 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Involvement in Robotic Wheelchair Development: A Decade of Limited Progress
Mar 27, 2026Robotic wheelchairs (RWs) offer significant potential to enhance autonomy and participation for people with mobility impairments, yet many systems have failed to achieve sustained real-world adoption. This narrative literature review examined the extent and quality of end-user involvement in RW design, development, and evaluation over the past decade (2015--2025), assessed against core principles shared by major user-involvement approaches (e.g., user-/human-centered design, participatory/co-design, and inclusive design). The findings indicate that user involvement remains limited and is predominantly concentrated in late-stage evaluation rather than in early requirements definition or iterative co-design. Of the 399 records screened, only 23 studies (about 6%) met the inclusion criteria of verifiable end-user involvement, and many relied on small samples, often around ten participants, with limited justification for sample size selection, proxy users, laboratory-based validation, and non-standardized feedback methods. Research teams were largely engineering-dominated (about 89%) and geographically concentrated in high-income countries. Despite strong evidence that sustained user engagement improves usability and adoption in assistive technology, its systematic implementation in RW research remains rare. Advancing the field requires embedding participatory methodologies throughout the design lifecycle and addressing systemic barriers that constrain meaningful user involvement.
Multi-AD: Cross-Domain Unsupervised Anomaly Detection for Medical and Industrial Applications
Feb 05, 2026Traditional deep learning models often lack annotated data, especially in cross-domain applications such as anomaly detection, which is critical for early disease diagnosis in medicine and defect detection in industry. To address this challenge, we propose Multi-AD, a convolutional neural network (CNN) model for robust unsupervised anomaly detection across medical and industrial images. Our approach employs the squeeze-and-excitation (SE) block to enhance feature extraction via channel-wise attention, enabling the model to focus on the most relevant features and detect subtle anomalies. Knowledge distillation (KD) transfers informative features from the teacher to the student model, enabling effective learning of the differences between normal and anomalous data. Then, the discriminator network further enhances the model's capacity to distinguish between normal and anomalous data. At the inference stage, by integrating multi-scale features, the student model can detect anomalies of varying sizes. The teacher-student (T-S) architecture ensures consistent representation of high-dimensional features while adapting them to enhance anomaly detection. Multi-AD was evaluated on several medical datasets, including brain MRI, liver CT, and retina OCT, as well as industrial datasets, such as MVTec AD, demonstrating strong generalization across multiple domains. Experimental results demonstrated that our approach consistently outperformed state-of-the-art models, achieving the best average AUROC for both image-level (81.4% for medical and 99.6% for industrial) and pixel-level (97.0% for medical and 98.4% for industrial) tasks, making it effective for real-world applications.
* 28 pages, 8 figures
FaceCrafter: Identity-Conditional Diffusion with Disentangled Control over Facial Pose, Expression, and Emotion
May 21, 2025Human facial images encode a rich spectrum of information, encompassing both stable identity-related traits and mutable attributes such as pose, expression, and emotion. While recent advances in image generation have enabled high-quality identity-conditional face synthesis, precise control over non-identity attributes remains challenging, and disentangling identity from these mutable factors is particularly difficult. To address these limitations, we propose a novel identity-conditional diffusion model that introduces two lightweight control modules designed to independently manipulate facial pose, expression, and emotion without compromising identity preservation. These modules are embedded within the cross-attention layers of the base diffusion model, enabling precise attribute control with minimal parameter overhead. Furthermore, our tailored training strategy, which leverages cross-attention between the identity feature and each non-identity control feature, encourages identity features to remain orthogonal to control signals, enhancing controllability and diversity. Quantitative and qualitative evaluations, along with perceptual user studies, demonstrate that our method surpasses existing approaches in terms of control accuracy over pose, expression, and emotion, while also improving generative diversity under identity-only conditioning.
Layer Separation: Adjustable Joint Space Width Images Synthesis in Conventional Radiography
Feb 04, 2025Rheumatoid arthritis (RA) is a chronic autoimmune disease characterized by joint inflammation and progressive structural damage. Joint space width (JSW) is a critical indicator in conventional radiography for evaluating disease progression, which has become a prominent research topic in computer-aided diagnostic (CAD) systems. However, deep learning-based radiological CAD systems for JSW analysis face significant challenges in data quality, including data imbalance, limited variety, and annotation difficulties. This work introduced a challenging image synthesis scenario and proposed Layer Separation Networks (LSN) to accurately separate the soft tissue layer, the upper bone layer, and the lower bone layer in conventional radiographs of finger joints. Using these layers, the adjustable JSW images can be synthesized to address data quality challenges and achieve ground truth (GT) generation. Experimental results demonstrated that LSN-based synthetic images closely resemble real radiographs, and significantly enhanced the performance in downstream tasks. The code and dataset will be available.
VariFace: Fair and Diverse Synthetic Dataset Generation for Face Recognition
Dec 09, 2024

