 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Condition for $μ$P under Width-Depth Scaling
Feb 28, 2026Generative foundation models are increasingly scaled in both width and depth, posing significant challenges for stable feature learning and reliable hyperparameter (HP) transfer across model sizes. While maximal update parameterization ($μ$P) has provided a principled solution to both problems for width scaling, existing extensions to the joint width-depth scaling regime remain fragmented, architecture- and optimizer-specific, and often rely on technically involved theories. In this work, we develop a simple and unified spectral framework for $μ$P under joint width-depth scaling. Considering residual networks of varying block depths, we first introduce a spectral $μ$P condition that precisely characterizes how the norms of weights and their per-step updates should scale with width and depth, unifying previously disparate $μ$P formulations as special cases. Building on this condition, we then derive a general recipe for implementing $μ$P across a broad class of optimizers by mapping the spectral constraints to concrete HP parameterizations. This approach not only recovers existing $μ$P formulations (e.g., for SGD and AdamW) but also naturally extends to a wider range of optimizers. Finally, experiments on GPT-2 style language models demonstrate that the proposed spectral $μ$P condition preserves stable feature learning and enables robust HP transfer under width-depth scaling.
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
May 25, 2025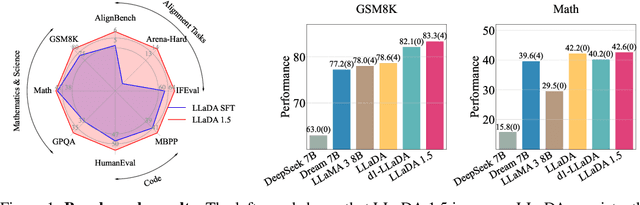
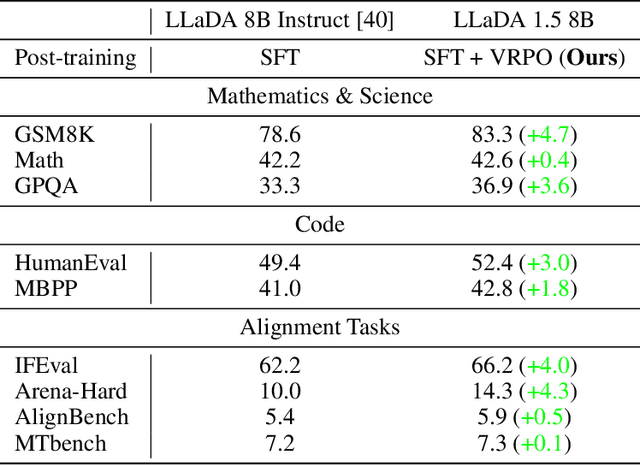
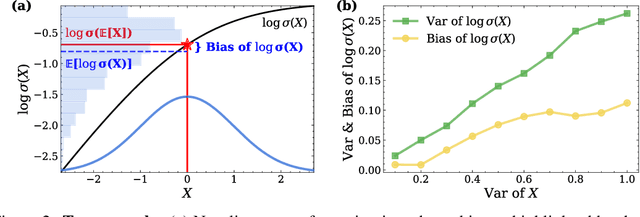
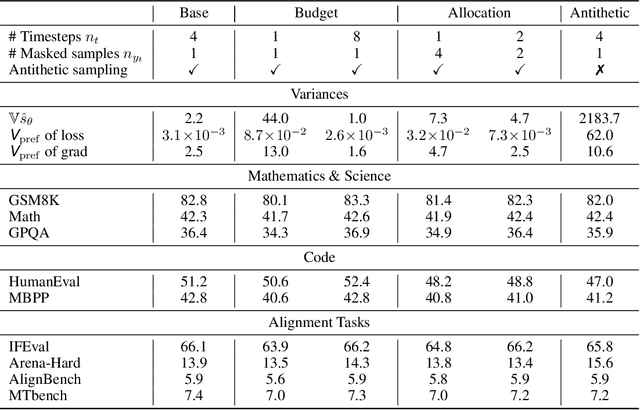
While Masked Diffusion Models (MDMs), such as LLaDA, present a promising paradigm for language modeling, there has been relatively little effort in aligning these models with human preferences via reinforcement learning. The challenge primarily arises from the high variance in Evidence Lower Bound (ELBO)-based likelihood estimates required for preference optimization. To address this issue, we propose Variance-Reduced Preference Optimization (VRPO), a framework that formally analyzes the variance of ELBO estimators and derives bounds on both the bias and variance of preference optimization gradients. Building on this theoretical foundation, we introduce unbiased variance reduction strategies, including optimal Monte Carlo budget allocation and antithetic sampling, that significantly improve the performance of MDM alignment. We demonstrate the effectiveness of VRPO by applying it to LLaDA, and the resulting model, LLaDA 1.5, outperforms its SFT-only predecessor consistently and significantly across mathematical (GSM8K +4.7), code (HumanEval +3.0, MBPP +1.8), and alignment benchmarks (IFEval +4.0, Arena-Hard +4.3). Furthermore, LLaDA 1.5 demonstrates a highly competitive mathematical performance compared to strong language MDMs and ARMs. Project page: https://ml-gsai.github.io/LLaDA-1.5-Demo/.
