 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGMP:Heterogeneous Graph Multi-Task Prompt Learning
Jul 10, 2025


The pre-training and fine-tuning methods have gained widespread attention in the field of heterogeneous graph neural networks due to their ability to leverage large amounts of unlabeled data during the pre-training phase, allowing the model to learn rich structural features. However, these methods face the issue of a mismatch between the pre-trained model and downstream tasks, leading to suboptimal performance in certain application scenarios. Prompt learning methods have emerged as a new direction in heterogeneous graph tasks, as they allow flexible adaptation of task representations to address target inconsistency. Building on this idea, this paper proposes a novel multi-task prompt framework for the heterogeneous graph domain, named HGMP. First, to bridge the gap between the pre-trained model and downstream tasks, we reformulate all downstream tasks into a unified graph-level task format. Next, we address the limitations of existing graph prompt learning methods, which struggle to integrate contrastive pre-training strategies in the heterogeneous graph domain. We design a graph-level contrastive pre-training strategy to better leverage heterogeneous information and enhance performance in multi-task scenarios. Finally, we introduce heterogeneous feature prompts, which enhance model performance by refining the representation of input graph features. Experimental results on public datasets show that our proposed method adapts well to various tasks and significantly outperforms baseline methods.
A Survey on Temporal Interaction Graph Representation Learning: Progress, Challenges, and Opportunities
May 07, 2025Temporal interaction graphs (TIGs), defined by sequences of timestamped interaction events, have become ubiquitous in real-world applications due to their capability to model complex dynamic system behaviors. As a result, temporal interaction graph representation learning (TIGRL) has garnered significant attention in recent years. TIGRL aims to embed nodes in TIGs into low-dimensional representations that effectively preserve both structural and temporal information, thereby enhancing the performance of downstream tasks such as classification, prediction, and clustering within constantly evolving data environments. In this paper, we begin by introducing the foundational concepts of TIGs and emphasize the critical role of temporal dependencies. We then propose a comprehensive taxonomy of state-of-the-art TIGRL methods, systematically categorizing them based on the types of information utilized during the learning process to address the unique challenges inherent to TIGs. To facilitate further research and practical applications, we curate the source of datasets and benchmarks, providing valuable resources for empirical investigations. Finally, we examine key open challenges and explore promising research directions in TIGRL, laying the groundwork for future advancements that have the potential to shape the evolution of this field.
Temporal Graph Representation Learning with Adaptive Augmentation Contrastive
Nov 07, 2023Temporal graph representation learning aims to generate low-dimensional dynamic node embeddings to capture temporal information as well as structural and property information. Current representation learning methods for temporal networks often focus on capturing fine-grained information, which may lead to the model capturing random noise instead of essential semantic information. While graph contrastive learning has shown promise in dealing with noise, it only applies to static graphs or snapshots and may not be suitable for handling time-dependent noise. To alleviate the above challenge, we propose a novel Temporal Graph representation learning with Adaptive augmentation Contrastive (TGAC) model. The adaptive augmentation on the temporal graph is made by combining prior knowledge with temporal information, and the contrastive objective function is constructed by defining the augmented inter-view contrast and intra-view contrast. To complement TGAC, we propose three adaptive augmentation strategies that modify topological features to reduce noise from the network. Our extensive experiments on various real networks demonstrate that the proposed model outperforms other temporal graph representation learning methods.
