 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeMFL-240K: A Large-scale Dataset and Benchmark for Object Detection in Pipeline Magnetic Flux Leakage Imaging
Feb 04, 2026Pipeline integrity is critical to industrial safety and environmental protection, with Magnetic Flux Leakage (MFL) detection being a primary non-destructive testing technology. Despite the promise of deep learning for automating MFL interpretation, progress toward reliable models has been constrained by the absence of a large-scale public dataset and benchmark, making fair comparison and reproducible evaluation difficult. We introduce \textbf{PipeMFL-240K}, a large-scale, meticulously annotated dataset and benchmark for complex object detection in pipeline MFL pseudo-color images. PipeMFL-240K reflects real-world inspection complexity and poses several unique challenges: (i) an extremely long-tailed distribution over \textbf{12} categories, (ii) a high prevalence of tiny objects that often comprise only a handful of pixels, and (iii) substantial intra-class variability. The dataset contains \textbf{240,320} images and \textbf{191,530} high-quality bounding-box annotations, collected from 11 pipelines spanning approximately \textbf{1,480} km. Extensive experiments are conducted with state-of-the-art object detectors to establish baselines. Results show that modern detectors still struggle with the intrinsic properties of MFL data, highlighting considerable headroom for improvement, while PipeMFL-240K provides a reliable and challenging testbed to drive future research. As the first public dataset and the first benchmark of this scale and scope for pipeline MFL inspection, it provides a critical foundation for efficient pipeline diagnostics as well as maintenance planning and is expected to accelerate algorithmic innovation and reproducible research in MFL-based pipeline integrity assessment.
SVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
Dec 12, 2025Visual generation grounded in Visual Foundation Model (VFM) representations offers a highly promising unified pathway for integrating visual understanding, perception, and generation. Despite this potential, training large-scale text-to-image diffusion models entirely within the VFM representation space remains largely unexplored. To bridge this gap, we scale the SVG (Self-supervised representations for Visual Generation) framework, proposing SVG-T2I to support high-quality text-to-image synthesis directly in the VFM feature domain. By leveraging a standard text-to-image diffusion pipeline, SVG-T2I achieves competitive performance, reaching 0.75 on GenEval and 85.78 on DPG-Bench. This performance validates the intrinsic representational power of VFMs for generative tasks. We fully open-source the project, including the autoencoder and generation model, together with their training, inference, evaluation pipelines, and pre-trained weights, to facilitate further research in representation-driven visual generation.
Sparse3DPR: Training-Free 3D Hierarchical Scene Parsing and Task-Adaptive Subgraph Reasoning from Sparse RGB Views
Nov 11, 2025Recently, large language models (LLMs) have been explored widely for 3D scene understanding. Among them, training-free approaches are gaining attention for their flexibility and generalization over training-based methods. However, they typically struggle with accuracy and efficiency in practical deployment. To address the problems, we propose Sparse3DPR, a novel training-free framework for open-ended scene understanding, which leverages the reasoning capabilities of pre-trained LLMs and requires only sparse-view RGB inputs. Specifically, we introduce a hierarchical plane-enhanced scene graph that supports open vocabulary and adopts dominant planar structures as spatial anchors, which enables clearer reasoning chains and more reliable high-level inferences. Furthermore, we design a task-adaptive subgraph extraction method to filter query-irrelevant information dynamically, reducing contextual noise and improving 3D scene reasoning efficiency and accuracy. Experimental results demonstrate the superiority of Sparse3DPR, which achieves a 28.7% EM@1 improvement and a 78.2% speedup compared with ConceptGraphs on the Space3D-Bench. Moreover, Sparse3DPR obtains comparable performance to training-based methods on ScanQA, with additional real-world experiments confirming its robustness and generalization capability.
