 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADE: Frequency-Aware Diffusion Model Factorization for Video Editing
Jun 06, 2025Recent advancements in diffusion frameworks have significantly enhanced video editing, achieving high fidelity and strong alignment with textual prompts. However, conventional approaches using image diffusion models fall short in handling video dynamics, particularly for challenging temporal edits like motion adjustments. While current video diffusion models produce high-quality results, adapting them for efficient editing remains difficult due to the heavy computational demands that prevent the direct application of previous image editing techniques. To overcome these limitations, we introduce FADE, a training-free yet highly effective video editing approach that fully leverages the inherent priors from pre-trained video diffusion models via frequency-aware factorization. Rather than simply using these models, we first analyze the attention patterns within the video model to reveal how video priors are distributed across different components. Building on these insights, we propose a factorization strategy to optimize each component's specialized role. Furthermore, we devise spectrum-guided modulation to refine the sampling trajectory with frequency domain cues, preventing information leakage and supporting efficient, versatile edits while preserving the basic spatial and temporal structure. Extensive experiments on real-world videos demonstrate that our method consistently delivers high-quality, realistic and temporally coherent editing results both qualitatively and quantitatively. Code is available at https://github.com/EternalEvan/FADE .
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
May 08, 2025Recent progress in unified models for image understanding and generation has been impressive, yet most approaches remain limited to single-modal generation conditioned on multiple modalities. In this paper, we present Mogao, a unified framework that advances this paradigm by enabling interleaved multi-modal generation through a causal approach. Mogao integrates a set of key technical improvements in architecture design, including a deep-fusion design, dual vision encoders, interleaved rotary position embeddings, and multi-modal classifier-free guidance, which allow it to harness the strengths of both autoregressive models for text generation and diffusion models for high-quality image synthesis. These practical improvements also make Mogao particularly effective to process interleaved sequences of text and images arbitrarily. To further unlock the potential of unified models, we introduce an efficient training strategy on a large-scale, in-house dataset specifically curated for joint text and image generation. Extensive experiments show that Mogao not only achieves state-of-the-art performance in multi-modal understanding and text-to-image generation, but also excels in producing high-quality, coherent interleaved outputs. Its emergent capabilities in zero-shot image editing and compositional generation highlight Mogao as a practical omni-modal foundation model, paving the way for future development and scaling the unified multi-modal systems.
InstaRevive: One-Step Image Enhancement via Dynamic Score Matching
Apr 22, 2025
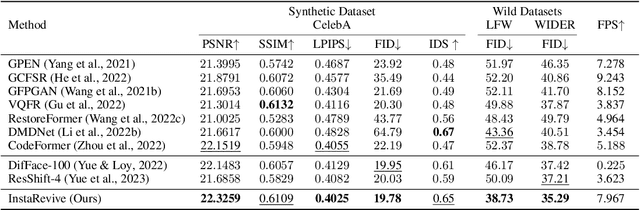
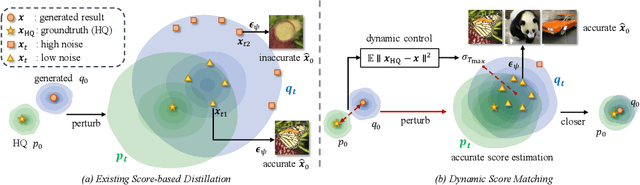
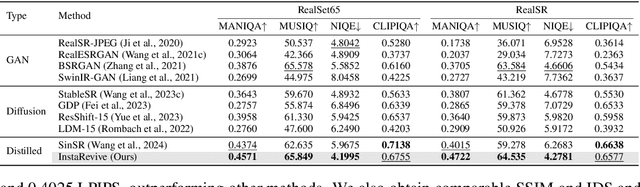
Image enhancement finds wide-ranging applications in real-world scenarios due to complex environments and the inherent limitations of imaging devices. Recent diffusion-based methods yield promising outcomes but necessitate prolonged and computationally intensive iterative sampling. In response, we propose InstaRevive, a straightforward yet powerful image enhancement framework that employs score-based diffusion distillation to harness potent generative capability and minimize the sampling steps. To fully exploit the potential of the pre-trained diffusion model, we devise a practical and effective diffusion distillation pipeline using dynamic control to address inaccuracies in updating direction during score matching. Our control strategy enables a dynamic diffusing scope, facilitating precise learning of denoising trajectories within the diffusion model and ensuring accurate distribution matching gradients during training. Additionally, to enrich guidance for the generative power, we incorporate textual prompts via image captioning as auxiliary conditions, fostering further exploration of the diffusion model. Extensive experiments substantiate the efficacy of our framework across a diverse array of challenging tasks and datasets, unveiling the compelling efficacy and efficiency of InstaRevive in delivering high-quality and visually appealing results. Code is available at https://github.com/EternalEvan/InstaRevive.
DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
Mar 18, 2025Diffusion models have demonstrated remarkable success in various image generation tasks, but their performance is often limited by the uniform processing of inputs across varying conditions and noise levels. To address this limitation, we propose a novel approach that leverages the inherent heterogeneity of the diffusion process. Our method, DiffMoE, introduces a batch-level global token pool that enables experts to access global token distributions during training, promoting specialized expert behavior. To unleash the full potential of the diffusion process, DiffMoE incorporates a capacity predictor that dynamically allocates computational resources based on noise levels and sample complexity. Through comprehensive evaluation, DiffMoE achieves state-of-the-art performance among diffusion models on ImageNet benchmark, substantially outperforming both dense architectures with 3x activated parameters and existing MoE approaches while maintaining 1x activated parameters. The effectiveness of our approach extends beyond class-conditional generation to more challenging tasks such as text-to-image generation, demonstrating its broad applicability across different diffusion model applications. Project Page: https://shiml20.github.io/DiffMoE/
FlowTurbo: Towards Real-time Flow-Based Image Generation with Velocity Refiner
Sep 26, 2024Building on the success of diffusion models in visual generation, flow-based models reemerge as another prominent family of generative models that have achieved competitive or better performance in terms of both visual quality and inference speed. By learning the velocity field through flow-matching, flow-based models tend to produce a straighter sampling trajectory, which is advantageous during the sampling process. However, unlike diffusion models for which fast samplers are well-developed, efficient sampling of flow-based generative models has been rarely explored. In this paper, we propose a framework called FlowTurbo to accelerate the sampling of flow-based models while still enhancing the sampling quality. Our primary observation is that the velocity predictor's outputs in the flow-based models will become stable during the sampling, enabling the estimation of velocity via a lightweight velocity refiner. Additionally, we introduce several techniques including a pseudo corrector and sample-aware compilation to further reduce inference time. Since FlowTurbo does not change the multi-step sampling paradigm, it can be effectively applied for various tasks such as image editing, inpainting, etc. By integrating FlowTurbo into different flow-based models, we obtain an acceleration ratio of 53.1%$\sim$58.3% on class-conditional generation and 29.8%$\sim$38.5% on text-to-image generation. Notably, FlowTurbo reaches an FID of 2.12 on ImageNet with 100 (ms / img) and FID of 3.93 with 38 (ms / img), achieving the real-time image generation and establishing the new state-of-the-art. Code is available at https://github.com/shiml20/FlowTurbo.