HQNAS: Auto CNN deployment framework for joint quantization and architecture search
Oct 16, 2022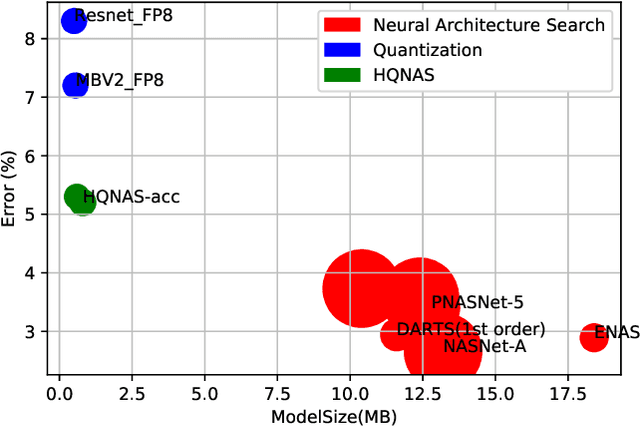
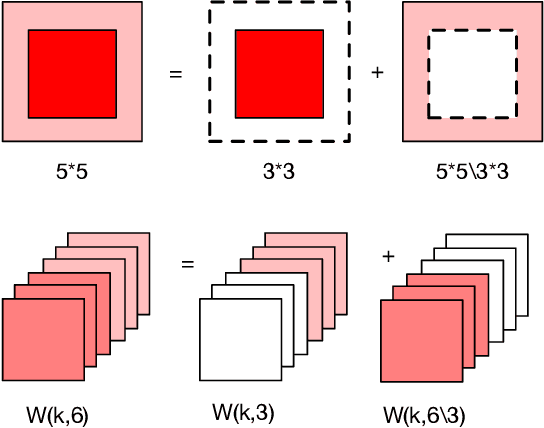
Deep learning applications are being transferred from the cloud to edge with the rapid development of embedded computing systems. In order to achieve higher energy efficiency with the limited resource budget, neural networks(NNs) must be carefully designed in two steps, the architecture design and the quantization policy choice. Neural Architecture Search(NAS) and Quantization have been proposed separately when deploying NNs onto embedded devices. However, taking the two steps individually is time-consuming and leads to a sub-optimal final deployment. To this end, we propose a novel neural network design framework called Hardware-aware Quantized Neural Architecture Search(HQNAS) framework which combines the NAS and Quantization together in a very efficient manner using weight-sharing and bit-sharing. It takes only 4 GPU hours to discover an outstanding NN policy on CIFAR10. It also takes only %10 GPU time to generate a comparable model on Imagenet compared to the traditional NAS method with 1.8x decrease of latency and a negligible accuracy loss of only 0.7%. Besides, our method can be adapted in a lifelong situation where the neural network needs to evolve occasionally due to changes of local data, environment and user preference.
FAQS: Communication-efficient Federate DNN Architecture and Quantization Co-Search for personalized Hardware-aware Preferences
Oct 16, 2022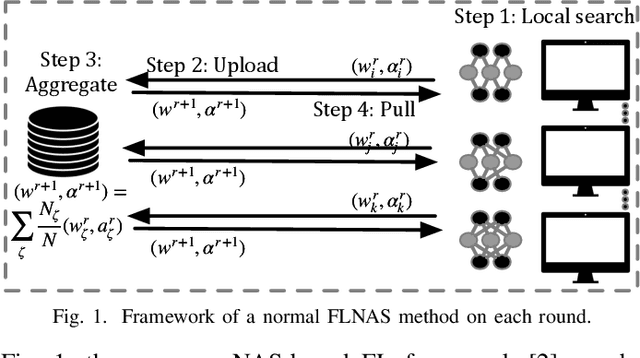
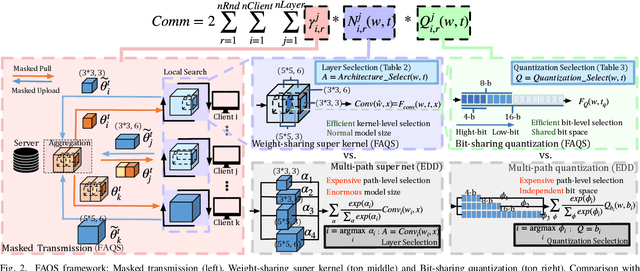
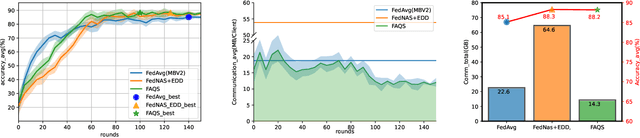
Due to user privacy and regulatory restrictions, federate learning (FL) is proposed as a distributed learning framework for training deep neural networks (DNN) on decentralized data clients. Recent advancements in FL have applied Neural Architecture Search (NAS) to replace the predefined one-size-fit-all DNN model, which is not optimal for all tasks of various data distributions, with searchable DNN architectures. However, previous methods suffer from expensive communication cost rasied by frequent large model parameters transmission between the server and clients. Such difficulty is further amplified when combining NAS algorithms, which commonly require prohibitive computation and enormous model storage. Towards this end, we propose FAQS, an efficient personalized FL-NAS-Quantization framework to reduce the communication cost with three features: weight-sharing super kernels, bit-sharing quantization and masked transmission. FAQS has an affordable search time and demands very limited size of transmitted messages at each round. By setting different personlized pareto function loss on local clients, FAQS can yield heterogeneous hardware-aware models for various user preferences. Experimental results show that FAQS achieves average reduction of 1.58x in communication bandwith per round compared with normal FL framework and 4.51x compared with FL+NAS framwork.