Scaling Diffusion Transformers Efficiently via $μ$P
May 21, 2025Diffusion Transformers have emerged as the foundation for vision generative models, but their scalability is limited by the high cost of hyperparameter (HP) tuning at large scales. Recently, Maximal Update Parametrization ($\mu$P) was proposed for vanilla Transformers, which enables stable HP transfer from small to large language models, and dramatically reduces tuning costs. However, it remains unclear whether $\mu$P of vanilla Transformers extends to diffusion Transformers, which differ architecturally and objectively. In this work, we generalize standard $\mu$P to diffusion Transformers and validate its effectiveness through large-scale experiments. First, we rigorously prove that $\mu$P of mainstream diffusion Transformers, including DiT, U-ViT, PixArt-$\alpha$, and MMDiT, aligns with that of the vanilla Transformer, enabling the direct application of existing $\mu$P methodologies. Leveraging this result, we systematically demonstrate that DiT-$\mu$P enjoys robust HP transferability. Notably, DiT-XL-2-$\mu$P with transferred learning rate achieves 2.9 times faster convergence than the original DiT-XL-2. Finally, we validate the effectiveness of $\mu$P on text-to-image generation by scaling PixArt-$\alpha$ from 0.04B to 0.61B and MMDiT from 0.18B to 18B. In both cases, models under $\mu$P outperform their respective baselines while requiring small tuning cost, only 5.5% of one training run for PixArt-$\alpha$ and 3% of consumption by human experts for MMDiT-18B. These results establish $\mu$P as a principled and efficient framework for scaling diffusion Transformers.
A Theory for Conditional Generative Modeling on Multiple Data Sources
Feb 20, 2025The success of large generative models has driven a paradigm shift, leveraging massive multi-source data to enhance model capabilities. However, the interaction among these sources remains theoretically underexplored. This paper takes the first step toward a rigorous analysis of multi-source training in conditional generative modeling, where each condition represents a distinct data source. Specifically, we establish a general distribution estimation error bound in average total variation distance for conditional maximum likelihood estimation based on the bracketing number. Our result shows that when source distributions share certain similarities and the model is expressive enough, multi-source training guarantees a sharper bound than single-source training. We further instantiate the general theory on conditional Gaussian estimation and deep generative models including autoregressive and flexible energy-based models, by characterizing their bracketing numbers. The results highlight that the number of sources and similarity among source distributions improve the advantage of multi-source training. Simulations and real-world experiments validate our theory. Code is available at: \url{https://github.com/ML-GSAI/Multi-Source-GM}.
On Mesa-Optimization in Autoregressively Trained Transformers: Emergence and Capability
