 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent and Efficient MSCKF-based LiDAR-Inertial Odometry with Inferred Cluster-to-Plane Constraints for UAVs
Mar 13, 2026Robust and accurate navigation is critical for Unmanned Aerial Vehicles (UAVs) especially for those with stringent Size, Weight, and Power (SWaP) constraints. However, most state-of-the-art (SOTA) LiDAR-Inertial Odometry (LIO) systems still suffer from estimation inconsistency and computational bottlenecks when deployed on such platforms. To address these issues, this paper proposes a consistent and efficient tightly-coupled LIO framework tailored for UAVs. Within the efficient Multi-State Constraint Kalman Filter (MSCKF) framework, we build coplanar constraints inferred from planar features observed across a sliding window. By applying null-space projection to sliding-window coplanar constraints, we eliminate the direct dependency on feature parameters in the state vector, thereby mitigating overconfidence and improving consistency. More importantly, to further boost the efficiency, we introduce a parallel voxel-based data association and a novel compact cluster-to-plane measurement model. This compact measurement model losslessly reduces observation dimensionality and significantly accelerating the update process. Extensive evaluations demonstrate that our method outperforms most state-of-the-art (SOTA) approaches by providing a superior balance of consistency and efficiency. It exhibits improved robustness in degenerate scenarios, achieves the lowest memory usage via its map-free nature, and runs in real-time on resource-constrained embedded platforms (e.g., NVIDIA Jetson TX2).
Failure-Aware Bimanual Teleoperation via Conservative Value Guided Assistance
Feb 01, 2026Teleoperation of high-precision manipulation is con-strained by tight success tolerances and complex contact dy-namics, which make impending failures difficult for human operators to anticipate under partial observability. This paper proposes a value-guided, failure-aware framework for bimanual teleoperation that provides compliant haptic assistance while pre-serving continuous human authority. The framework is trained entirely from heterogeneous offline teleoperation data containing both successful and failed executions. Task feasibility is mod-eled as a conservative success score learned via Conservative Value Learning, yielding a risk-sensitive estimate that remains reliable under distribution shift. During online operation, the learned success score regulates the level of assistance, while a learned actor provides a corrective motion direction. Both are integrated through a joint-space impedance interface on the master side, yielding continuous guidance that steers the operator away from failure-prone actions without overriding intent. Experimental results on contact-rich manipulation tasks demonstrate improved task success rates and reduced operator workload compared to conventional teleoperation and shared-autonomy baselines, indicating that conservative value learning provides an effective mechanism for embedding failure awareness into bilateral teleoperation. Experimental videos are available at https://www.youtube.com/watch?v=XDTsvzEkDRE
EvoClinician: A Self-Evolving Agent for Multi-Turn Medical Diagnosis via Test-Time Evolutionary Learning
Jan 30, 2026Prevailing medical AI operates on an unrealistic ''one-shot'' model, diagnosing from a complete patient file. However, real-world diagnosis is an iterative inquiry where Clinicians sequentially ask questions and order tests to strategically gather information while managing cost and time. To address this, we first propose Med-Inquire, a new benchmark designed to evaluate an agent's ability to perform multi-turn diagnosis. Built upon a dataset of real-world clinical cases, Med-Inquire simulates the diagnostic process by hiding a complete patient file behind specialized Patient and Examination agents. They force the agent to proactively ask questions and order tests to gather information piece by piece. To tackle the challenges posed by Med-Inquire, we then introduce EvoClinician, a self-evolving agent that learns efficient diagnostic strategies at test time. Its core is a ''Diagnose-Grade-Evolve'' loop: an Actor agent attempts a diagnosis; a Process Grader agent performs credit assignment by evaluating each action for both clinical yield and resource efficiency; finally, an Evolver agent uses this feedback to update the Actor's strategy by evolving its prompt and memory. Our experiments show EvoClinician outperforms continual learning baselines and other self-evolving agents like memory agents. The code is available at https://github.com/yf-he/EvoClinician
Autonomous Chain-of-Thought Distillation for Graph-Based Fraud Detection
Jan 30, 2026Graph-based fraud detection on text-attributed graphs (TAGs) requires jointly modeling rich textual semantics and relational dependencies. However, existing LLM-enhanced GNN approaches are constrained by predefined prompting and decoupled training pipelines, limiting reasoning autonomy and weakening semantic-structural alignment. We propose FraudCoT, a unified framework that advances TAG-based fraud detection through autonomous, graph-aware chain-of-thought (CoT) reasoning and scalable LLM-GNN co-training. To address the limitations of predefined prompts, we introduce a fraud-aware selective CoT distillation mechanism that generates diverse reasoning paths and enhances semantic-structural understanding. These distilled CoTs are integrated into node texts, providing GNNs with enriched, multi-hop semantic and structural cues for fraud detection. Furthermore, we develop an efficient asymmetric co-training strategy that enables end-to-end optimization while significantly reducing the computational cost of naive joint training. Extensive experiments on public and industrial benchmarks demonstrate that FraudCoT achieves up to 8.8% AUPRC improvement over state-of-the-art methods and delivers up to 1,066x speedup in training throughput, substantially advancing both detection performance and efficiency.
