 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Trajectories: Unlocking the Intrinsic Generative Optimality of Diffusion Models via Graph-Theoretic Planning
Mar 16, 2026Diffusion models operate in a reflexive System 1 mode, constrained by a fixed, content-agnostic sampling schedule. This rigidity arises from the curse of state dimensionality, where the combinatorial explosion of possible states in the high-dimensional noise manifold renders explicit trajectory planning intractable and leads to systematic computational misallocation. To address this, we introduce Chain-of-Trajectories (CoTj), a train-free framework enabling System 2 deliberative planning. Central to CoTj is Diffusion DNA, a low-dimensional signature that quantifies per-stage denoising difficulty and serves as a proxy for the high-dimensional state space, allowing us to reformulate sampling as graph planning on a directed acyclic graph. Through a Predict-Plan-Execute paradigm, CoTj dynamically allocates computational effort to the most challenging generative phases. Experiments across multiple generative models demonstrate that CoTj discovers context-aware trajectories, improving output quality and stability while reducing redundant computation. This work establishes a new foundation for resource-aware, planning-based diffusion modeling. The code is available at https://github.com/UnicomAI/CoTj.
BiTro: Bidirectional Transfer Learning Enhances Bulk and Spatial Transcriptomics Prediction in Cancer Pathological Images
Mar 16, 2026Cancer pathological analysis requires modeling tumor heterogeneity across multiple modalities, primarily through transcriptomics and whole slide imaging (WSI), along with their spatial relations. On one hand, bulk transcriptomics and WSI images are largely available but lack spatial mapping; on the other hand, spatial transcriptomics (ST) data can offer high spatial resolution, yet facing challenges of high cost, low sequencing depth, and limited sample sizes. Therefore, the data foundation of either side is flawed and has its limit in accurately finding the mapping between the two modalities. To this end, we propose BiTro, a bidirectional transfer learning framework that can enhance bulk and spatial transcriptomics prediction from pathological images. Our contributions are twofold. First, we design a universal and transferable model architecture that works for both bulk+WSI and ST data. A major highlight is that we model WSI images on the cellular level to better capture cells' visual features, morphological phenotypes, and their spatial relations; to map cells' features to their transcriptomics measured in bulk or ST, we adopt multiple instance learning. Second, by using LoRA, our model can be efficiently transferred between bulk and ST data to exploit their complementary information. To test our framework, we conducted comprehensive experiments on five cancer datasets. Results demonstrate that 1) our base model can achieve better or competitive performance compared to existing models on bulk or spatial transcriptomics prediction, and 2) transfer learning can further improve the base model's performance.
Step-CoT: Stepwise Visual Chain-of-Thought for Medical Visual Question Answering
Mar 14, 2026Chain-of-thought (CoT) reasoning has advanced medical visual question answering (VQA), yet most existing CoT rationales are free-form and fail to capture the structured reasoning process clinicians actually follow. This work asks: Can traceable, multi-step reasoning supervision improve reasoning accuracy and the interpretability of Medical VQA? To this end, we introduce Step-CoT, a large-scale medical reasoning dataset with expert-curated, structured multi-step CoT aligned to clinical diagnostic workflows, implicitly grounding the model's reasoning in radiographic evidence. Step-CoT comprises more than 10K real clinical cases and 70K VQA pairs organized around diagnostic workflows, providing supervised intermediate steps that guide models to follow valid reasoning trajectories. To effectively learn from Step-CoT, we further introduce a teacher-student framework with a dynamic graph-structured focusing mechanism that prioritizes diagnostically informative steps while filtering out less relevant contexts. Our experiments show that using Step-CoT can improve reasoning accuracy and interpretability. Benchmark: github.com/hahaha111111/Step-CoT. Dataset Card: huggingface.co/datasets/fl-15o/Step-CoT
Generative Regression for Left Ventricular Ejection Fraction Estimation from Echocardiography Video
Feb 09, 2026Estimating Left Ventricular Ejection Fraction (LVEF) from echocardiograms constitutes an ill-posed inverse problem. Inherent noise, artifacts, and limited viewing angles introduce ambiguity, where a single video sequence may map not to a unique ground truth, but rather to a distribution of plausible physiological values. Prevailing deep learning approaches typically formulate this task as a standard regression problem that minimizes the Mean Squared Error (MSE). However, this paradigm compels the model to learn the conditional expectation, which may yield misleading predictions when the underlying posterior distribution is multimodal or heavy-tailed -- a common phenomenon in pathological scenarios. In this paper, we investigate the paradigm shift from deterministic regression toward generative regression. We propose the Multimodal Conditional Score-based Diffusion model for Regression (MCSDR), a probabilistic framework designed to model the continuous posterior distribution of LVEF conditioned on echocardiogram videos and patient demographic attribute priors. Extensive experiments conducted on the EchoNet-Dynamic, EchoNet-Pediatric, and CAMUS datasets demonstrate that MCSDR achieves state-of-the-art performance. Notably, qualitative analysis reveals that the generation trajectories of our model exhibit distinct behaviors in cases characterized by high noise or significant physiological variability, thereby offering a novel layer of interpretability for AI-aided diagnosis.
Bagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
From Failures to Fixes: LLM-Driven Scenario Repair for Self-Evolving Autonomous Driving
May 28, 2025Ensuring robust and generalizable autonomous driving requires not only broad scenario coverage but also efficient repair of failure cases, particularly those related to challenging and safety-critical scenarios. However, existing scenario generation and selection methods often lack adaptivity and semantic relevance, limiting their impact on performance improvement. In this paper, we propose \textbf{SERA}, an LLM-powered framework that enables autonomous driving systems to self-evolve by repairing failure cases through targeted scenario recommendation. By analyzing performance logs, SERA identifies failure patterns and dynamically retrieves semantically aligned scenarios from a structured bank. An LLM-based reflection mechanism further refines these recommendations to maximize relevance and diversity. The selected scenarios are used for few-shot fine-tuning, enabling targeted adaptation with minimal data. Experiments on the benchmark show that SERA consistently improves key metrics across multiple autonomous driving baselines, demonstrating its effectiveness and generalizability under safety-critical conditions.
BR-ASR: Efficient and Scalable Bias Retrieval Framework for Contextual Biasing ASR in Speech LLM
May 25, 2025While speech large language models (SpeechLLMs) have advanced standard automatic speech recognition (ASR), contextual biasing for named entities and rare words remains challenging, especially at scale. To address this, we propose BR-ASR: a Bias Retrieval framework for large-scale contextual biasing (up to 200k entries) via two innovations: (1) speech-and-bias contrastive learning to retrieve semantically relevant candidates; (2) dynamic curriculum learning that mitigates homophone confusion which negatively impacts the final performance. The is a general framework that allows seamless integration of the retrieved candidates into diverse ASR systems without fine-tuning. Experiments on LibriSpeech test-clean/-other achieve state-of-the-art (SOTA) biased word error rates (B-WER) of 2.8%/7.1% with 2000 bias words, delivering 45% relative improvement over prior methods. BR-ASR also demonstrates high scalability: when expanding the bias list to 200k where traditional methods generally fail, it induces only 0.3 / 2.9% absolute WER / B-WER degradation with a 99.99% pruning rate and only 20ms latency per query on test-other.
RepFace: Refining Closed-Set Noise with Progressive Label Correction for Face Recognition
Dec 16, 2024Face recognition has made remarkable strides, driven by the expanding scale of datasets, advancements in various backbone and discriminative losses. However, face recognition performance is heavily affected by the label noise, especially closed-set noise. While numerous studies have focused on handling label noise, addressing closed-set noise still poses challenges. This paper identifies this challenge as training isn't robust to noise at the early-stage training, and necessitating an appropriate learning strategy for samples with low confidence, which are often misclassified as closed-set noise in later training phases. To address these issues, we propose a new framework to stabilize the training at early stages and split the samples into clean, ambiguous and noisy groups which are devised with separate training strategies. Initially, we employ generated auxiliary closed-set noisy samples to enable the model to identify noisy data at the early stages of training. Subsequently, we introduce how samples are split into clean, ambiguous and noisy groups by their similarity to the positive and nearest negative centers. Then we perform label fusion for ambiguous samples by incorporating accumulated model predictions. Finally, we apply label smoothing within the closed set, adjusting the label to a point between the nearest negative class and the initially assigned label. Extensive experiments validate the effectiveness of our method on mainstream face datasets, achieving state-of-the-art results. The code will be released upon acceptance.
