 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: An AutoRegressive Large Multimodal Model with Unified Discrete Representations
Jun 09, 2026This paper introduces ARM, a discrete representation-based AutoRegressive Model that unifies image understanding, generation, and editing within a next-token prediction framework. ARM is built on three efforts: first, we train a discrete semantic visual tokenizer that maps images into compact token sequences. Our tokenizer is supervised with multiple objectives that jointly promote semantic discriminability, language alignment and faithful reconstruction, thereby supporting diverse tasks in a shared latent space. With this, we train a 7B autoregressive model over large-scale text and image token sequences, seamlessly developing vision-language perception and generation capabilities. Finally, to further improve preference-aligned behavior for text-to-image generation and instruction-guided editing, ARM applies reinforcement learning (RL) to optimize task-level objectives such as visual quality, instruction adherence, and edit consistency. Surprisingly, the results show that RL not only substantially improves performance on the target tasks (e.g., raising WISE overall from 0.50 to 0.56, GEdit-Bench-EN G_O from 5.75 to 6.68), but also induces cross-task synergy between text-to-image generation and editing. Collectively, these findings highlight autoregressive modeling, when paired with strong representations and preference optimization, as a scalable foundation for multimodal intelligence. Code: https://github.com/wdrink/ARM.
OmniGen-AR: AutoRegressive Any-to-Image Generation
Jun 08, 2026Autoregressive (AR) models have demonstrated strong potential in visual generation, offering superior performance with simple architectures and optimization objectives. However, existing methods are typically limited to single-modality conditions, e.g., text, restricting their applicability in real-world scenarios that demand image synthesis from diverse controls. In this work, we present OmniGen-AR, a unified autoregressive framework for Any-to-Image generation. By discretizing various visual conditions through a shared visual tokenizer and text prompts with a text tokenizer, OmniGen-AR supports a broad spectrum of conditional inputs within a single model, including text (text-to-image generation), spatial signals (segmentation-to-image and depth-to-image), and visual context (image editing, frame prediction, and text-to-video generation). To mitigate the risk of information leakage from condition tokens to content tokens, we introduce Disentangled Causal Attention (DCA), which separates the full-sequence causal mask into condition causal attention and content causal attention. It serves as a training-time regularizer without affecting the standard next-token prediction during inference. With this design, OmniGen-AR achieves new state-of-the-art or at least competitive results across a range of benchmark, e.g., 0.63 on GenEval and 80.02 on VBench, demonstrating its effectiveness in flexible and high-fidelity visual generation.
Context Unrolling in Omni Models
Apr 23, 2026We present Omni, a unified multimodal model natively trained on diverse modalities, including text, images, videos, 3D geometry, and hidden representations. We find that such training enables Context Unrolling, where the model explicitly reasons across multiple modal representations before producing predictions. This process enables the model to aggregate complementary information across heterogeneous modalities, facilitating a more faithful approximation of the shared multimodal knowledge manifold and improving downstream reasoning fidelity. As a result, Omni achieves strong performance on both multimodal generation and understanding benchmarks, while demonstrating advanced multimodal reasoning capabilities, including in-context generation of text, image, video, and 3D geometry.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
Mar 24, 2026Unified models capable of interleaved generation have emerged as a promising paradigm, with the community increasingly converging on autoregressive modeling for text and flow matching for image generation. To advance this direction, we propose a unified reinforcement learning framework tailored for interleaved generation. We validate our approach on its fundamental unit: a single round of reasoning-driven image generation, where the model first expands the user prompt through reasoning, followed by image synthesis. Formulating this multimodal generation process as a Markov Decision Process with sparse terminal rewards, we introduce UniGRPO to jointly optimize text and image generation policies using GRPO. Adopting a minimalist methodology to avoid over-design, we leverage established training recipes for both modalities by seamlessly integrating standard GRPO for reasoning and FlowGRPO for visual synthesis. To ensure scalability to multi-round interleaved generation, we introduce two critical modifications to the original FlowGRPO: (1) eliminating classifier-free guidance to maintain linear, unbranched rollouts, which is essential for scaling to complex scenarios involving multi-turn interactions and multi-condition generation (e.g., editing); and (2) replacing the standard latent KL penalty with an MSE penalty directly on the velocity fields, providing a more robust and direct regularization signal to mitigate reward hacking effectively. Our experiments demonstrate that this unified training recipe significantly enhances image generation quality through reasoning, providing a robust and scalable baseline for the future post-training of fully interleaved models.