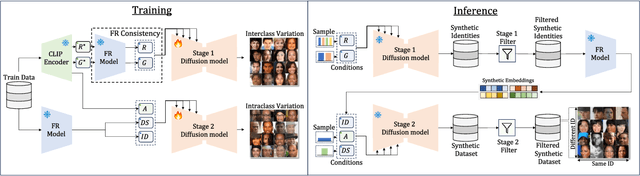

The use of large-scale, web-scraped datasets to train face recognition models has raised significant privacy and bias concerns. Synthetic methods mitigate these concerns and provide scalable and controllable face generation to enable fair and accurate face recognition. However, existing synthetic datasets display limited intraclass and interclass diversity and do not match the face recognition performance obtained using real datasets. Here, we propose VariFace, a two-stage diffusion-based pipeline to create fair and diverse synthetic face datasets to train face recognition models. Specifically, we introduce three methods: Face Recognition Consistency to refine demographic labels, Face Vendi Score Guidance to improve interclass diversity, and Divergence Score Conditioning to balance the identity preservation-intraclass diversity trade-off. When constrained to the same dataset size, VariFace considerably outperforms previous synthetic datasets (0.9200 $\rightarrow$ 0.9405) and achieves comparable performance to face recognition models trained with real data (Real Gap = -0.0065). In an unconstrained setting, VariFace not only consistently achieves better performance compared to previous synthetic methods across dataset sizes but also, for the first time, outperforms the real dataset (CASIA-WebFace) across six evaluation datasets. This sets a new state-of-the-art performance with an average face verification accuracy of 0.9567 (Real Gap = +0.0097) across LFW, CFP-FP, CPLFW, AgeDB, and CALFW datasets and 0.9366 (Real Gap = +0.0380) on the RFW dataset.
BLS-GAN: A Deep Layer Separation Framework for Eliminating Bone Overlap in Conventional Radiographs
Sep 11, 2024Conventional radiography is the widely used imaging technology in diagnosing, monitoring, and prognosticating musculoskeletal (MSK) diseases because of its easy availability, versatility, and cost-effectiveness. In conventional radiographs, bone overlaps are prevalent, and can impede the accurate assessment of bone characteristics by radiologists or algorithms, posing significant challenges to conventional and computer-aided diagnoses. This work initiated the study of a challenging scenario - bone layer separation in conventional radiographs, in which separate overlapped bone regions enable the independent assessment of the bone characteristics of each bone layer and lay the groundwork for MSK disease diagnosis and its automation. This work proposed a Bone Layer Separation GAN (BLS-GAN) framework that can produce high-quality bone layer images with reasonable bone characteristics and texture. This framework introduced a reconstructor based on conventional radiography imaging principles, which achieved efficient reconstruction and mitigates the recurrent calculations and training instability issues caused by soft tissue in the overlapped regions. Additionally, pre-training with synthetic images was implemented to enhance the stability of both the training process and the results. The generated images passed the visual Turing test, and improved performance in downstream tasks. This work affirms the feasibility of extracting bone layer images from conventional radiographs, which holds promise for leveraging bone layer separation technology to facilitate more comprehensive analytical research in MSK diagnosis, monitoring, and prognosis. Code and dataset will be made available.
Federated Active Learning Framework for Efficient Annotation Strategy in Skin-lesion Classification
Jun 17, 2024



Federated Learning (FL) enables multiple institutes to train models collaboratively without sharing private data. Current FL research focuses on communication efficiency, privacy protection, and personalization and assumes that the data of FL have already been ideally collected. In medical scenarios, however, data annotation demands both expertise and intensive labor, which is a critical problem in FL. Active learning (AL), has shown promising performance in reducing the number of data annotations in medical image analysis. We propose a federated AL (FedAL) framework in which AL is executed periodically and interactively under FL. We exploit a local model in each hospital and a global model acquired from FL to construct an ensemble. We use ensemble-entropy-based AL as an efficient data-annotation strategy in FL. Therefore, our FedAL framework can decrease the amount of annotated data and preserve patient privacy while maintaining the performance of FL. To our knowledge, this is the first FedAL framework applied to medical images. We validated our framework on real-world dermoscopic datasets. Using only 50% of samples, our framework was able to achieve state-of-the-art performance on a skin-lesion classification task. Our framework performed better than several state-of-the-art AL methods under FL and achieved comparable performance to full-data FL.
MDA: An Interpretable Multi-Modal Fusion with Missing Modalities and Intrinsic Noise
Jun 15, 2024