Deep Learning for Crack Detection: A Review of Learning Paradigms, Generalizability, and Datasets
Aug 14, 2025Crack detection plays a crucial role in civil infrastructures, including inspection of pavements, buildings, etc., and deep learning has significantly advanced this field in recent years. While numerous technical and review papers exist in this domain, emerging trends are reshaping the landscape. These shifts include transitions in learning paradigms (from fully supervised learning to semi-supervised, weakly-supervised, unsupervised, few-shot, domain adaptation and fine-tuning foundation models), improvements in generalizability (from single-dataset performance to cross-dataset evaluation), and diversification in dataset reacquisition (from RGB images to specialized sensor-based data). In this review, we systematically analyze these trends and highlight representative works. Additionally, we introduce a new dataset collected with 3D laser scans, 3DCrack, to support future research and conduct extensive benchmarking experiments to establish baselines for commonly used deep learning methodologies, including recent foundation models. Our findings provide insights into the evolving methodologies and future directions in deep learning-based crack detection. Project page: https://github.com/nantonzhang/Awesome-Crack-Detection
FADE: Frequency-Aware Diffusion Model Factorization for Video Editing
Jun 06, 2025Recent advancements in diffusion frameworks have significantly enhanced video editing, achieving high fidelity and strong alignment with textual prompts. However, conventional approaches using image diffusion models fall short in handling video dynamics, particularly for challenging temporal edits like motion adjustments. While current video diffusion models produce high-quality results, adapting them for efficient editing remains difficult due to the heavy computational demands that prevent the direct application of previous image editing techniques. To overcome these limitations, we introduce FADE, a training-free yet highly effective video editing approach that fully leverages the inherent priors from pre-trained video diffusion models via frequency-aware factorization. Rather than simply using these models, we first analyze the attention patterns within the video model to reveal how video priors are distributed across different components. Building on these insights, we propose a factorization strategy to optimize each component's specialized role. Furthermore, we devise spectrum-guided modulation to refine the sampling trajectory with frequency domain cues, preventing information leakage and supporting efficient, versatile edits while preserving the basic spatial and temporal structure. Extensive experiments on real-world videos demonstrate that our method consistently delivers high-quality, realistic and temporally coherent editing results both qualitatively and quantitatively. Code is available at https://github.com/EternalEvan/FADE .
InstaRevive: One-Step Image Enhancement via Dynamic Score Matching
Apr 22, 2025
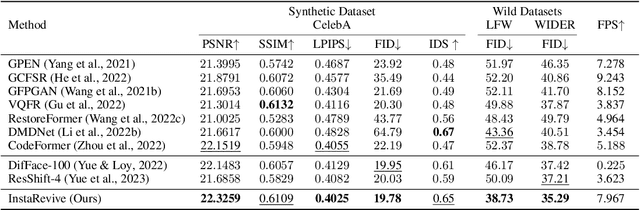
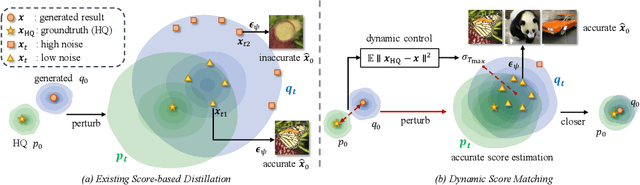
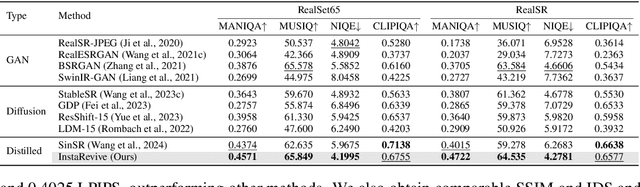
Image enhancement finds wide-ranging applications in real-world scenarios due to complex environments and the inherent limitations of imaging devices. Recent diffusion-based methods yield promising outcomes but necessitate prolonged and computationally intensive iterative sampling. In response, we propose InstaRevive, a straightforward yet powerful image enhancement framework that employs score-based diffusion distillation to harness potent generative capability and minimize the sampling steps. To fully exploit the potential of the pre-trained diffusion model, we devise a practical and effective diffusion distillation pipeline using dynamic control to address inaccuracies in updating direction during score matching. Our control strategy enables a dynamic diffusing scope, facilitating precise learning of denoising trajectories within the diffusion model and ensuring accurate distribution matching gradients during training. Additionally, to enrich guidance for the generative power, we incorporate textual prompts via image captioning as auxiliary conditions, fostering further exploration of the diffusion model. Extensive experiments substantiate the efficacy of our framework across a diverse array of challenging tasks and datasets, unveiling the compelling efficacy and efficiency of InstaRevive in delivering high-quality and visually appealing results. Code is available at https://github.com/EternalEvan/InstaRevive.