May 27, 2024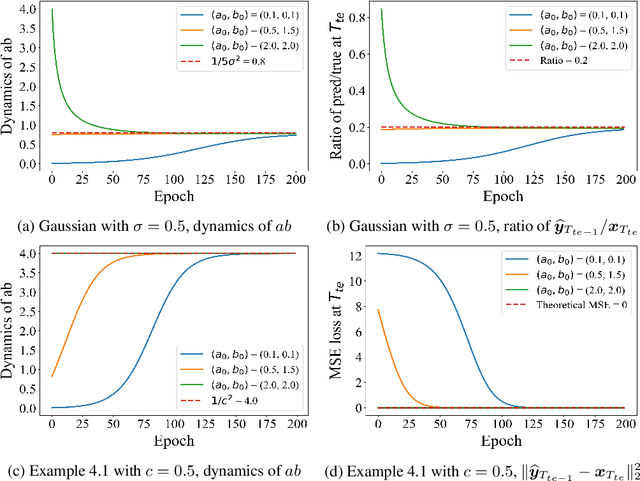
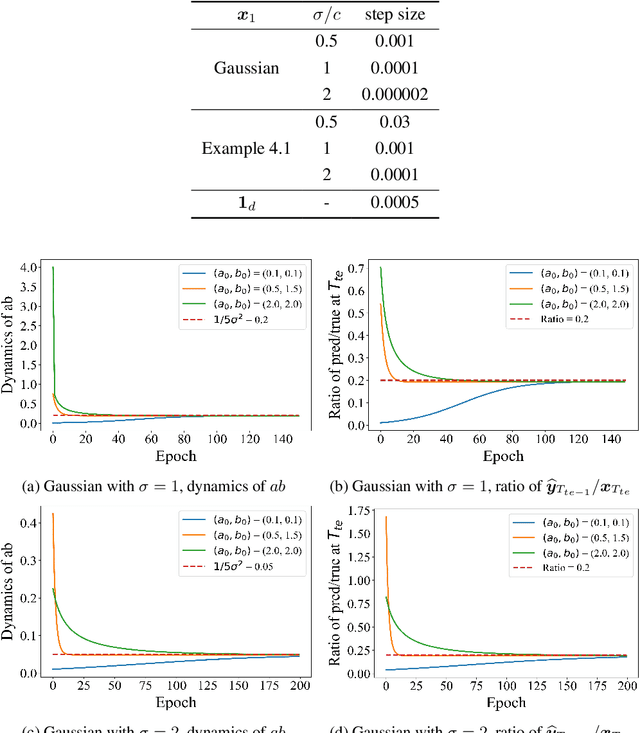
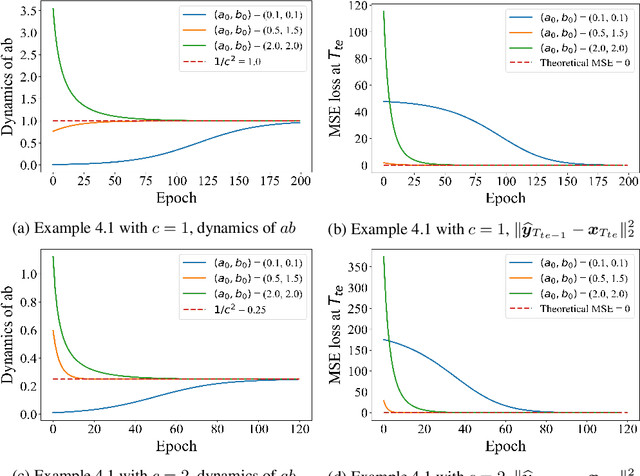
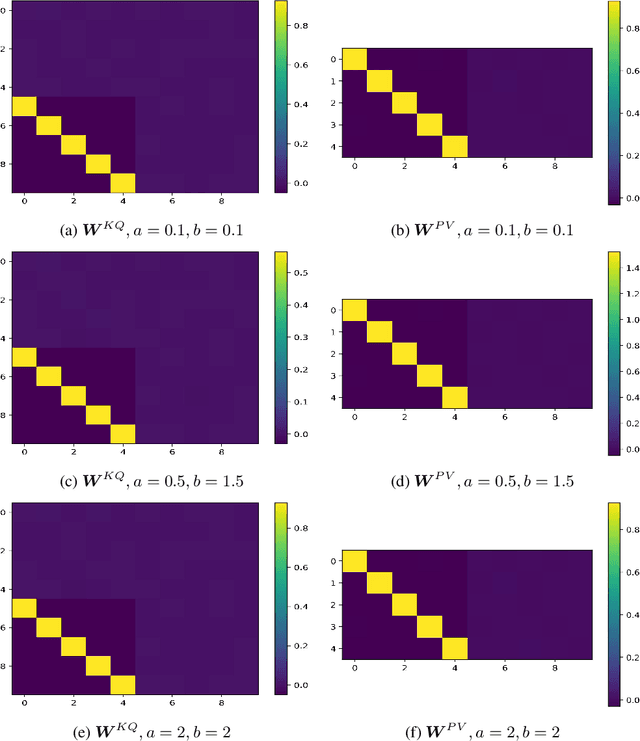
Autoregressively trained transformers have brought a profound revolution to the world, especially with their in-context learning (ICL) ability to address downstream tasks. Recently, several studies suggest that transformers learn a mesa-optimizer during autoregressive (AR) pretraining to implement ICL. Namely, the forward pass of the trained transformer is equivalent to optimizing an inner objective function in-context. However, whether the practical non-convex training dynamics will converge to the ideal mesa-optimizer is still unclear. Towards filling this gap, we investigate the non-convex dynamics of a one-layer linear causal self-attention model autoregressively trained by gradient flow, where the sequences are generated by an AR process $x_{t+1} = W x_t$. First, under a certain condition of data distribution, we prove that an autoregressively trained transformer learns $W$ by implementing one step of gradient descent to minimize an ordinary least squares (OLS) problem in-context. It then applies the learned $\widehat{W}$ for next-token prediction, thereby verifying the mesa-optimization hypothesis. Next, under the same data conditions, we explore the capability limitations of the obtained mesa-optimizer. We show that a stronger assumption related to the moments of data is the sufficient and necessary condition that the learned mesa-optimizer recovers the distribution. Besides, we conduct exploratory analyses beyond the first data condition and prove that generally, the trained transformer will not perform vanilla gradient descent for the OLS problem. Finally, our simulation results verify the theoretical results.
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing
May 26, 2023



In this paper, we present ControlVideo, a novel method for text-driven video editing. Leveraging the capabilities of text-to-image diffusion models and ControlNet, ControlVideo aims to enhance the fidelity and temporal consistency of videos that align with a given text while preserving the structure of the source video. This is achieved by incorporating additional conditions such as edge maps, fine-tuning the key-frame and temporal attention on the source video-text pair with carefully designed strategies. An in-depth exploration of ControlVideo's design is conducted to inform future research on one-shot tuning video diffusion models. Quantitatively, ControlVideo outperforms a range of competitive baselines in terms of faithfulness and consistency while still aligning with the textual prompt. Additionally, it delivers videos with high visual realism and fidelity w.r.t. the source content, demonstrating flexibility in utilizing controls containing varying degrees of source video information, and the potential for multiple control combinations. The project page is available at \href{https://ml.cs.tsinghua.edu.cn/controlvideo/}{https://ml.cs.tsinghua.edu.cn/controlvideo/}.