A total hip surgery robot system based on intelligent positioning and optical measurement
Jun 15, 2022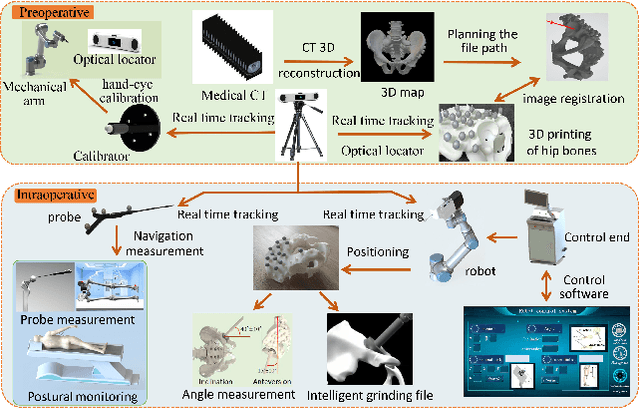

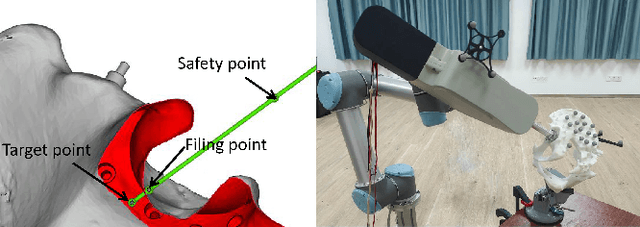
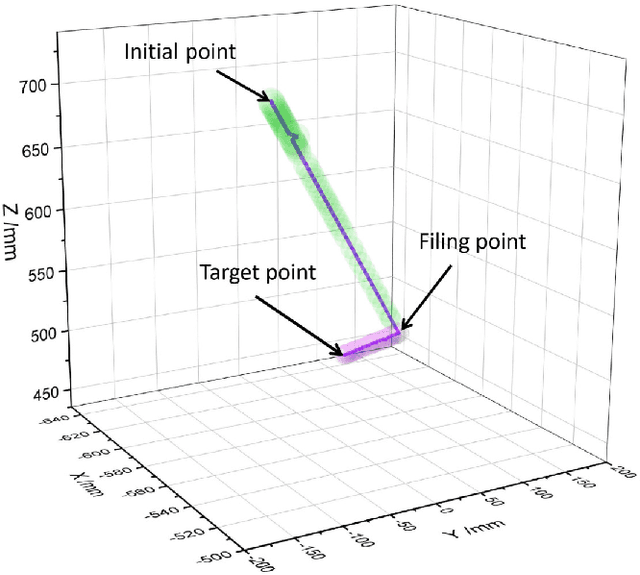
This paper represents the development and experimental evaluation of an autonomous navigation surgical robot system for total hip arthroplasty (THA). Existing robotic systems used in joint replacement surgery have achieved good clinical results, with reported better accuracy. While the surgeon needs to locate the robot arm to the target position during the operation, which is easily affected by the doctor of experience. Yet, the hand-hold acetabulum reamer is easy to appear with uneven strength and grinding file. Further, the lack of steps to measure the femoral neck length may lead to poor results.To tackle this challenge, our design contains the real-time traceable optical positioning strategy to reduce unnecessary manual adjustments to the robotic arm during surgery, the intelligent end-effector system to stable the grinding, and the optical probe to provide real-time measurement of femoral neck length and other parameters to choose the prosthesis. The length of the lower limbs was measured as the prosthesis was installed. Experimental evaluation showed that the robot of precision, execution ability, and robustness are better than expected.