Empowering LLMs in Decision Games through Algorithmic Data Synthesis
Mar 18, 2025
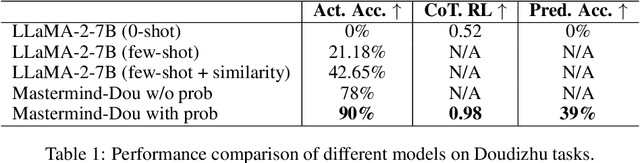
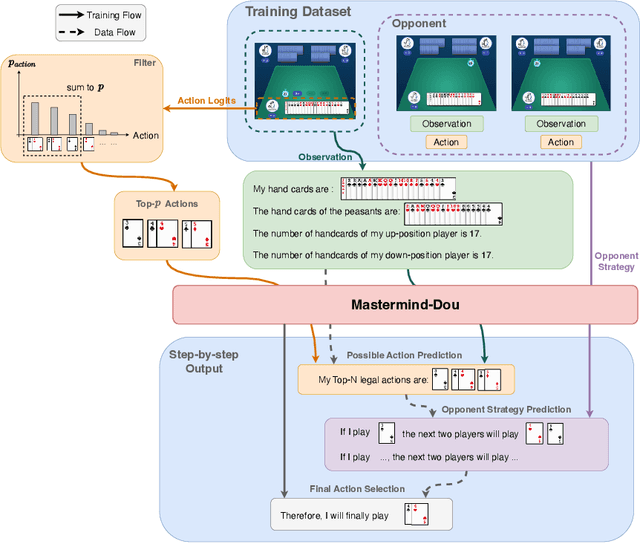

Large Language Models (LLMs) have exhibited impressive capabilities across numerous domains, yet they often struggle with complex reasoning and decision-making tasks. Decision-making games, which inherently require multifaceted reasoning logic, serve as ideal sandboxes for evaluating and enhancing the reasoning abilities of LLMs. In this work, we first explore whether LLMs can master complex decision-making games through targeted post-training. To this end, we design data synthesis strategies and curate extensive offline datasets from two classic games, Doudizhu and Go. We further develop a suite of techniques to effectively incorporate this data into LLM training, resulting in two novel agents: Mastermind-Dou and Mastermind-Go. Our experimental results demonstrate that these Mastermind LLMs achieve competitive performance in their respective games. Additionally, we explore whether integrating decision-making data can enhance the general reasoning abilities of LLMs. Our findings suggest that such post-training improves certain aspects of reasoning, providing valuable insights for optimizing LLM data collection and synthesis strategies.
Triad: Empowering LMM-based Anomaly Detection with Vision Expert-guided Visual Tokenizer and Manufacturing Process
Mar 17, 2025
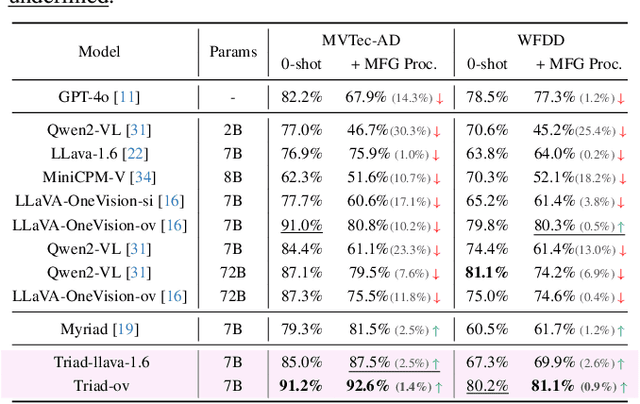
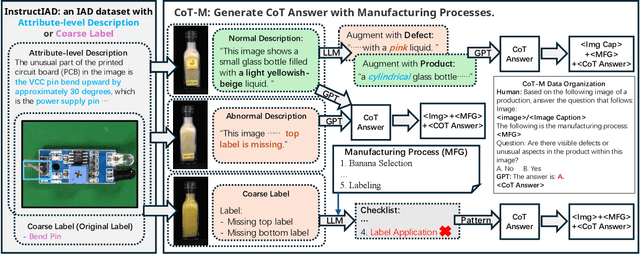
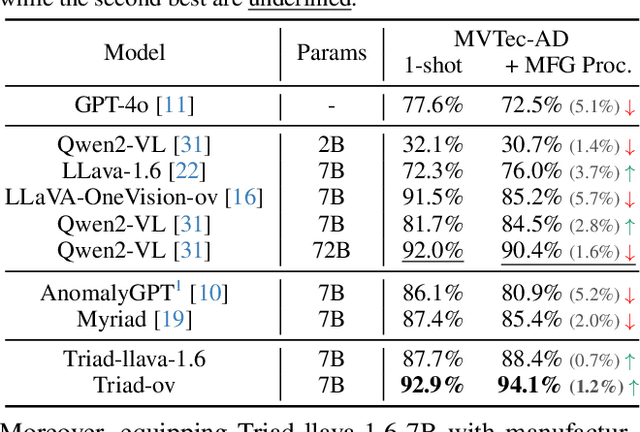
Although recent methods have tried to introduce large multimodal models (LMMs) into industrial anomaly detection (IAD), their generalization in the IAD field is far inferior to that for general purposes. We summarize the main reasons for this gap into two aspects. On one hand, general-purpose LMMs lack cognition of defects in the visual modality, thereby failing to sufficiently focus on defect areas. Therefore, we propose to modify the AnyRes structure of the LLaVA model, providing the potential anomalous areas identified by existing IAD models to the LMMs. On the other hand, existing methods mainly focus on identifying defects by learning defect patterns or comparing with normal samples, yet they fall short of understanding the causes of these defects. Considering that the generation of defects is closely related to the manufacturing process, we propose a manufacturing-driven IAD paradigm. An instruction-tuning dataset for IAD (InstructIAD) and a data organization approach for Chain-of-Thought with manufacturing (CoT-M) are designed to leverage the manufacturing process for IAD. Based on the above two modifications, we present Triad, a novel LMM-based method incorporating an expert-guided region-of-interest tokenizer and manufacturing process for industrial anomaly detection. Extensive experiments show that our Triad not only demonstrates competitive performance against current LMMs but also achieves further improved accuracy when equipped with manufacturing processes. Source code, training data, and pre-trained models will be publicly available at https://github.com/tzjtatata/Triad.
