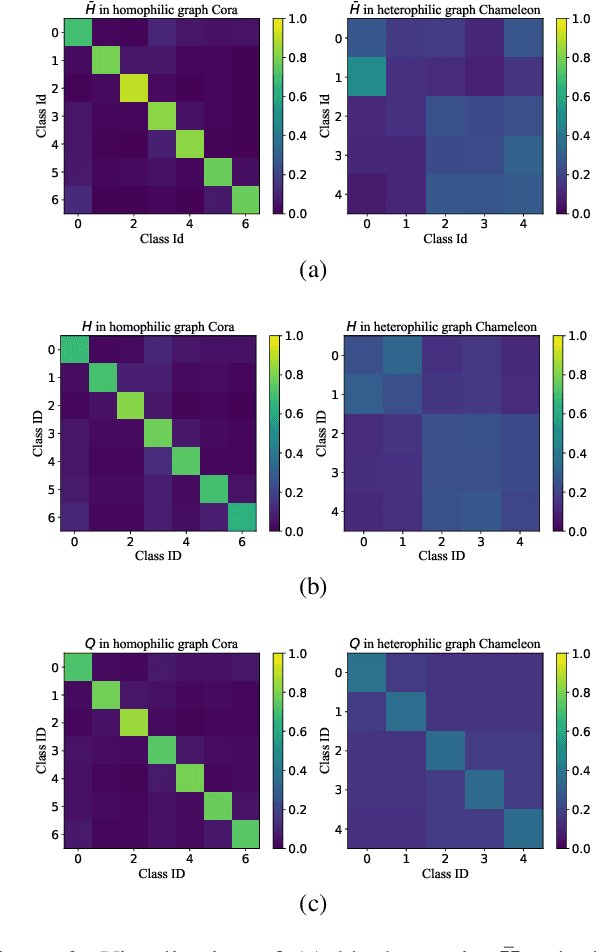
Graph Convolutional Network (GCN) has shown remarkable potential of exploring graph representation. However, the GCN aggregating mechanism fails to generalize to networks with heterophily where most nodes have neighbors from different classes, which commonly exists in real-world networks. In order to make the propagation and aggregation mechanism of GCN suitable for both homophily and heterophily (or even their mixture), we introduce block modeling into the framework of GCN so that it can realize "block-guided classified aggregation", and automatically learn the corresponding aggregation rules for neighbors of different classes. By incorporating block modeling into the aggregation process, GCN is able to aggregate information from homophilic and heterophilic neighbors discriminately according to their homophily degree. We compared our algorithm with state-of-art methods which deal with the heterophily problem. Empirical results demonstrate the superiority of our new approach over existing methods in heterophilic datasets while maintaining a competitive performance in homophilic datasets.
A Survey on Role-Oriented Network Embedding
Jul 18, 2021
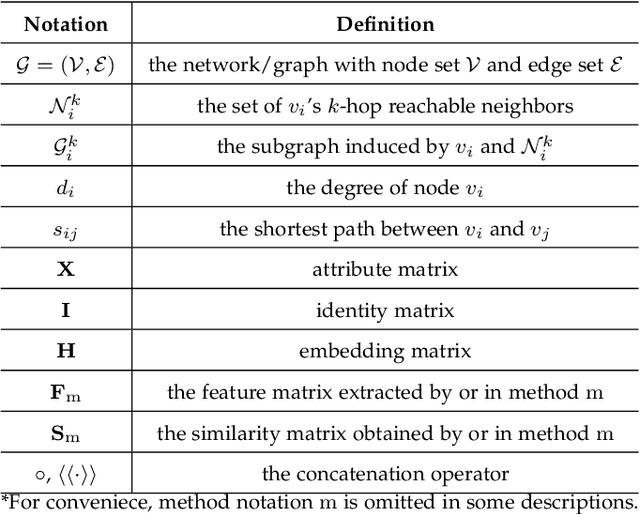
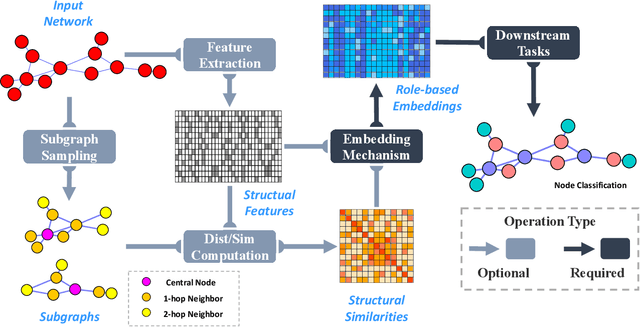
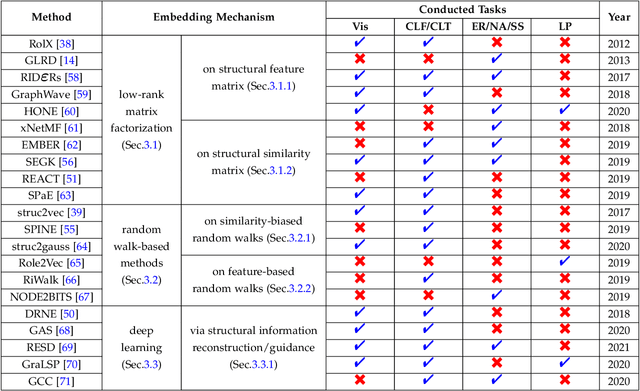
Recently, Network Embedding (NE) has become one of the most attractive research topics in machine learning and data mining. NE approaches have achieved promising performance in various of graph mining tasks including link prediction and node clustering and classification. A wide variety of NE methods focus on the proximity of networks. They learn community-oriented embedding for each node, where the corresponding representations are similar if two nodes are closer to each other in the network. Meanwhile, there is another type of structural similarity, i.e., role-based similarity, which is usually complementary and completely different from the proximity. In order to preserve the role-based structural similarity, the problem of role-oriented NE is raised. However, compared to community-oriented NE problem, there are only a few role-oriented embedding approaches proposed recently. Although less explored, considering the importance of roles in analyzing networks and many applications that role-oriented NE can shed light on, it is necessary and timely to provide a comprehensive overview of existing role-oriented NE methods. In this review, we first clarify the differences between community-oriented and role-oriented network embedding. Afterwards, we propose a general framework for understanding role-oriented NE and a two-level categorization to better classify existing methods. Then, we select some representative methods according to the proposed categorization and briefly introduce them by discussing their motivation, development and differences. Moreover, we conduct comprehensive experiments to empirically evaluate these methods on a variety of role-related tasks including node classification and clustering (role discovery), top-k similarity search and visualization using some widely used synthetic and real-world datasets...