Cross-Modal Attention Network with Dual Graph Learning in Multimodal Recommendation
Jan 16, 2026Multimedia recommendation systems leverage user-item interactions and multimodal information to capture user preferences, enabling more accurate and personalized recommendations. Despite notable advancements, existing approaches still face two critical limitations: first, shallow modality fusion often relies on simple concatenation, failing to exploit rich synergic intra- and inter-modal relationships; second, asymmetric feature treatment-where users are only characterized by interaction IDs while items benefit from rich multimodal content-hinders the learning of a shared semantic space. To address these issues, we propose a Cross-modal Recursive Attention Network with dual graph Embedding (CRANE). To tackle shallow fusion, we design a core Recursive Cross-Modal Attention (RCA) mechanism that iteratively refines modality features based on cross-correlations in a joint latent space, effectively capturing high-order intra- and inter-modal dependencies. For symmetric multimodal learning, we explicitly construct users' multimodal profiles by aggregating features of their interacted items. Furthermore, CRANE integrates a symmetric dual-graph framework-comprising a heterogeneous user-item interaction graph and a homogeneous item-item semantic graph-unified by a self-supervised contrastive learning objective to fuse behavioral and semantic signals. Despite these complex modeling capabilities, CRANE maintains high computational efficiency. Theoretical and empirical analyses confirm its scalability and high practical efficiency, achieving faster convergence on small datasets and superior performance ceilings on large-scale ones. Comprehensive experiments on four public real-world datasets validate an average 5% improvement in key metrics over state-of-the-art baselines.
UniBiDex: A Unified Teleoperation Framework for Robotic Bimanual Dexterous Manipulation
Jan 08, 2026We present UniBiDex a unified teleoperation framework for robotic bimanual dexterous manipulation that supports both VRbased and leaderfollower input modalities UniBiDex enables realtime contactrich dualarm teleoperation by integrating heterogeneous input devices into a shared control stack with consistent kinematic treatment and safety guarantees The framework employs nullspace control to optimize bimanual configurations ensuring smooth collisionfree and singularityaware motion across tasks We validate UniBiDex on a longhorizon kitchentidying task involving five sequential manipulation subtasks demonstrating higher task success rates smoother trajectories and improved robustness compared to strong baselines By releasing all hardware and software components as opensource we aim to lower the barrier to collecting largescale highquality human demonstration datasets and accelerate progress in robot learning.
Study of Class-Incremental Radio Frequency Fingerprint Recognition Without Storing Exemplars
Jan 06, 2026The rapid proliferation of wireless devices makes robust identity authentication essential. Radio Frequency Fingerprinting (RFF) exploits device-specific, hard-to-forge physical-layer impairments for identification, and is promising for IoT and unmanned systems. In practice, however, new devices continuously join deployed systems while per-class training data are limited. Conventional static training and naive replay of stored exemplars are impractical due to growing class cardinality, storage cost, and privacy concerns. We propose an exemplar-free class-incremental learning framework tailored to RFF recognition. Starting from a pretrained feature extractor, we freeze the backbone during incremental stages and train only a classifier together with lightweight Adapter modules that perform small task-specific feature adjustments. For each class we fit a diagonal Gaussian Mixture Model (GMM) to the backbone features and sample pseudo-features from these fitted distributions to rehearse past classes without storing raw signals. To improve robustness under few-shot conditions we introduce a time-domain random-masking augmentation and adopt a multi-teacher distillation scheme to compress stage-wise Adapters into a single inference Adapter, trading off accuracy and runtime efficiency. We evaluate the method on large, self-collected ADS-B datasets: the backbone is pretrained on 2,175 classes and incremental experiments are run on a disjoint set of 669 classes with multiple rounds and step sizes. Against several representative baselines, our approach consistently yields higher average accuracy and lower forgetting, while using substantially less storage and avoiding raw-data retention. The proposed pipeline is reproducible and provides a practical, low-storage solution for RFF deployment in resource- and privacy-constrained environments.
Echoless Label-Based Pre-computation for Memory-Efficient Heterogeneous Graph Learning
Nov 14, 2025Heterogeneous Graph Neural Networks (HGNNs) are widely used for deep learning on heterogeneous graphs. Typical end-to-end HGNNs require repetitive message passing during training, limiting efficiency for large-scale real-world graphs. Pre-computation-based HGNNs address this by performing message passing only once during preprocessing, collecting neighbor information into regular-shaped tensors, which enables efficient mini-batch training. Label-based pre-computation methods collect neighbors' label information but suffer from training label leakage, where a node's own label information propagates back to itself during multi-hop message passing - the echo effect. Existing mitigation strategies are memory-inefficient on large graphs or suffer from compatibility issues with advanced message passing methods. We propose Echoless Label-based Pre-computation (Echoless-LP), which eliminates training label leakage with Partition-Focused Echoless Propagation (PFEP). PFEP partitions target nodes and performs echoless propagation, where nodes in each partition collect label information only from neighbors in other partitions, avoiding echo while remaining memory-efficient and compatible with any message passing method. We also introduce an Asymmetric Partitioning Scheme (APS) and a PostAdjust mechanism to address information loss from partitioning and distributional shifts across partitions. Experiments on public datasets demonstrate that Echoless-LP achieves superior performance and maintains memory efficiency compared to baselines.