Layer Separation: Adjustable Joint Space Width Images Synthesis in Conventional Radiography
Feb 04, 2025Rheumatoid arthritis (RA) is a chronic autoimmune disease characterized by joint inflammation and progressive structural damage. Joint space width (JSW) is a critical indicator in conventional radiography for evaluating disease progression, which has become a prominent research topic in computer-aided diagnostic (CAD) systems. However, deep learning-based radiological CAD systems for JSW analysis face significant challenges in data quality, including data imbalance, limited variety, and annotation difficulties. This work introduced a challenging image synthesis scenario and proposed Layer Separation Networks (LSN) to accurately separate the soft tissue layer, the upper bone layer, and the lower bone layer in conventional radiographs of finger joints. Using these layers, the adjustable JSW images can be synthesized to address data quality challenges and achieve ground truth (GT) generation. Experimental results demonstrated that LSN-based synthetic images closely resemble real radiographs, and significantly enhanced the performance in downstream tasks. The code and dataset will be available.
Retrieval Augmented Image Harmonization
Dec 18, 2024



When embedding objects (foreground) into images (background), considering the influence of photography conditions like illumination, it is usually necessary to perform image harmonization to make the foreground object coordinate with the background image in terms of brightness, color, and etc. Although existing image harmonization methods have made continuous efforts toward visually pleasing results, they are still plagued by two main issues. Firstly, the image harmonization becomes highly ill-posed when there are no contents similar to the foreground object in the background, making the harmonization results unreliable. Secondly, even when similar contents are available, the harmonization process is often interfered with by irrelevant areas, mainly attributed to an insufficient understanding of image contents and inaccurate attention. As a remedy, we present a retrieval-augmented image harmonization (Raiha) framework, which seeks proper reference images to reduce the ill-posedness and restricts the attention to better utilize the useful information. Specifically, an efficient retrieval method is designed to find reference images that contain similar objects as the foreground while the illumination is consistent with the background. For training the Raiha framework to effectively utilize the reference information, a data augmentation strategy is delicately designed by leveraging existing non-reference image harmonization datasets. Besides, the image content priors are introduced to ensure reasonable attention. With the presented Raiha framework, the image harmonization performance is greatly boosted under both non-reference and retrieval-augmented settings. The source code and pre-trained models will be publicly available.