A Survey of Community Detection Approaches: From Statistical Modeling to Deep Learning
Jan 03, 2021
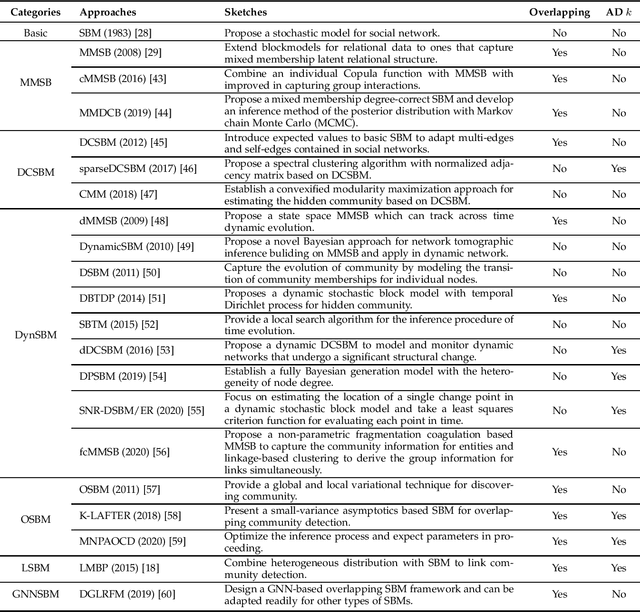
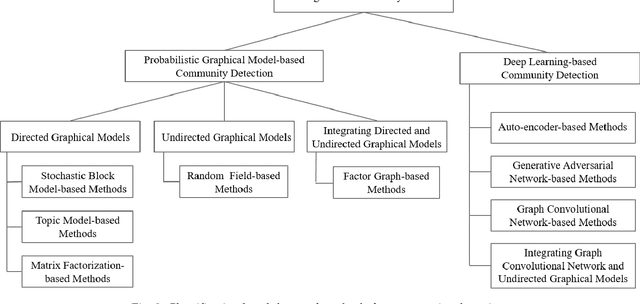
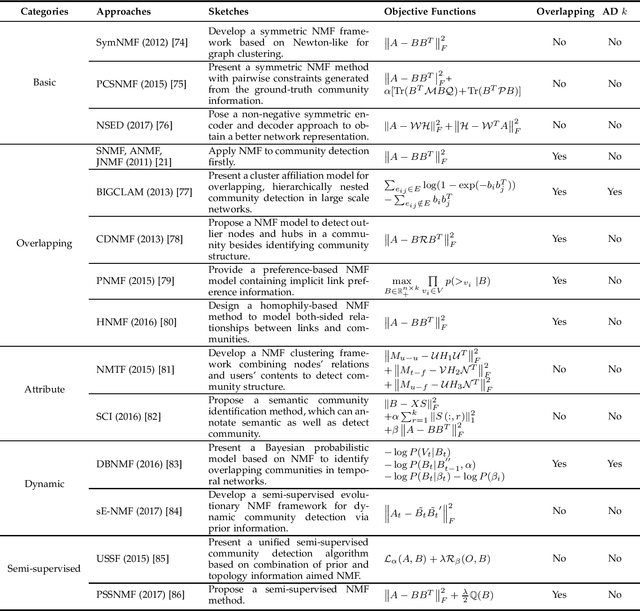
Community detection, a fundamental task for network analysis, aims to partition a network into multiple sub-structures to help reveal their latent functions. Community detection has been extensively studied in and broadly applied to many real-world network problems. Classical approaches to community detection typically utilize probabilistic graphical models and adopt a variety of prior knowledge to infer community structures. As the problems that network methods try to solve and the network data to be analyzed become increasingly more sophisticated, new approaches have also been proposed and developed, particularly those that utilize deep learning and convert networked data into low dimensional representation. Despite all the recent advancement, there is still a lack of insightful understanding of the theoretical and methodological underpinning of community detection, which will be critically important for future development of the area of network analysis. In this paper, we develop and present a unified architecture of network community-finding methods to characterize the state-of-the-art of the field of community detection. Specifically, we provide a comprehensive review of the existing community detection methods and introduce a new taxonomy that divides the existing methods into two categories, namely probabilistic graphical model and deep learning. We then discuss in detail the main idea behind each method in the two categories. Furthermore, to promote future development of community detection, we release several benchmark datasets from several problem domains and highlight their applications to various network analysis tasks. We conclude with discussions of the challenges of the field and suggestions of possible directions for future research.