 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTri-VQA: Triangular Reasoning Medical Visual Question Answering for Multi-Attribute Analysis
Jun 21, 2024



The intersection of medical Visual Question Answering (Med-VQA) is a challenging research topic with advantages including patient engagement and clinical expert involvement for second opinions. However, existing Med-VQA methods based on joint embedding fail to explain whether their provided results are based on correct reasoning or coincidental answers, which undermines the credibility of VQA answers. In this paper, we investigate the construction of a more cohesive and stable Med-VQA structure. Motivated by causal effect, we propose a novel Triangular Reasoning VQA (Tri-VQA) framework, which constructs reverse causal questions from the perspective of "Why this answer?" to elucidate the source of the answer and stimulate more reasonable forward reasoning processes. We evaluate our method on the Endoscopic Ultrasound (EUS) multi-attribute annotated dataset from five centers, and test it on medical VQA datasets. Experimental results demonstrate the superiority of our approach over existing methods. Our codes and pre-trained models are available at https://anonymous.4open.science/r/Tri_VQA.
MDA: An Interpretable Multi-Modal Fusion with Missing Modalities and Intrinsic Noise
Jun 15, 2024


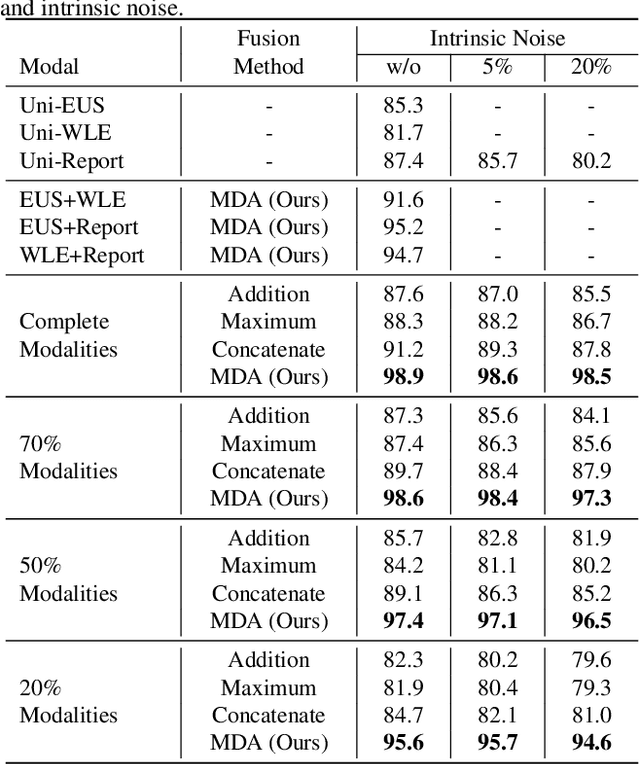
Multi-modal fusion is crucial in medical data research, enabling a comprehensive understanding of diseases and improving diagnostic performance by combining diverse modalities. However, multi-modal fusion faces challenges, including capturing interactions between modalities, addressing missing modalities, handling erroneous modal information, and ensuring interpretability. Many existing researchers tend to design different solutions for these problems, often overlooking the commonalities among them. This paper proposes a novel multi-modal fusion framework that achieves adaptive adjustment over the weights of each modality by introducing the Modal-Domain Attention (MDA). It aims to facilitate the fusion of multi-modal information while allowing for the inclusion of missing modalities or intrinsic noise, thereby enhancing the representation of multi-modal data. We provide visualizations of accuracy changes and MDA weights by observing the process of modal fusion, offering a comprehensive analysis of its interpretability. Extensive experiments on various gastrointestinal disease benchmarks, the proposed MDA maintains high accuracy even in the presence of missing modalities and intrinsic noise. One thing worth mentioning is that the visualization of MDA is highly consistent with the conclusions of existing clinical studies on the dependence of different diseases on various modalities. Code and dataset will be made available.