NeuroLoRA: Context-Aware Neuromodulation for Parameter-Efficient Multi-Task Adaptation
Mar 12, 2026Parameter-Efficient Fine-Tuning (PEFT) techniques, particularly Low-Rank Adaptation (LoRA), have become essential for adapting Large Language Models (LLMs) to downstream tasks. While the recent FlyLoRA framework successfully leverages bio-inspired sparse random projections to mitigate parameter interference, it relies on a static, magnitude-based routing mechanism that is agnostic to input context. In this paper, we propose NeuroLoRA, a novel Mixture-of-Experts (MoE) based LoRA framework inspired by biological neuromodulation -- the dynamic regulation of neuronal excitability based on context. NeuroLoRA retains the computational efficiency of frozen random projections while introducing a lightweight, learnable neuromodulation gate that contextually rescales the projection space prior to expert selection. We further propose a Contrastive Orthogonality Loss to explicitly enforce separation between expert subspaces, enhancing both task decoupling and continual learning capacity. Extensive experiments on MMLU, GSM8K, and ScienceQA demonstrate that NeuroLoRA consistently outperforms FlyLoRA and other strong baselines across single-task adaptation, multi-task model merging, and sequential continual learning scenarios, while maintaining comparable parameter efficiency.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Dec 17, 2025
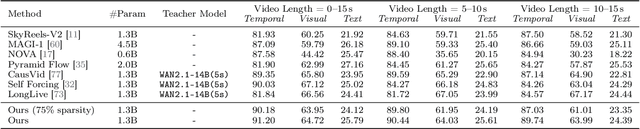
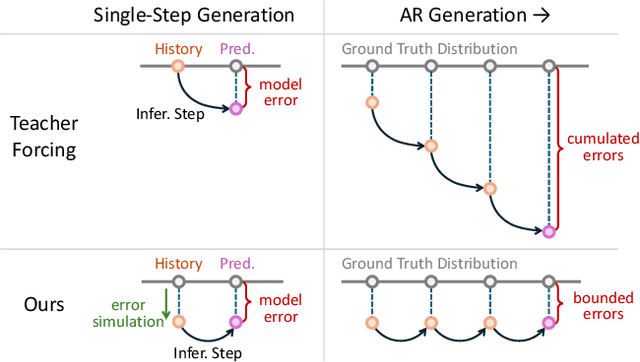

Autoregressive video diffusion models hold promise for world simulation but are vulnerable to exposure bias arising from the train-test mismatch. While recent works address this via post-training, they typically rely on a bidirectional teacher model or online discriminator. To achieve an end-to-end solution, we introduce Resampling Forcing, a teacher-free framework that enables training autoregressive video models from scratch and at scale. Central to our approach is a self-resampling scheme that simulates inference-time model errors on history frames during training. Conditioned on these degraded histories, a sparse causal mask enforces temporal causality while enabling parallel training with frame-level diffusion loss. To facilitate efficient long-horizon generation, we further introduce history routing, a parameter-free mechanism that dynamically retrieves the top-k most relevant history frames for each query. Experiments demonstrate that our approach achieves performance comparable to distillation-based baselines while exhibiting superior temporal consistency on longer videos owing to native-length training.
RewardDance: Reward Scaling in Visual Generation
Sep 10, 2025Reward Models (RMs) are critical for improving generation models via Reinforcement Learning (RL), yet the RM scaling paradigm in visual generation remains largely unexplored. It primarily due to fundamental limitations in existing approaches: CLIP-based RMs suffer from architectural and input modality constraints, while prevalent Bradley-Terry losses are fundamentally misaligned with the next-token prediction mechanism of Vision-Language Models (VLMs), hindering effective scaling. More critically, the RLHF optimization process is plagued by Reward Hacking issue, where models exploit flaws in the reward signal without improving true quality. To address these challenges, we introduce RewardDance, a scalable reward modeling framework that overcomes these barriers through a novel generative reward paradigm. By reformulating the reward score as the model's probability of predicting a "yes" token, indicating that the generated image outperforms a reference image according to specific criteria, RewardDance intrinsically aligns reward objectives with VLM architectures. This alignment unlocks scaling across two dimensions: (1) Model Scaling: Systematic scaling of RMs up to 26 billion parameters; (2) Context Scaling: Integration of task-specific instructions, reference examples, and chain-of-thought (CoT) reasoning. Extensive experiments demonstrate that RewardDance significantly surpasses state-of-the-art methods in text-to-image, text-to-video, and image-to-video generation. Crucially, we resolve the persistent challenge of "reward hacking": Our large-scale RMs exhibit and maintain high reward variance during RL fine-tuning, proving their resistance to hacking and ability to produce diverse, high-quality outputs. It greatly relieves the mode collapse problem that plagues smaller models.
Universal Video Temporal Grounding with Generative Multi-modal Large Language Models
Jun 23, 2025This paper presents a computational model for universal video temporal grounding, which accurately localizes temporal moments in videos based on natural language queries (e.g., questions or descriptions). Unlike existing methods that are often limited to specific video domains or durations, we propose UniTime, a robust and universal video grounding model leveraging the strong vision-language understanding capabilities of generative Multi-modal Large Language Models (MLLMs). Our model effectively handles videos of diverse views, genres, and lengths while comprehending complex language queries. The key contributions include: (i) We consider steering strong MLLMs for temporal grounding in videos. To enable precise timestamp outputs, we incorporate temporal information by interleaving timestamp tokens with video tokens. (ii) By training the model to handle videos with different input granularities through adaptive frame scaling, our approach achieves robust temporal grounding for both short and long videos. (iii) Comprehensive experiments show that UniTime outperforms state-of-the-art approaches in both zero-shot and dataset-specific finetuned settings across five public temporal grounding benchmarks. (iv) When employed as a preliminary moment retriever for long-form video question-answering (VideoQA), UniTime significantly improves VideoQA accuracy, highlighting its value for complex video understanding tasks.