DarkDiff: Advancing Low-Light Raw Enhancement by Retasking Diffusion Models for Camera ISP
May 29, 2025High-quality photography in extreme low-light conditions is challenging but impactful for digital cameras. With advanced computing hardware, traditional camera image signal processor (ISP) algorithms are gradually being replaced by efficient deep networks that enhance noisy raw images more intelligently. However, existing regression-based models often minimize pixel errors and result in oversmoothing of low-light photos or deep shadows. Recent work has attempted to address this limitation by training a diffusion model from scratch, yet those models still struggle to recover sharp image details and accurate colors. We introduce a novel framework to enhance low-light raw images by retasking pre-trained generative diffusion models with the camera ISP. Extensive experiments demonstrate that our method outperforms the state-of-the-art in perceptual quality across three challenging low-light raw image benchmarks.
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
May 25, 2025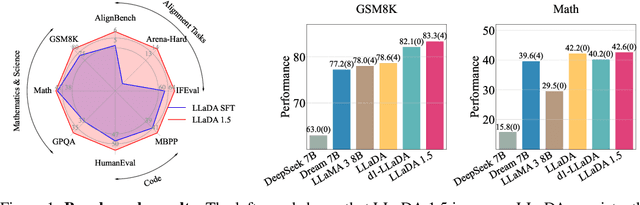
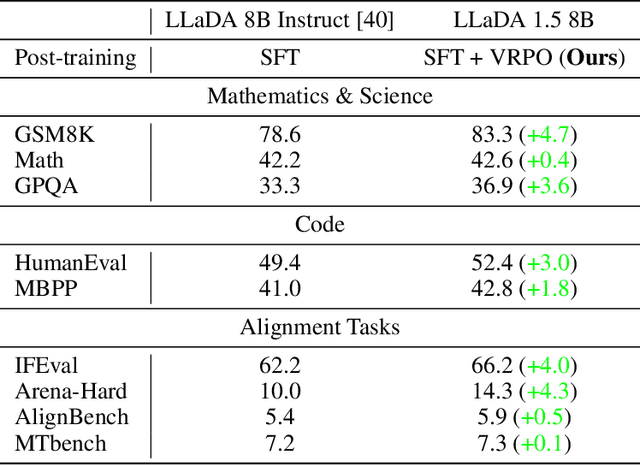
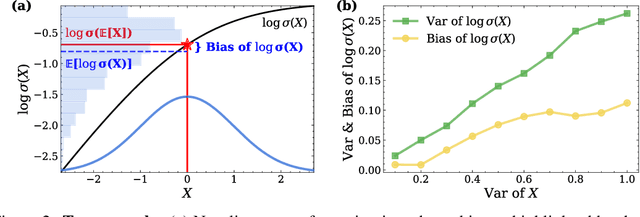
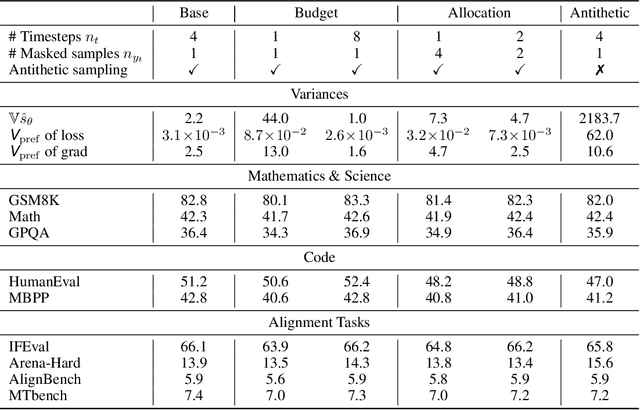
While Masked Diffusion Models (MDMs), such as LLaDA, present a promising paradigm for language modeling, there has been relatively little effort in aligning these models with human preferences via reinforcement learning. The challenge primarily arises from the high variance in Evidence Lower Bound (ELBO)-based likelihood estimates required for preference optimization. To address this issue, we propose Variance-Reduced Preference Optimization (VRPO), a framework that formally analyzes the variance of ELBO estimators and derives bounds on both the bias and variance of preference optimization gradients. Building on this theoretical foundation, we introduce unbiased variance reduction strategies, including optimal Monte Carlo budget allocation and antithetic sampling, that significantly improve the performance of MDM alignment. We demonstrate the effectiveness of VRPO by applying it to LLaDA, and the resulting model, LLaDA 1.5, outperforms its SFT-only predecessor consistently and significantly across mathematical (GSM8K +4.7), code (HumanEval +3.0, MBPP +1.8), and alignment benchmarks (IFEval +4.0, Arena-Hard +4.3). Furthermore, LLaDA 1.5 demonstrates a highly competitive mathematical performance compared to strong language MDMs and ARMs. Project page: https://ml-gsai.github.io/LLaDA-1.5-Demo/.