CLIP-based Camera-Agnostic Feature Learning for Intra-camera Person Re-Identification
Sep 29, 2024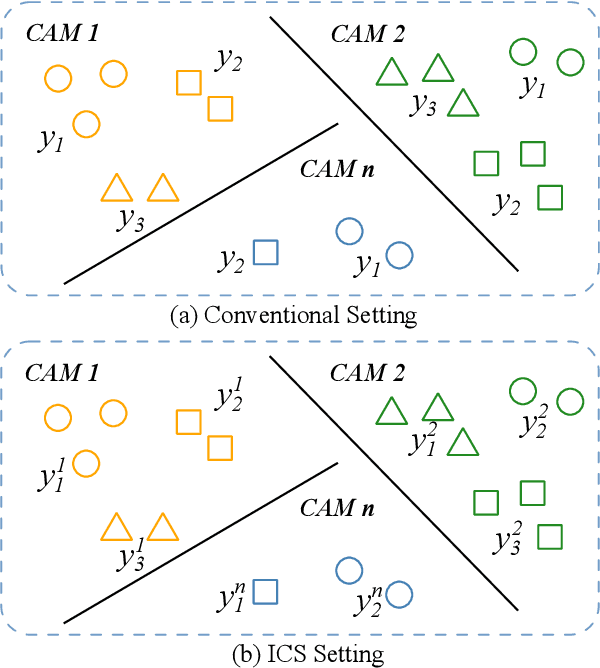
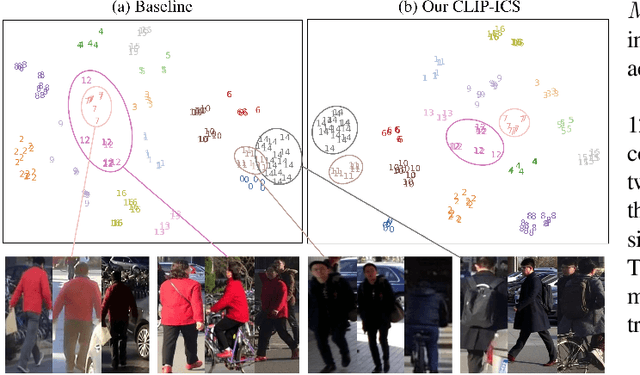
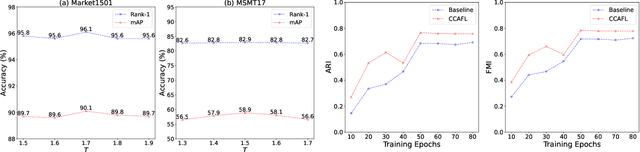
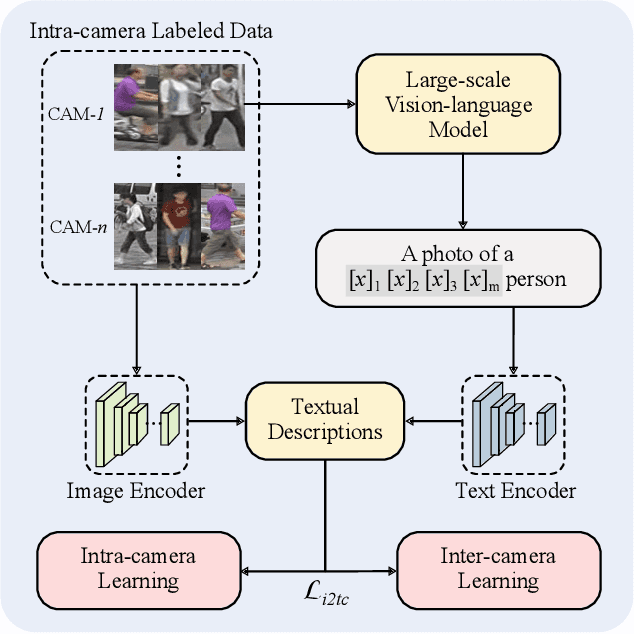
Contrastive Language-Image Pre-Training (CLIP) model excels in traditional person re-identification (ReID) tasks due to its inherent advantage in generating textual descriptions for pedestrian images. However, applying CLIP directly to intra-camera supervised person re-identification (ICS ReID) presents challenges. ICS ReID requires independent identity labeling within each camera, without associations across cameras. This limits the effectiveness of text-based enhancements. To address this, we propose a novel framework called CLIP-based Camera-Agnostic Feature Learning (CCAFL) for ICS ReID. Accordingly, two custom modules are designed to guide the model to actively learn camera-agnostic pedestrian features: Intra-Camera Discriminative Learning (ICDL) and Inter-Camera Adversarial Learning (ICAL). Specifically, we first establish learnable textual prompts for intra-camera pedestrian images to obtain crucial semantic supervision signals for subsequent intra- and inter-camera learning. Then, we design ICDL to increase inter-class variation by considering the hard positive and hard negative samples within each camera, thereby learning intra-camera finer-grained pedestrian features. Additionally, we propose ICAL to reduce inter-camera pedestrian feature discrepancies by penalizing the model's ability to predict the camera from which a pedestrian image originates, thus enhancing the model's capability to recognize pedestrians from different viewpoints. Extensive experiments on popular ReID datasets demonstrate the effectiveness of our approach. Especially, on the challenging MSMT17 dataset, we arrive at 58.9\% in terms of mAP accuracy, surpassing state-of-the-art methods by 7.6\%. Code will be available at: https://github.com/Trangle12/CCAFL.
LCE: A Framework for Explainability of DNNs for Ultrasound Image Based on Concept Discovery
Aug 19, 2024



Explaining the decisions of Deep Neural Networks (DNNs) for medical images has become increasingly important. Existing attribution methods have difficulty explaining the meaning of pixels while existing concept-based methods are limited by additional annotations or specific model structures that are difficult to apply to ultrasound images. In this paper, we propose the Lesion Concept Explainer (LCE) framework, which combines attribution methods with concept-based methods. We introduce the Segment Anything Model (SAM), fine-tuned on a large number of medical images, for concept discovery to enable a meaningful explanation of ultrasound image DNNs. The proposed framework is evaluated in terms of both faithfulness and understandability. We point out deficiencies in the popular faithfulness evaluation metrics and propose a new evaluation metric. Our evaluation of public and private breast ultrasound datasets (BUSI and FG-US-B) shows that LCE performs well compared to commonly-used explainability methods. Finally, we also validate that LCE can consistently provide reliable explanations for more meaningful fine-grained diagnostic tasks in breast ultrasound.