DC-Solver: Improving Predictor-Corrector Diffusion Sampler via Dynamic Compensation
Sep 05, 2024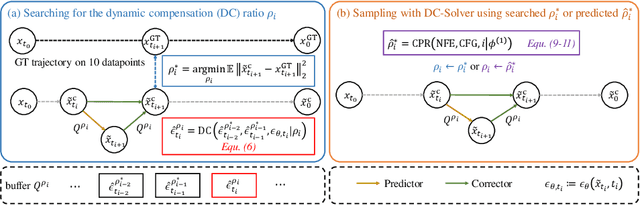
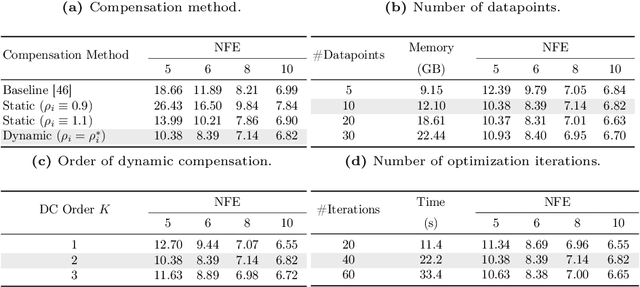

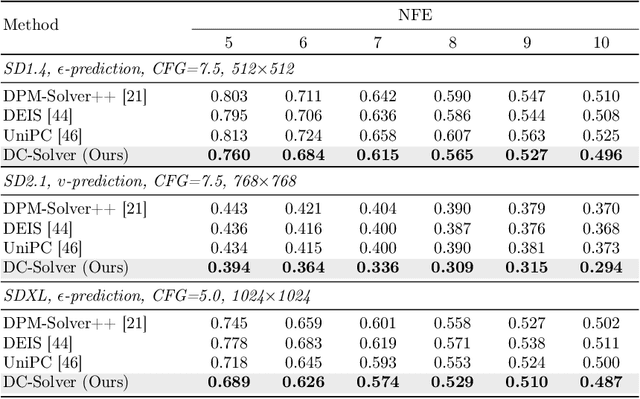
Diffusion probabilistic models (DPMs) have shown remarkable performance in visual synthesis but are computationally expensive due to the need for multiple evaluations during the sampling. Recent predictor-corrector diffusion samplers have significantly reduced the required number of function evaluations (NFE), but inherently suffer from a misalignment issue caused by the extra corrector step, especially with a large classifier-free guidance scale (CFG). In this paper, we introduce a new fast DPM sampler called DC-Solver, which leverages dynamic compensation (DC) to mitigate the misalignment of the predictor-corrector samplers. The dynamic compensation is controlled by compensation ratios that are adaptive to the sampling steps and can be optimized on only 10 datapoints by pushing the sampling trajectory toward a ground truth trajectory. We further propose a cascade polynomial regression (CPR) which can instantly predict the compensation ratios on unseen sampling configurations. Additionally, we find that the proposed dynamic compensation can also serve as a plug-and-play module to boost the performance of predictor-only samplers. Extensive experiments on both unconditional sampling and conditional sampling demonstrate that our DC-Solver can consistently improve the sampling quality over previous methods on different DPMs with a wide range of resolutions up to 1024$\times$1024. Notably, we achieve 10.38 FID (NFE=5) on unconditional FFHQ and 0.394 MSE (NFE=5, CFG=7.5) on Stable-Diffusion-2.1. Code is available at https://github.com/wl-zhao/DC-Solver
FlowIE: Efficient Image Enhancement via Rectified Flow
Jun 01, 2024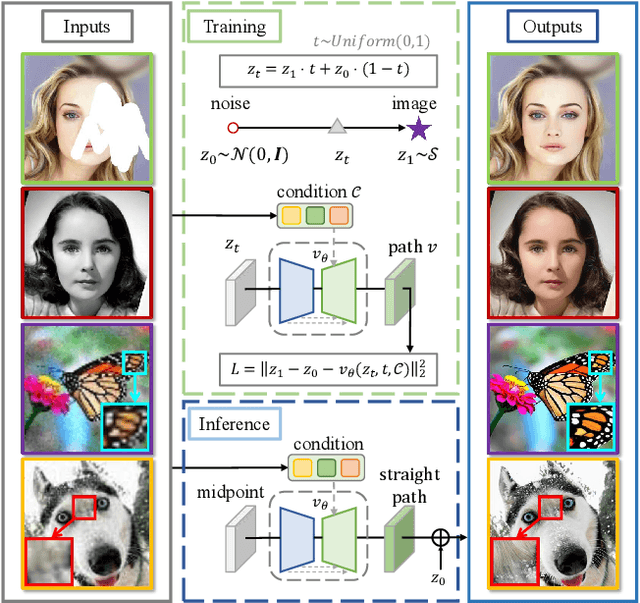
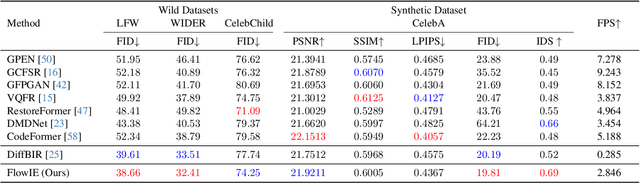

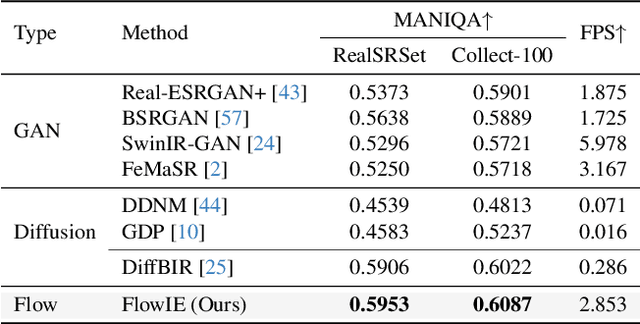
Image enhancement holds extensive applications in real-world scenarios due to complex environments and limitations of imaging devices. Conventional methods are often constrained by their tailored models, resulting in diminished robustness when confronted with challenging degradation conditions. In response, we propose FlowIE, a simple yet highly effective flow-based image enhancement framework that estimates straight-line paths from an elementary distribution to high-quality images. Unlike previous diffusion-based methods that suffer from long-time inference, FlowIE