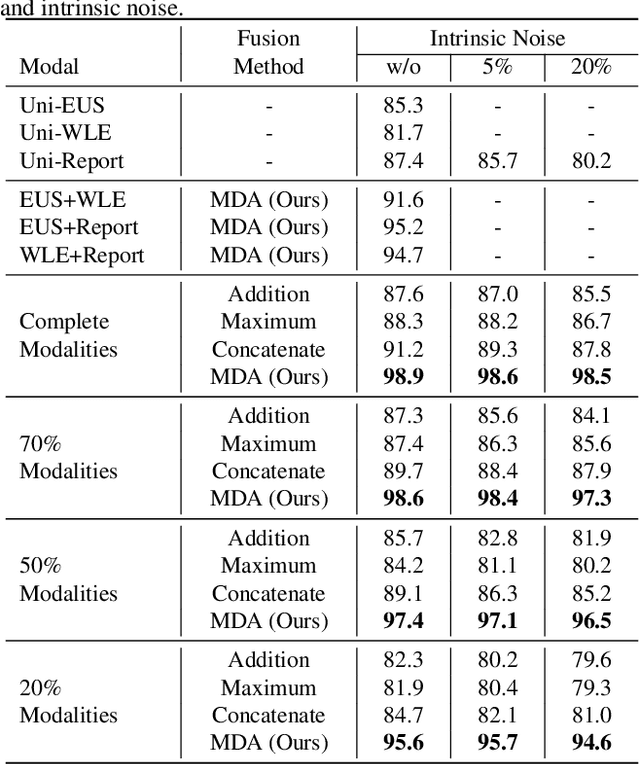
Multi-modal fusion is crucial in medical data research, enabling a comprehensive understanding of diseases and improving diagnostic performance by combining diverse modalities. However, multi-modal fusion faces challenges, including capturing interactions between modalities, addressing missing modalities, handling erroneous modal information, and ensuring interpretability. Many existing researchers tend to design different solutions for these problems, often overlooking the commonalities among them. This paper proposes a novel multi-modal fusion framework that achieves adaptive adjustment over the weights of each modality by introducing the Modal-Domain Attention (MDA). It aims to facilitate the fusion of multi-modal information while allowing for the inclusion of missing modalities or intrinsic noise, thereby enhancing the representation of multi-modal data. We provide visualizations of accuracy changes and MDA weights by observing the process of modal fusion, offering a comprehensive analysis of its interpretability. Extensive experiments on various gastrointestinal disease benchmarks, the proposed MDA maintains high accuracy even in the presence of missing modalities and intrinsic noise. One thing worth mentioning is that the visualization of MDA is highly consistent with the conclusions of existing clinical studies on the dependence of different diseases on various modalities. Code and dataset will be made available.
A Neck Orthosis with Multi-Directional Variable Stiffness for Persons with Dropped Head Syndrome
Jun 11, 2024



Dropped Head Syndrome (DHS) causes a passively correctable neck deformation. Currently, there is no wearable orthopedic neck brace to fulfill the needs of persons suffering from DHS. Related works have made progress in this area by creating mobile neck braces that provide head support to mitigate deformation while permitting neck mobility, which enhances user-perceived comfort and quality of life. Specifically, passive designs show great potential for fully functional devices in the short term due to their inherent simplicity and compactness, although achieving suitable support presents some challenges. This work introduces a novel compliant mechanism that provides non-restrictive adjustable support for the neck's anterior and posterior flexion movements while enabling its unconstrained free rotation. The results from the experiments on non-affected persons suggest that the device provides the proposed adjustable support that unloads the muscle groups involved in supporting the head without overloading the antagonist muscle groups. Simultaneously, it was verified that the free rotation is achieved regardless of the stiffness configuration of the device.
* Accepted Manuscript
Torso-Based Control Interface for Standing Mobility-Assistive Devices
Dec 04, 2023



Wheelchairs and mobility devices have transformed our bodies into cybernic systems, extending our well-being by enabling individuals with reduced mobility to regain freedom. Notwithstanding, current interfaces of control require to use the hands, therefore constraining the user from performing functional activities of daily living. In this work, we present a unique design of torso-based control interface with compliant coupling support for standing mobility assistive devices. We take the coupling between the human and robot into consideration in the interface design. The design includes a compliant support mechanism and a mapping between the body movement space and the velocity space. We present experiments including multiple conditions, with a joystick for comparison with the proposed torso control interface. The results of a path-following experiment showed that users were able to control the device naturally using the hands-free interface, and the performance was comparable with the joystick, with 10% more consumed time, an average cross error of 0.116 m and 4.9% less average acceleration. The result of an object-transferring experiment showed the advantage of using the proposed interface in case users needed to manipulate objects while locomotion. The torso control scored 15% less in the System Usability Scale than the joystick in the path following task but 3.3% more in the object transferring task.