constructs a linear many-to-one transport mapping via conditioned rectified flow. The rectification straightens the trajectories of probability transfer, accelerating inference by an order of magnitude. This design enables our FlowIE to fully exploit rich knowledge in the pre-trained diffusion model, rendering it well-suited for various real-world applications. Moreover, we devise a faster inference algorithm, inspired by Lagrange's Mean Value Theorem, harnessing midpoint tangent direction to optimize path estimation, ultimately yielding visually superior results. Thanks to these designs, our FlowIE adeptly manages a diverse range of enhancement tasks within a concise sequence of fewer than 5 steps. Our contributions are rigorously validated through comprehensive experiments on synthetic and real-world datasets, unveiling the compelling efficacy and efficiency of our proposed FlowIE. Code is available at https://github.com/EternalEvan/FlowIE.
DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
Apr 01, 2024



The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.
MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers
Dec 19, 2023



Recent advances in generative AI have significantly enhanced image and video editing, particularly in the context of text prompt control. State-of-the-art approaches predominantly rely on diffusion models to accomplish these tasks. However, the computational demands of diffusion-based methods are substantial, often necessitating large-scale paired datasets for training, and therefore challenging the deployment in practical applications. This study addresses this challenge by breaking down the text-based video editing process into two separate stages. In the first stage, we leverage an existing text-to-image diffusion model to simultaneously edit a few keyframes without additional fine-tuning. In the second stage, we introduce an efficient model called MaskINT, which is built on non-autoregressive masked generative transformers and specializes in frame interpolation between the keyframes, benefiting from structural guidance provided by intermediate frames. Our comprehensive set of experiments illustrates the efficacy and efficiency of MaskINT when compared to other diffusion-based methodologies. This research offers a practical solution for text-based video editing and showcases the potential of non-autoregressive masked generative transformers in this domain.
OpenVoice: Versatile Instant Voice Cloning
Dec 03, 2023We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.ai.